VLM/MLLMs
MLLM - Multimodal Large Language Model
Paper: A Survey on Multimodal Large Language Models

MLLM papers
VLM - Vision Language Model
Guide to Vision-Language Models (VLMs)
LLM in Vision papers
Contrastive Learning
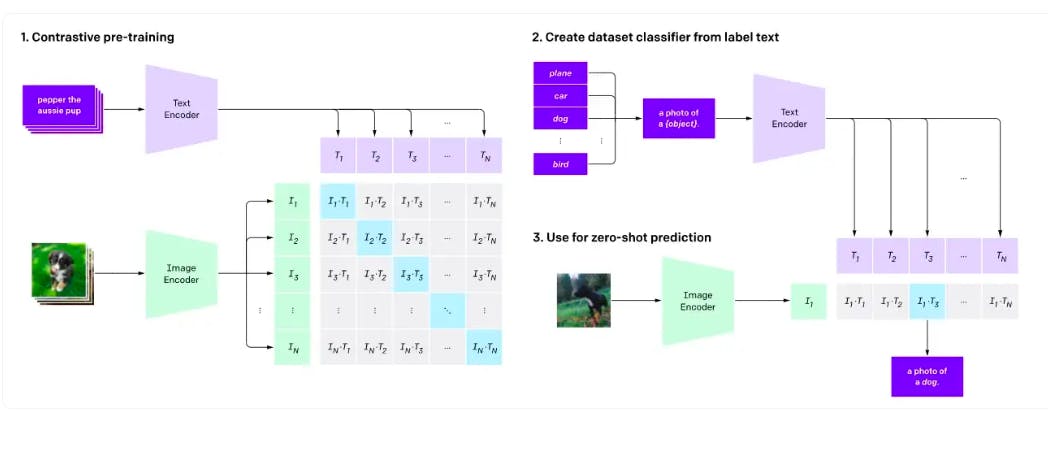
CLIP architecture
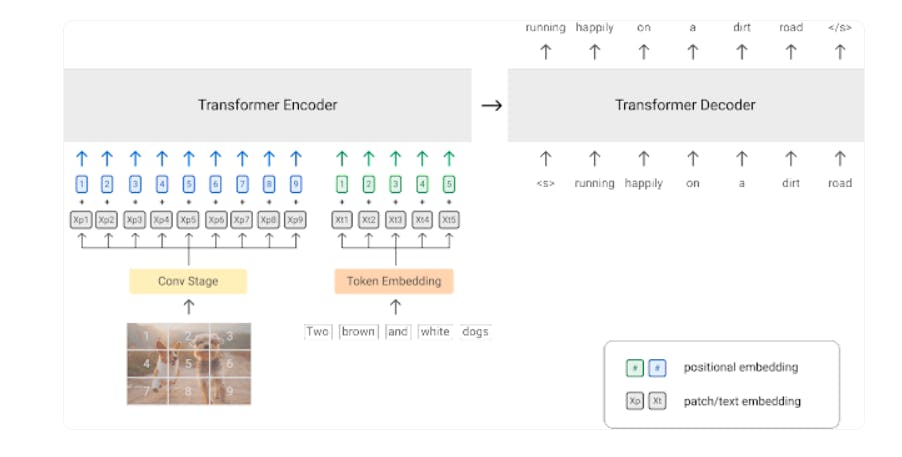
