VLA
Vision-Language-Action Models (VLA)
VLA Overview
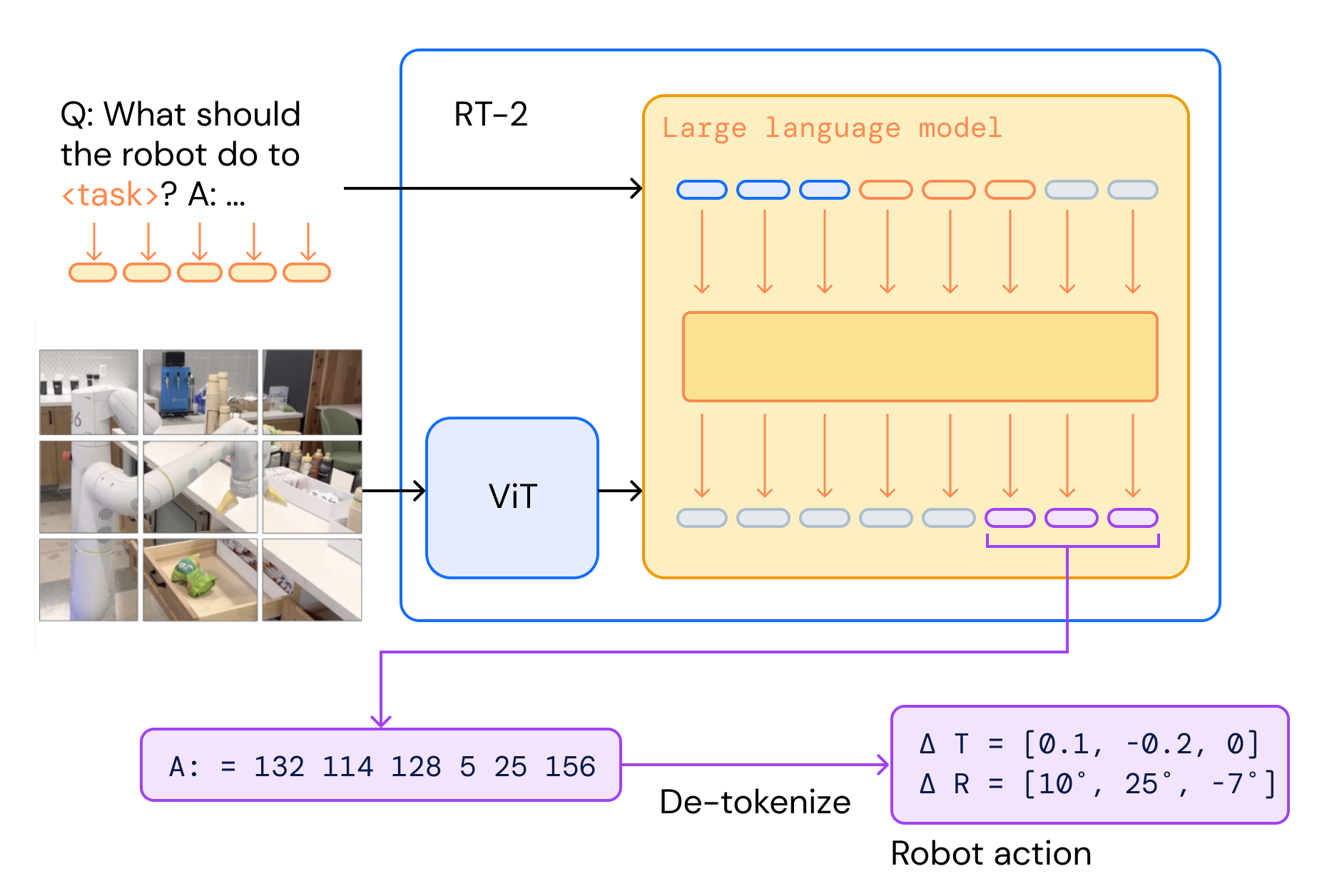
RT-2 from Google
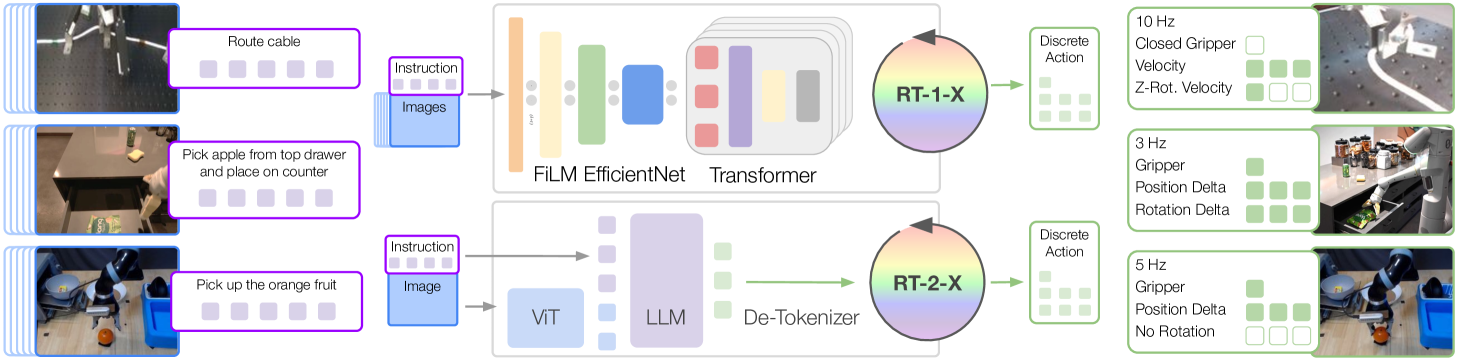
Octo from UC-Berkeley
![]()
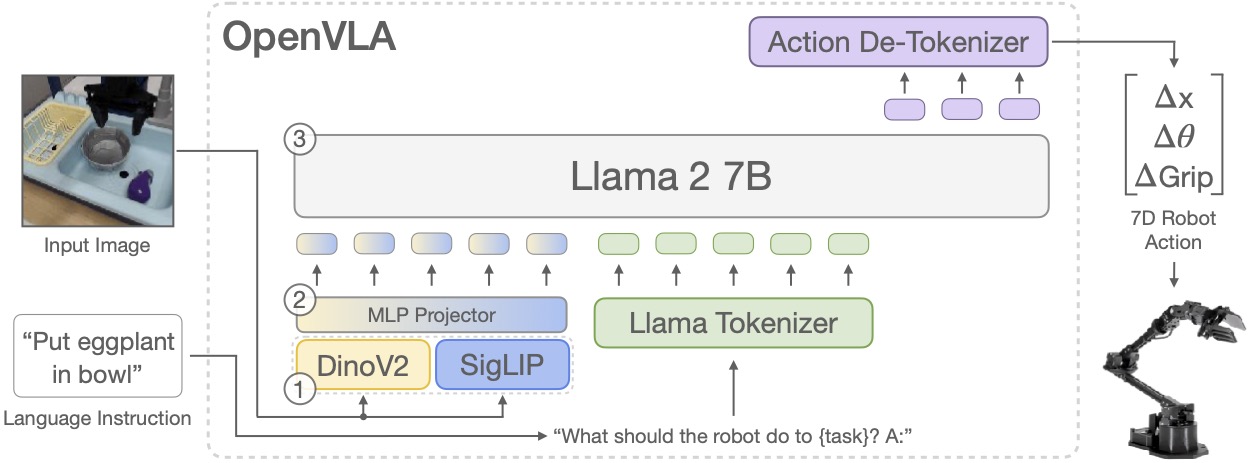
OpenVLA from Stanford
QUART-VLA from MiLAB

