Generative Video
李宏毅_生成式導論 2024
李宏毅_生成式導論 2024_第17講:有關影像的生成式AI (上) — AI 如何產生圖片和影片 (Sora 背後可能用的原理)
李宏毅_生成式導論 2024_第18講:有關影像的生成式AI (下) — 快速導讀經典影像生成方法 (VAE, Flow, Diffusion, GAN) 以及與生成的影片互動
Open-VCLIP
Paper: Open-VCLIP: Transforming CLIP to an Open-vocabulary Video Model via Interpolated Weight Optimization
Paper: Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Code: https://github.com/wengzejia1/Open-VCLIP/

Text-to-Video

Awesome Video Diffusion Models
AnimateDiff
Paper: AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Code: https://github.com/guoyww/AnimateDiff

Stable Diffusion Video
Paper: Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Code: https://github.com/nateraw/stable-diffusion-videos

Animate Anyone
Paper: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation


StyleCrafter
Paper: StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
Code: https://github.com/GongyeLiu/StyleCrafter

Sora
Paper: Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models

Outfit Anyone
Paper: OutfitAnyone: Ultra-high Quality Virtual Try-On for Any Clothing and Any Person
Code: https://github.com/HumanAIGC/OutfitAnyone
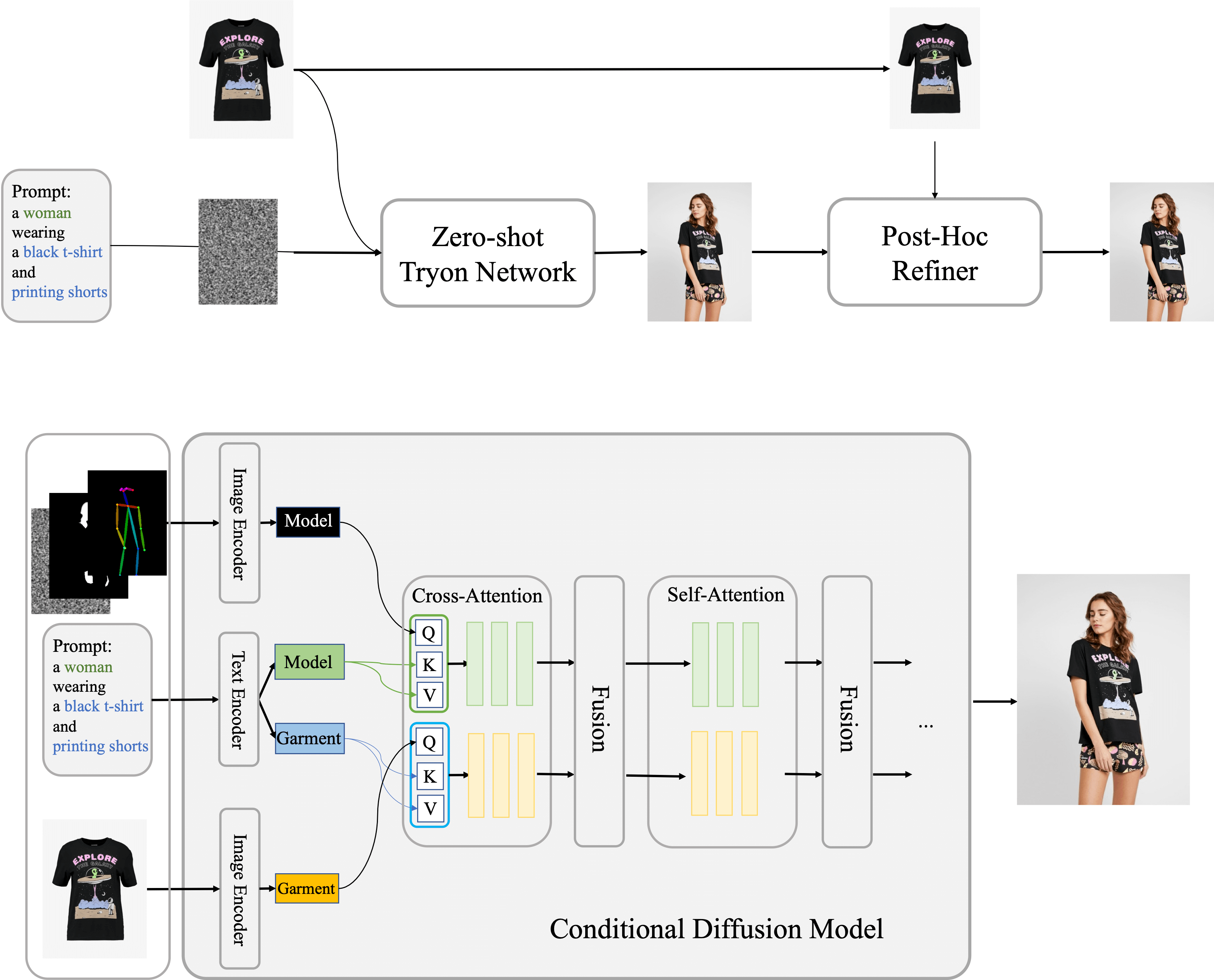
LTX-Video
Paper: LTX-Video: Realtime Video Latent Diffusion

![]()
Open-Sora
Paper: Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Code: https://github.com/hpcaitech/Open-Sora


Step-Video-TI2V
Paper: Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Code: https://github.com/stepfun-ai/Step-Video-TI2V

WAN 2.2
Paper: Wan: Open and Advanced Large-Scale Video Generative Models
Code: https://github.com/Wan-Video/Wan2.2
ComfyUI + WAN2.2
Multi-Talk
Paper: Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
Code: https://github.com/MeiGen-AI/MultiTalk