PrefixLM
SimVLM architecture
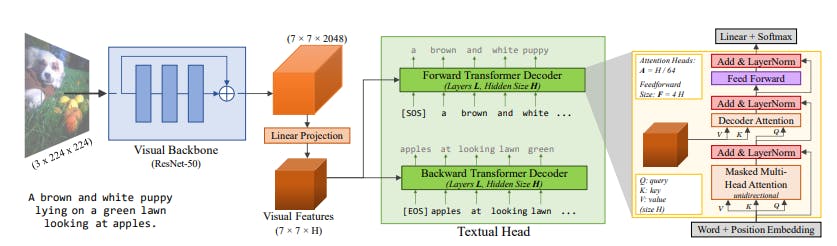
VirTex architecture
Frozen architecture
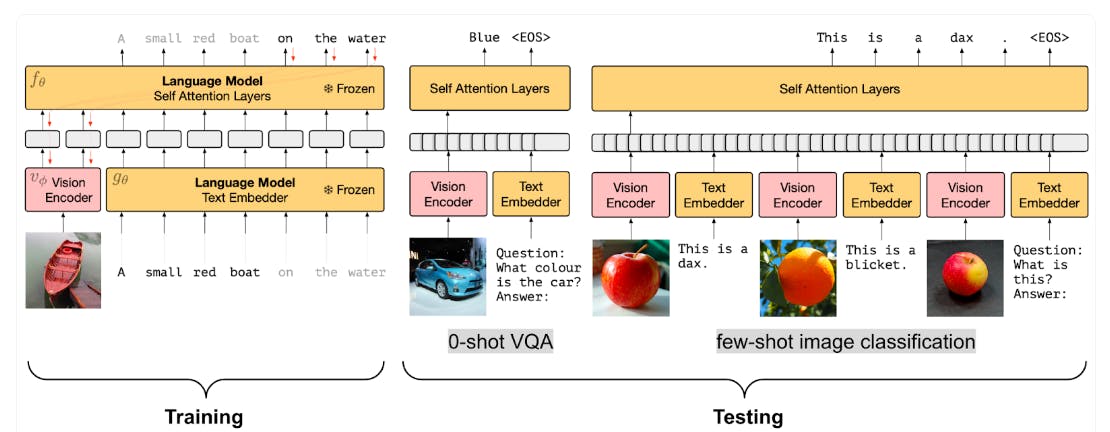
Flamingo architecture
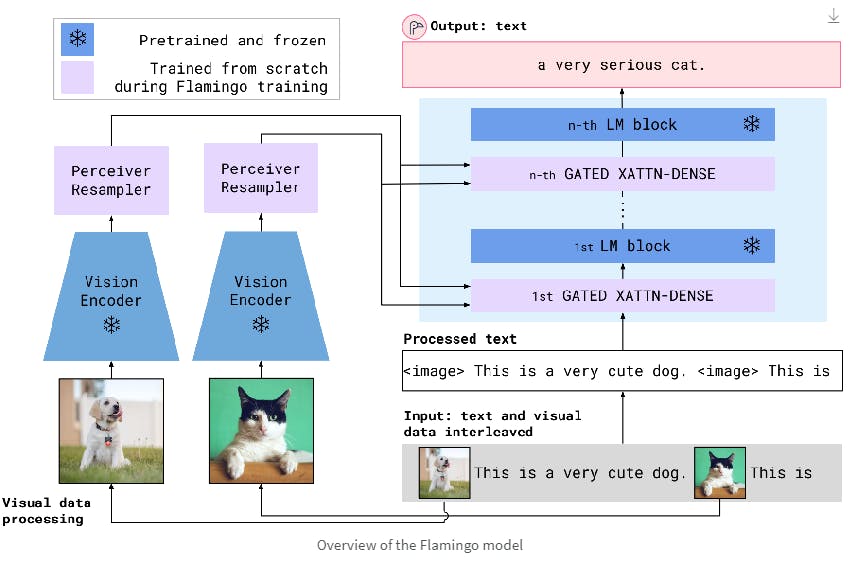
Multimodal Fusing with Cross-Attention
VisualGPT architecture
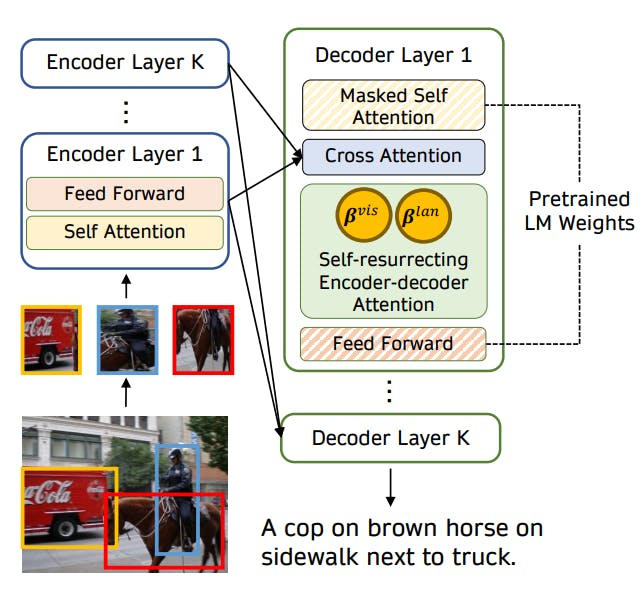