ALOHA from Google-DeepMind

π0: Physical Intelligence

Helix by Figure AI

GR00T N1 from Nvidia

Gemini Robotics

VLA Research
BridgeData V2
Paper: BridgeData V2: A Dataset for Robot Learning at Scale
Code: https://github.com/rail-berkeley/bridge_data_v2
Open X-Embodiment
Paper: Open X-Embodiment: Robotic Learning Datasets and RT-X Models
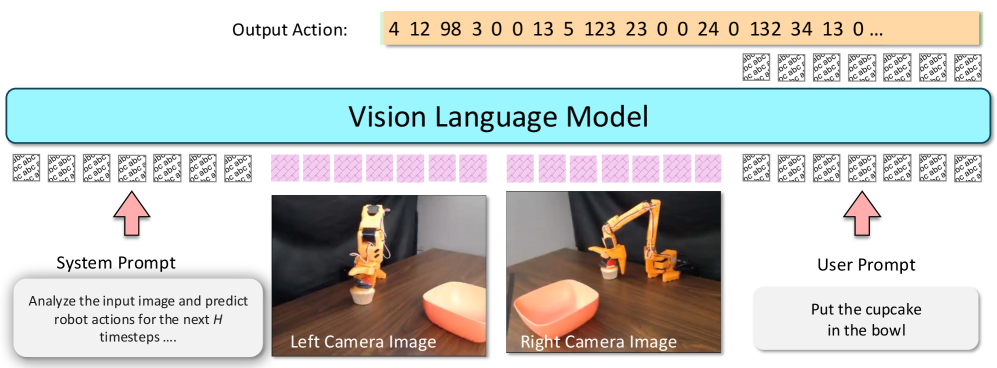
QUAR-VLA
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots

OpenVLA
Paper: OpenVLA: An Open-Source Vision-Language-Action Model
Code: https://github.com/openvla/openvla
OpenVLA-OFT
Paper: Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Code: https://github.com/moojink/openvla-oft
SimpleVLA-RL
Paper: SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Code: https://github.com/PRIME-RL/SimpleVLA-RL

SmolVLA
Model: lerobot/smolvla_base
Paper: SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics

SO-101 robot
SO-ARM101 AI 機器手臂PRO套件 for LeRobot

VLA-0
Paper: VLA-0: Building State-of-the-Art VLAs with Zero Modification
Code: https://github.com/NVlabs/vla0
- vla0-trl: Minimal VLA-0 Reimplementation with TRL
- VLA-0-Smol: A Reproducible Recipe for High-Performance, Sub-Billion Parameter VLA
QuantVLA
Paper: QuantVLA: Scale-Calibrated Post-Training Quantization for Vision-Language-Action Models

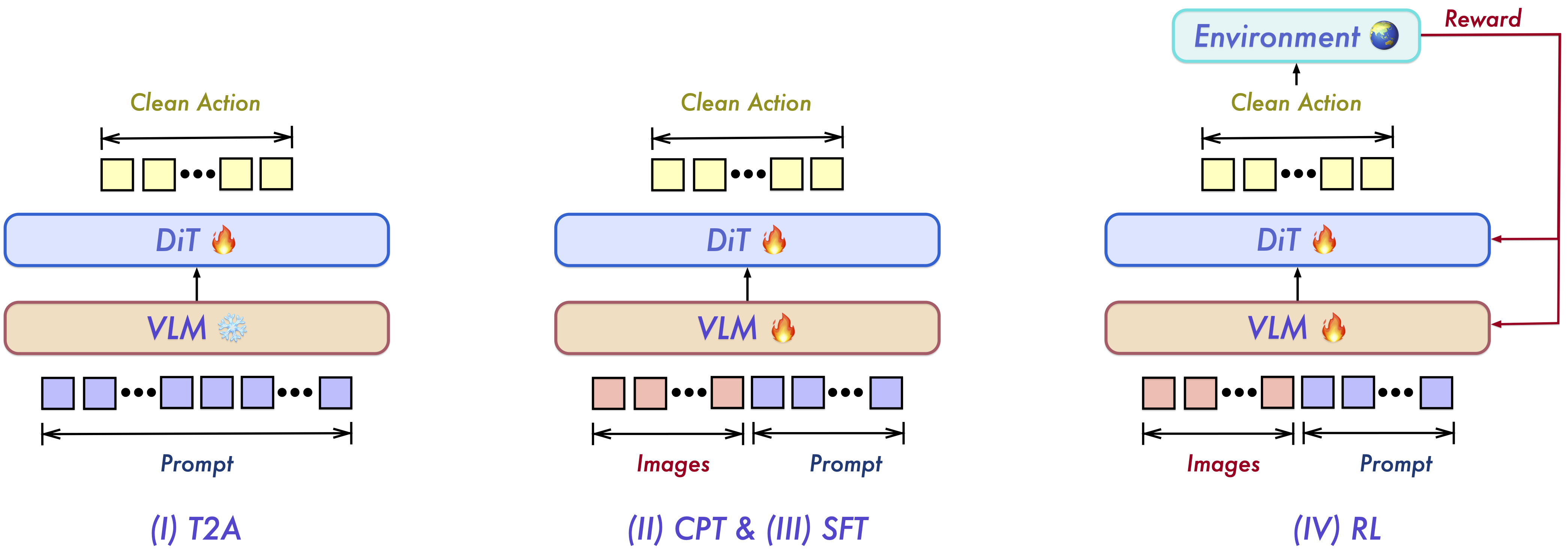
Qwen-VLA
Paper: Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments

Blog: Qwen-VLA: From Understanding the World to Acting in It
Model: Ollama: qwen3-vl
Robot Learning
Paper: Robot Learning: A Tutorial
Code: https://github.com/fracapuano/robot-learning-tutorial
HIL-SERL


Generalist Robot Policies

RLVR-World
Paper: RLVR-World: Training World Models with Reinforcement Learning
Code: https://github.com/thuml/RLVR-World


