VLA
Vision-Language-Action models (VLA)
VLA models
Paper: Vision-Language-Action Models: Concepts, Progress, Applications and Challenges




RT-1
Paper: RT-1: Robotics Transformer for Real-World Control at Scale

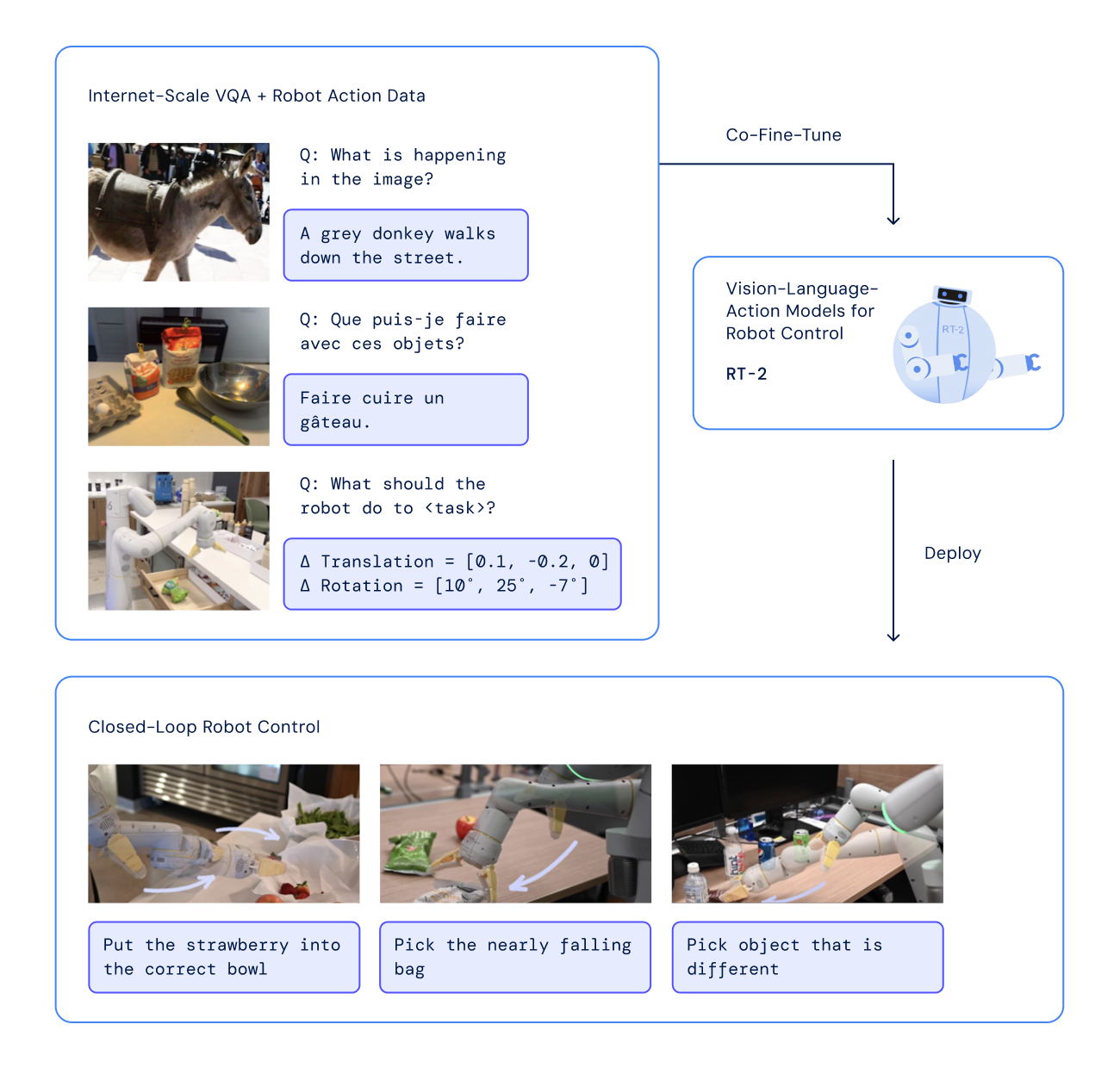
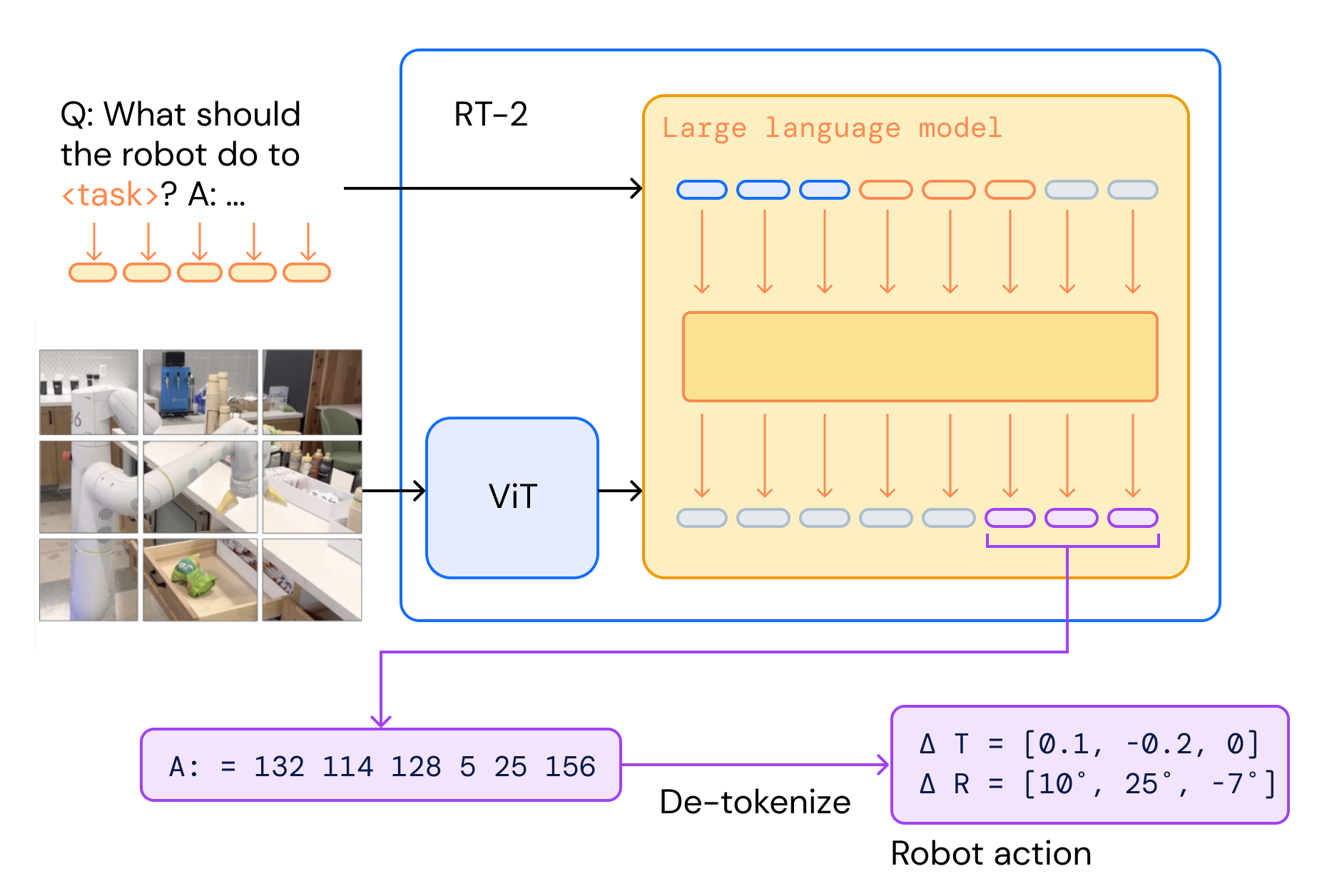
RT-2
Paper: RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
BridgeData V2
Paper: BridgeData V2: A Dataset for Robot Learning at Scale