Masked-language Modeling (MLM) & Image-Text Matching (ITM)
VisualBERT architecture
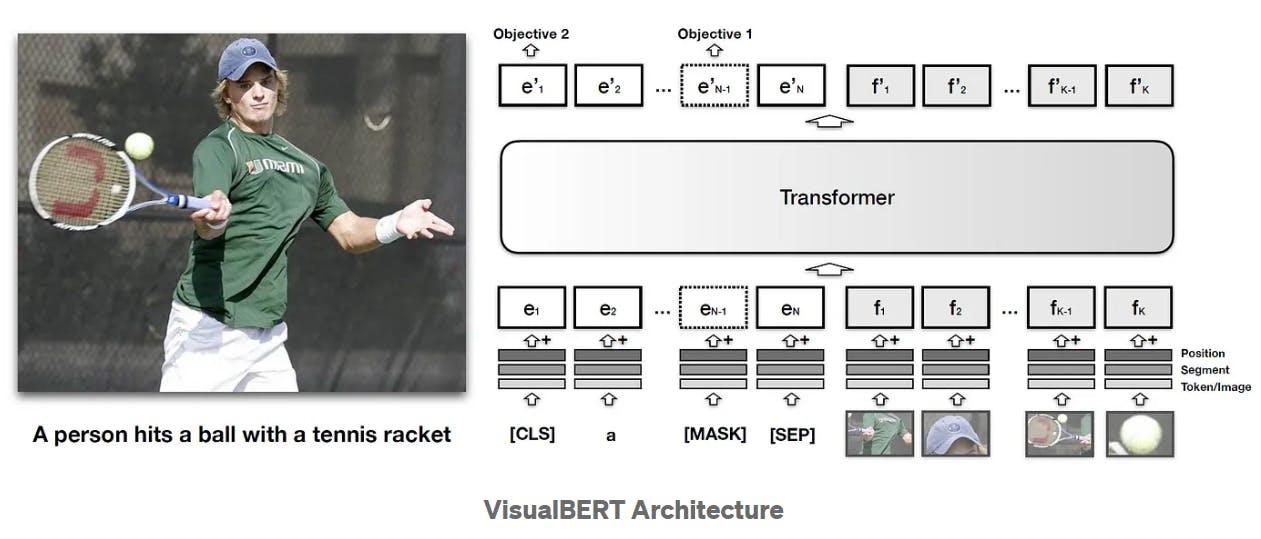
Multimodal AI
Multimodal AI: A Guide to Open-Source Vision Language Models
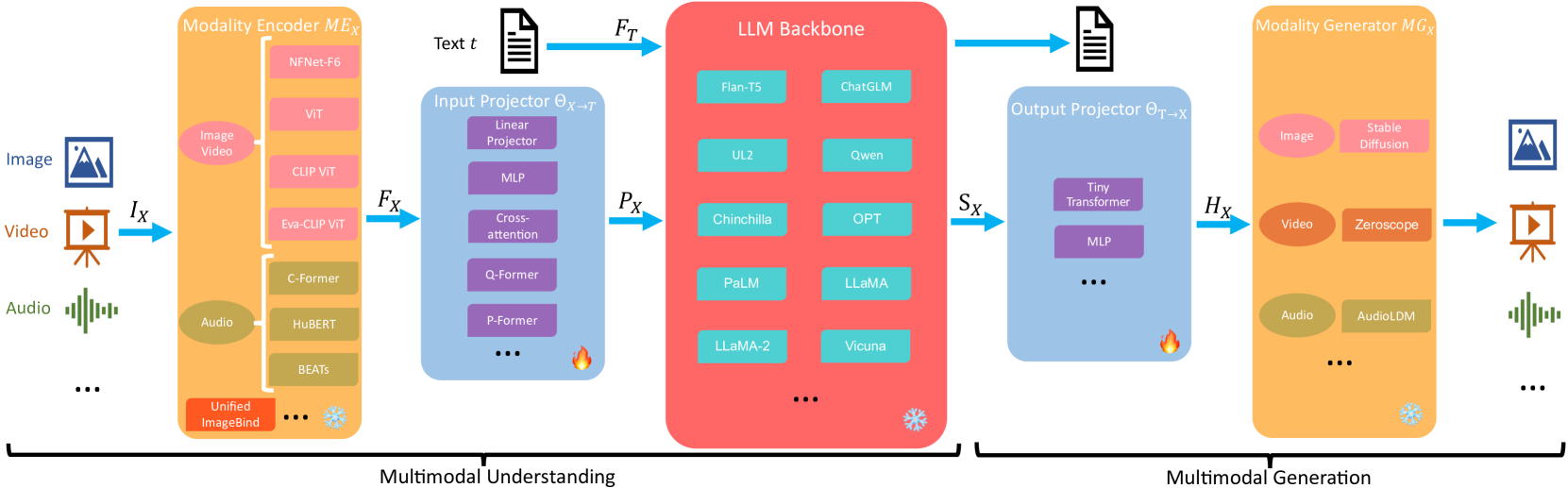
Paper: MM-LLMs: Recent Advances in MultiModal Large Language Models