InfiniteTalk
Paper: InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Code: https://github.com/MeiGen-AI/InfiniteTalk

Wan-S2V
HuggingFace: Wan-AI/Wan2.2-S2V-14B
Paper: Wan-S2V: Audio-Driven Cinematic Video Generation
UniVerse-1
Paper: UniVerse-1: Unified Audio-Video Generation via Stitching of Experts
Code: https://github.com/Dorniwang/UniVerse-1-code/

Wan-Animate
Paper: Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
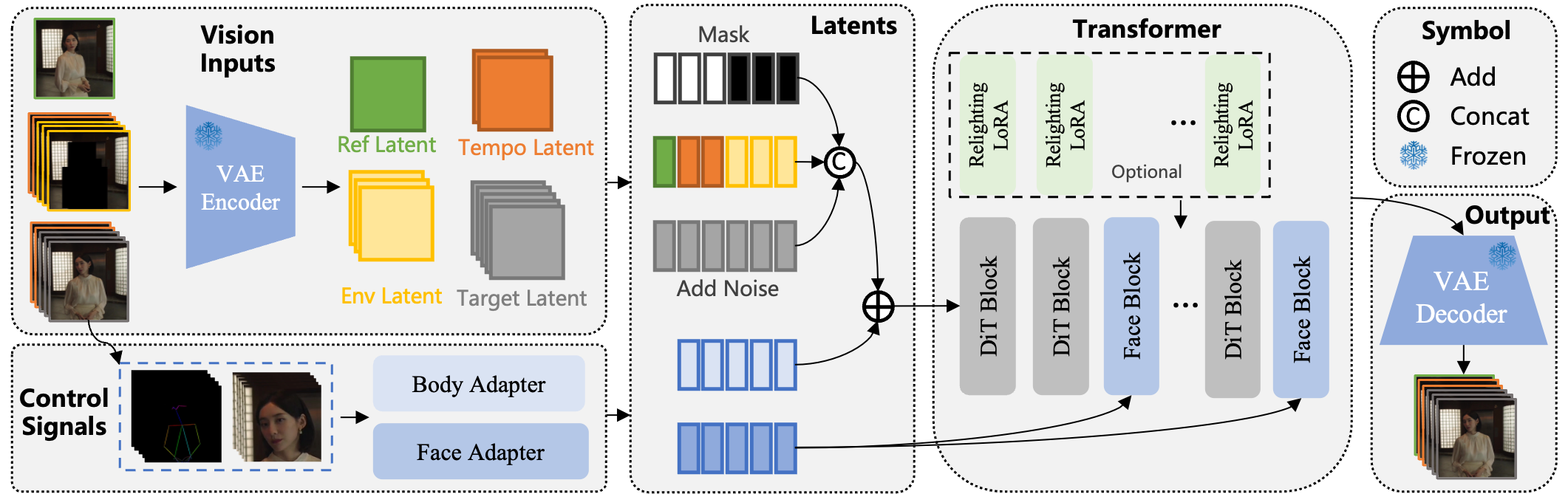
VEO 3
Paper: Video models are zero-shot learners and reasoners
FlashVSR
Paper: FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution
Code: https://github.com/OpenImagingLab/FlashVSR

TiDAR
TiDAR: Think in Diffusion, Talk in Autoregression

DiffusionVL
DiffusionVL: Translating Any Autoregressive Models into Diffusion Vision Language Models


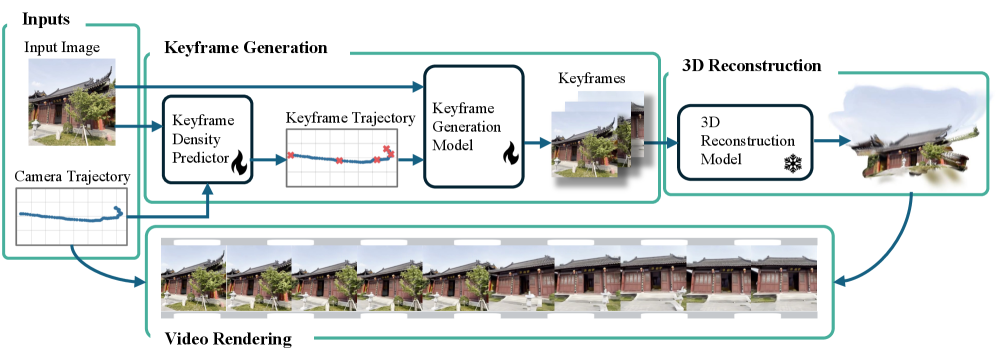
SRENDER
Paper: Efficient Camera-Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering

LTX-2
Paper: LTX-2: Efficient Joint Audio-Visual Foundation Model

daVinci-MagiHuman
Paper: Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Code: https://github.com/GAIR-NLP/daVinci-MagiHuman


Runway
GWM-1
Gen-4.5
Kling
Paper: Kling-MotionControl Technical Report


SeedDance 2.0
Paper: Seedance 2.0: Advancing Video Generation for World Complexity
LTX-2.3
Blog: Lightricks 發布 LTX 2.3 開源影片生成模型,可在本地端製作 4K 50FPS 同步音訊 AI 影片
JoyAI-Echo
Code: https://github.com/jd-opensource/JoyAI-Echo
ComfyUI_JoyAI_Echo need 48GB VRAM!
SCAIL-2
Paper: SCAIL-2: Unifying Controlled Character Animation with End-to-end In-Context Conditioning


World Models
Phantom
Paper: Phantom: Physics-Infused Video Generation via Joint Modeling of Visual and Latent Physical Dynamics

SANA-WM
Paper: SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
Code: https://github.com/NVlabs/Sana

This site was last updated July 09, 2026.