LeWM
Paper: LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Code: https://github.com/lucas-maes/le-wm

Characteristics of latent world model approaches

LeWorldModel Latent Planning

Agentic Robot
Paper: Agentic Robot: A Brain-Inspired Framework for Vision-Language-Action Models in Embodied Agents
Github:https://github.com/Agentic-Robot/agentic-robot

SAP: Standardized Action Procedure for Coordinated Agentic Control

VLAC
Paper: A Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning
Code: https://github.com/InternRobotics/VLAC

VITRA
Paper: Scalable Vision-Language-Action Model Pretraining forRobotic Manipulation with Real-Life Human Activity Videos
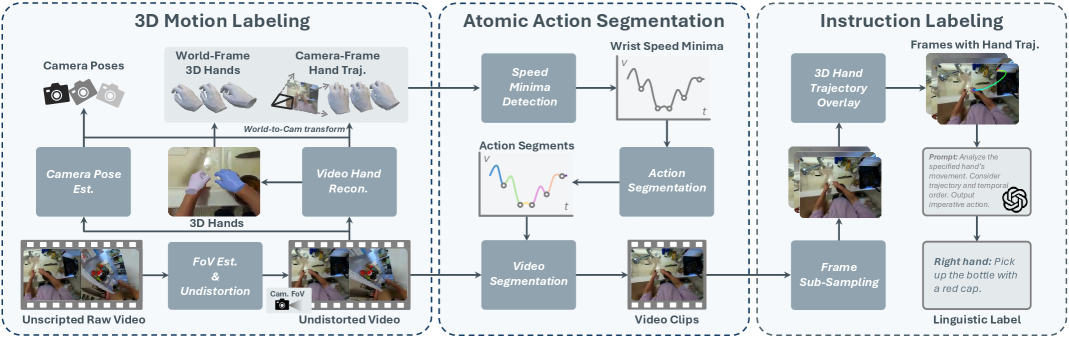
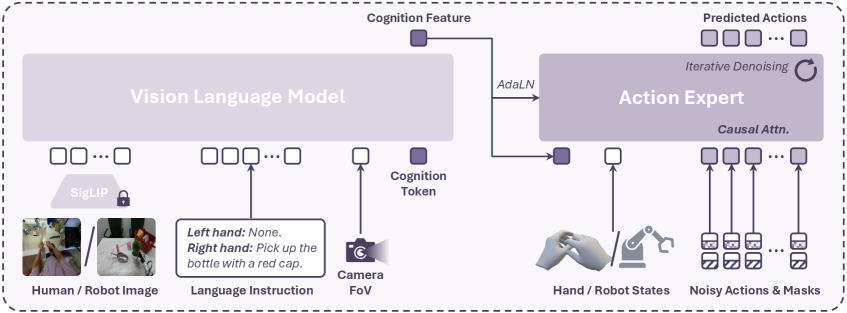
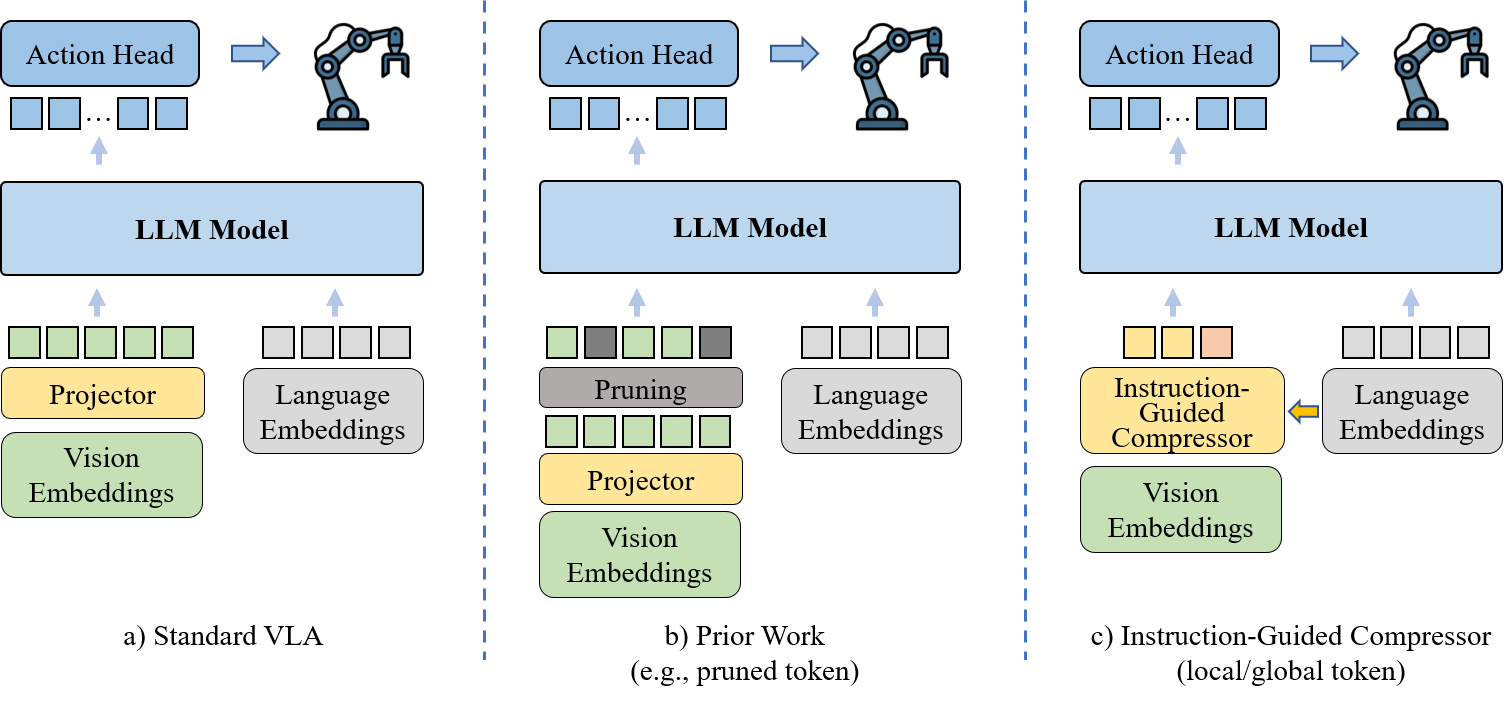
Compressor-VLA
Paper: Compressor-VLA: Instruction-Guided Visual Token Compression for Efficient Robotic Manipulation
ACoT-VLA
Paper: ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
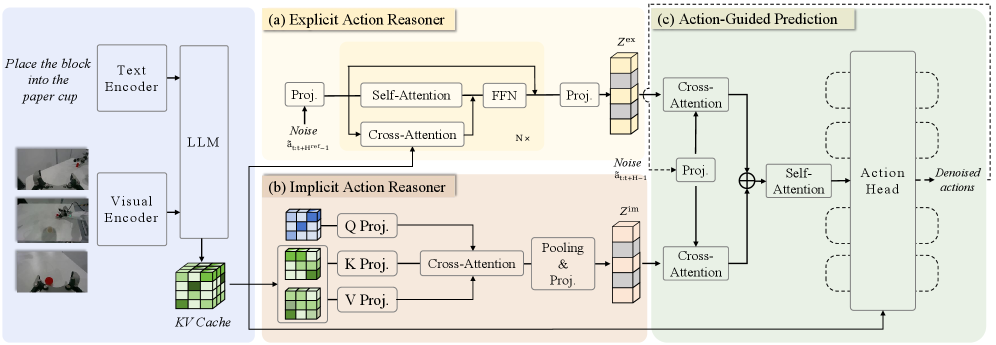
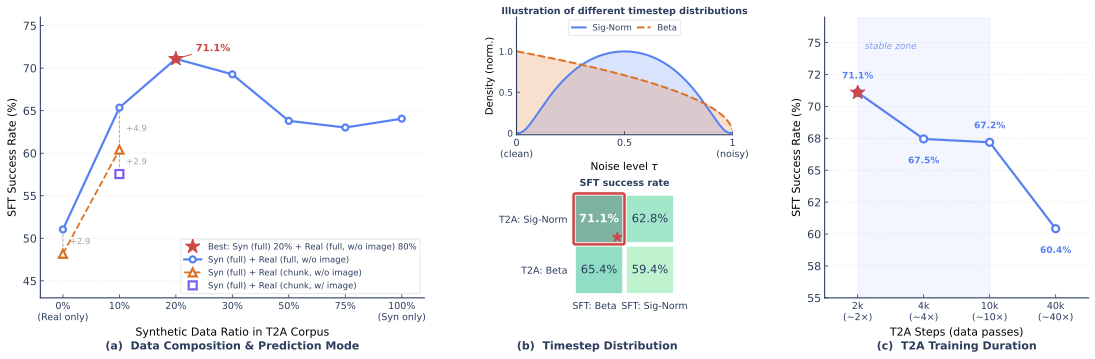
Qwen-VLA
Paper: Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Four-Stage Training
This site was last updated July 09, 2026.