The general model architecture of MM-LLMs
Gemma 3
Available in 1B, 4B, 12B, and 27B sizes. With a 128K-token context window (32K for 1B).
GLM-4.1V-Thinking
an open-source VLM developed by Z.ai. With just 9 billion parameters and a 64K-token context window.
Llama3.2 Vision
NVLM 1.0
a family of multimodal LLMs developed by NVIDIA
Molmo
Available in 1B, 7B, and 72B parameters
Qwen2.5-VL
Available in 3B, 7B, 32B and 72B parameter sizes and offers strong multimodal performance across vision, language, document parsing, and long video understanding.
Pixtral
PaLM-E
Paper: PaLM-E: An Embodied Multimodal Language Model
Code: https://github.com/kyegomez/PALM-E

LLaVA
Paper: Visual Instruction Tuning
Paper: Improved Baselines with Visual Instruction Tuning
Code: https://github.com/haotian-liu/LLaVA

LLaVA-Med
Paper: LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
Code: https://github.com/microsoft/LLaVA-Med
Qwen-VL
Paper: Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Code: https://github.com/QwenLM/Qwen-VL
LLaVA-Plus
Paper: LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents
Code: https://github.com/LLaVA-VL/LLaVA-Plus-Codebase
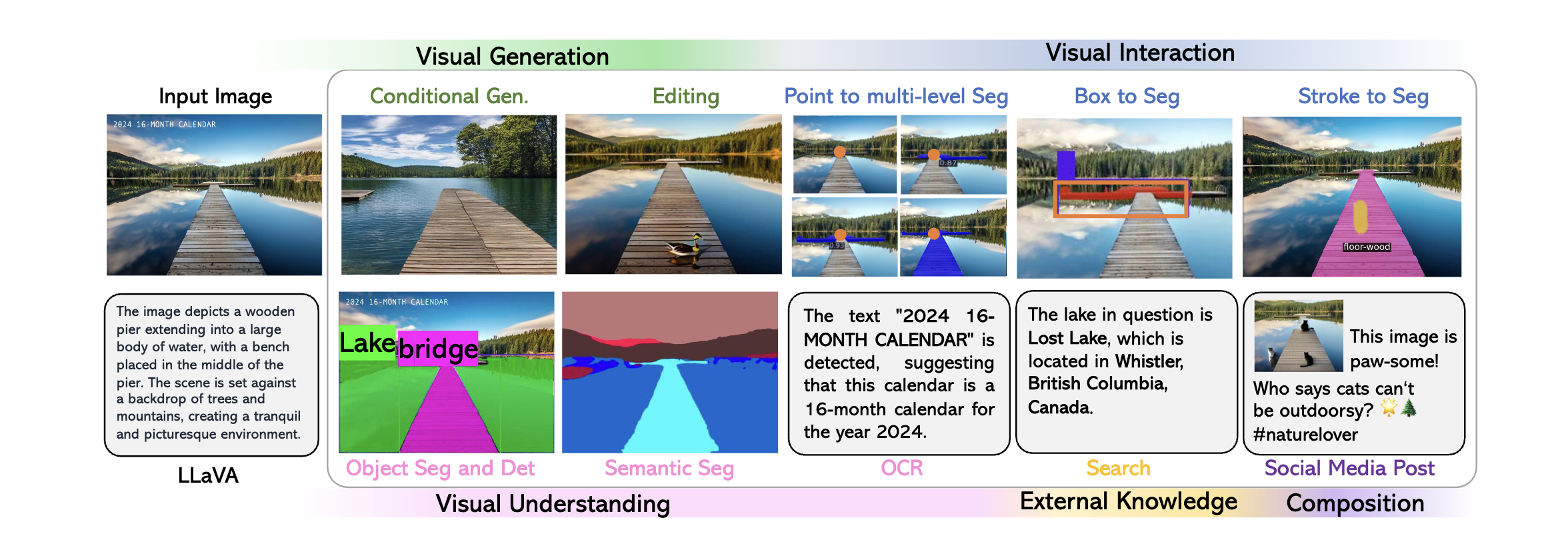

GPT4-V
Paper: Assessing GPT4-V on Structured Reasoning Tasks
Gemini
Paper: Gemini: A Family of Highly Capable Multimodal Models

Yi-VL-34B
HuggineFace: 01-ai/Yi-VL-34B
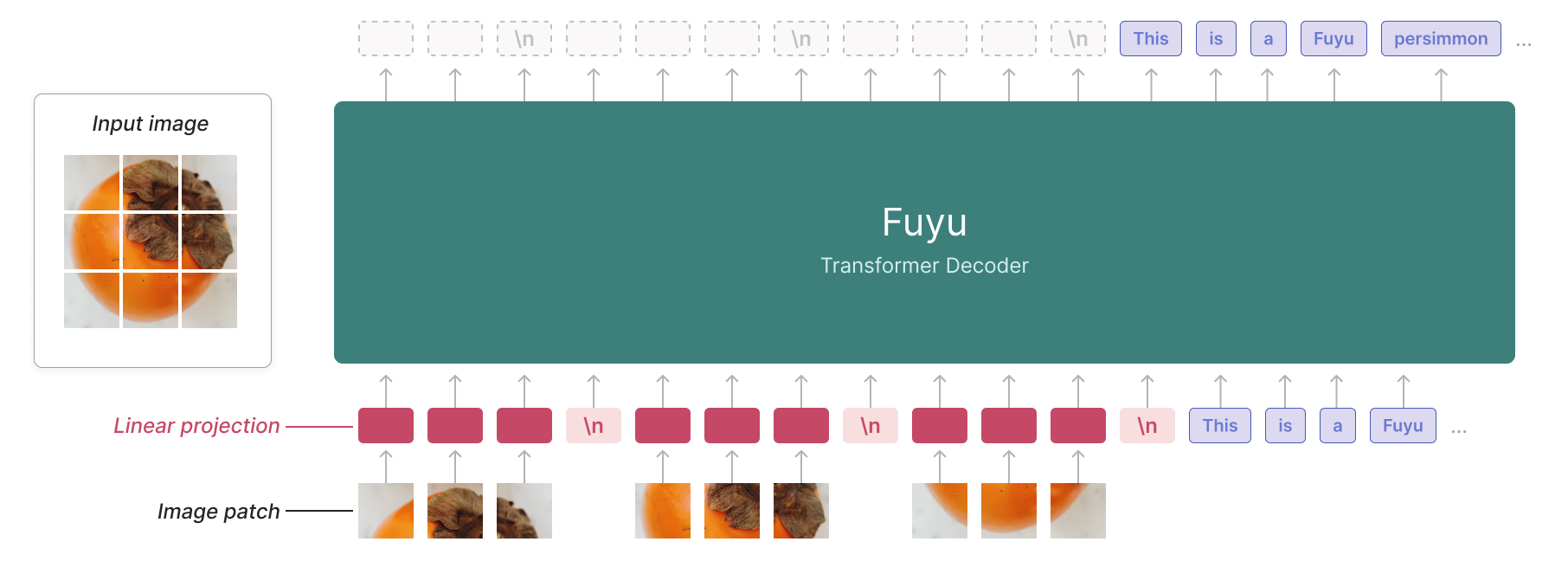
FuYu-8B
Blog: Fuyu-8B: A Multimodal Architecture for AI Agents