Code: https://github.com/rail-berkeley/bridge_data_v2
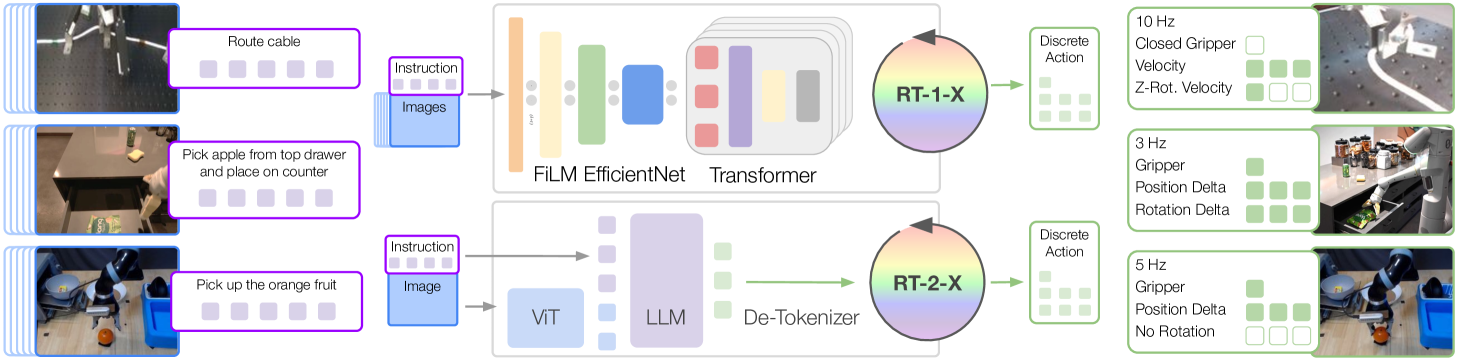
Open X-Embodiment
Paper: Open X-Embodiment: Robotic Learning Datasets and RT-X Models
OpenVLA
Paper: OpenVLA: An Open-Source Vision-Language-Action Model
OpenVLA-OFT
Paper: Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Code: https://github.com/moojink/openvla-oft
SimpleVLA-RL
Paper: SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Code: https://github.com/PRIME-RL/SimpleVLA-RL

SmolVLA
Model: lerobot/smolvla_base
Paper: SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics

SO-101 robot
SO-ARM101 AI 機器手臂PRO套件 for LeRobot

Robot Learning
Paper: Robot Learning: A Tutorial
Code: https://github.com/fracapuano/robot-learning-tutorial
HIL-SERL


Generalist Robot Policies

RLVR-World
Paper: RLVR-World: Training World Models with Reinforcement Learning
Code: https://github.com/thuml/RLVR-World


Agentic Robot
Paper: Agentic Robot: A Brain-Inspired Framework for Vision-Language-Action Models in Embodied Agents
Github:https://github.com/Agentic-Robot/agentic-robot

SAP: Standardized Action Procedure for Coordinated Agentic Control

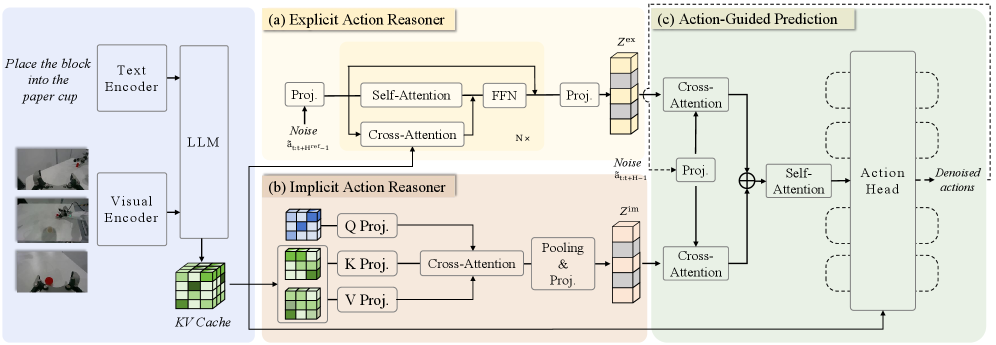
ACoT-VLA
Paper: ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
LeWM
Paper: LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Code: https://github.com/lucas-maes/le-wm

Characteristics of latent world model approaches

LeWorldModel Latent Planning

This site was last updated May 30, 2026.