LLaVA-NeXT
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
- Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
- Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
- Better visual conversation for more scenarios, covering different applications. Better world knowledge and logical reasoning.
- Efficient deployment and inference with SGLang.
Florence-2
Paper: Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Blog: Florence-2: Advancing Multiple Vision Tasks with a Single VLM Model

VILA
Paper: VILA: On Pre-training for Visual Language Models
Code: https://github.com/Efficient-Large-Model/VILA
VILA on Jetson Orin
VLFeedback and Silkie
Paper: Silkie: Preference Distillation for Large Visual Language Models
Code: https://github.com/vlf-silkie/VLFeedback
MobileVLM
Paper: MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Code: https://github.com/Meituan-AutoML/MobileVLM
MyVLM
Paper: MyVLM: Personalizing VLMs for User-Specific Queries
Code: https://github.com/snap-research/MyVLM


Reka Core
Paper: Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
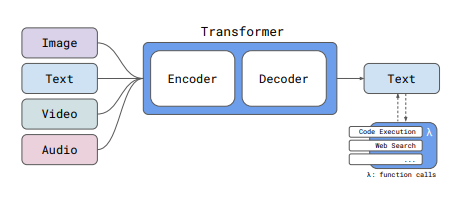

InternLM-XComposer
Code: https://github.com/InternLM/InternLM-XComposer
InternLM-XComposer2-4KHD

MiniCPM-V
Paper: MiniCPM-V: A GPT-4V Level MLLM on Your Phone

SoM
Paper: Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Code: https://github.com/microsoft/SoM

Gemini-1.5
Paper: Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
SoM-LLaVA
Paper: List Items One by One: A New Data Source and Learning Paradigm for Multimodal LLMs
Code: https://github.com/zzxslp/SoM-LLaVA


Phi-3 Vision
Phi-3-vision is a 4.2B parameter multimodal model with language and vision capabilities.
Paper: Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
EVE
Paper: Unveiling Encoder-Free Vision-Language Models

Paligemma
Paper: PaliGemma: A versatile 3B VLM for transfer

CogVLM2
Paper: CogVLM2: Visual Language Models for Image and Video Understanding
Demo
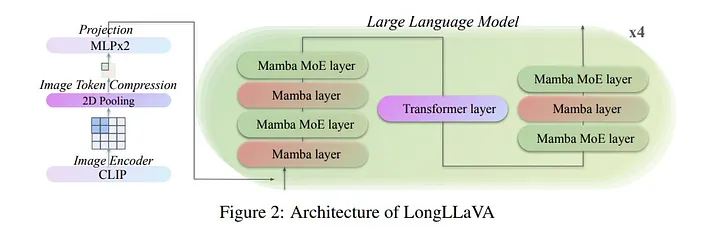
LongLLaVA
Blog: LongLLaVA: Revolutionizing Multi-Modal AI with Hybrid Architecture
Paper**: LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
Code: https://github.com/FreedomIntelligence/LongLLaVA
Phi-3.5-vision
HuggineFace: microsoft/Phi-3.5-vision-instruct
Pixtral
HuggingFace: mistralai/Pixtral-12B-2409
Paper: Pixetral 12B
Qwen-Audio
Paper: Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Code: https://github.com/QwenLM/Qwen-Audio
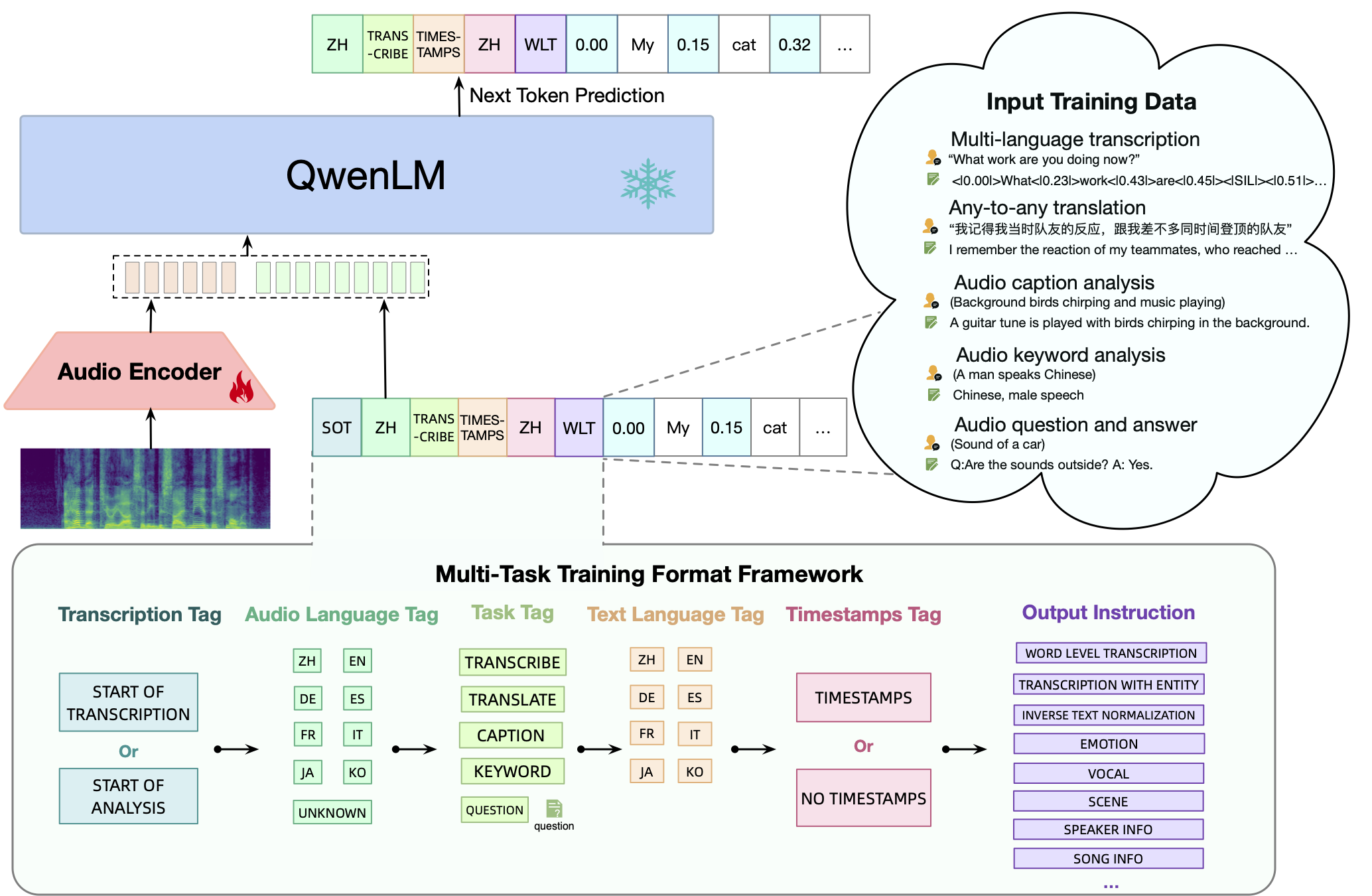
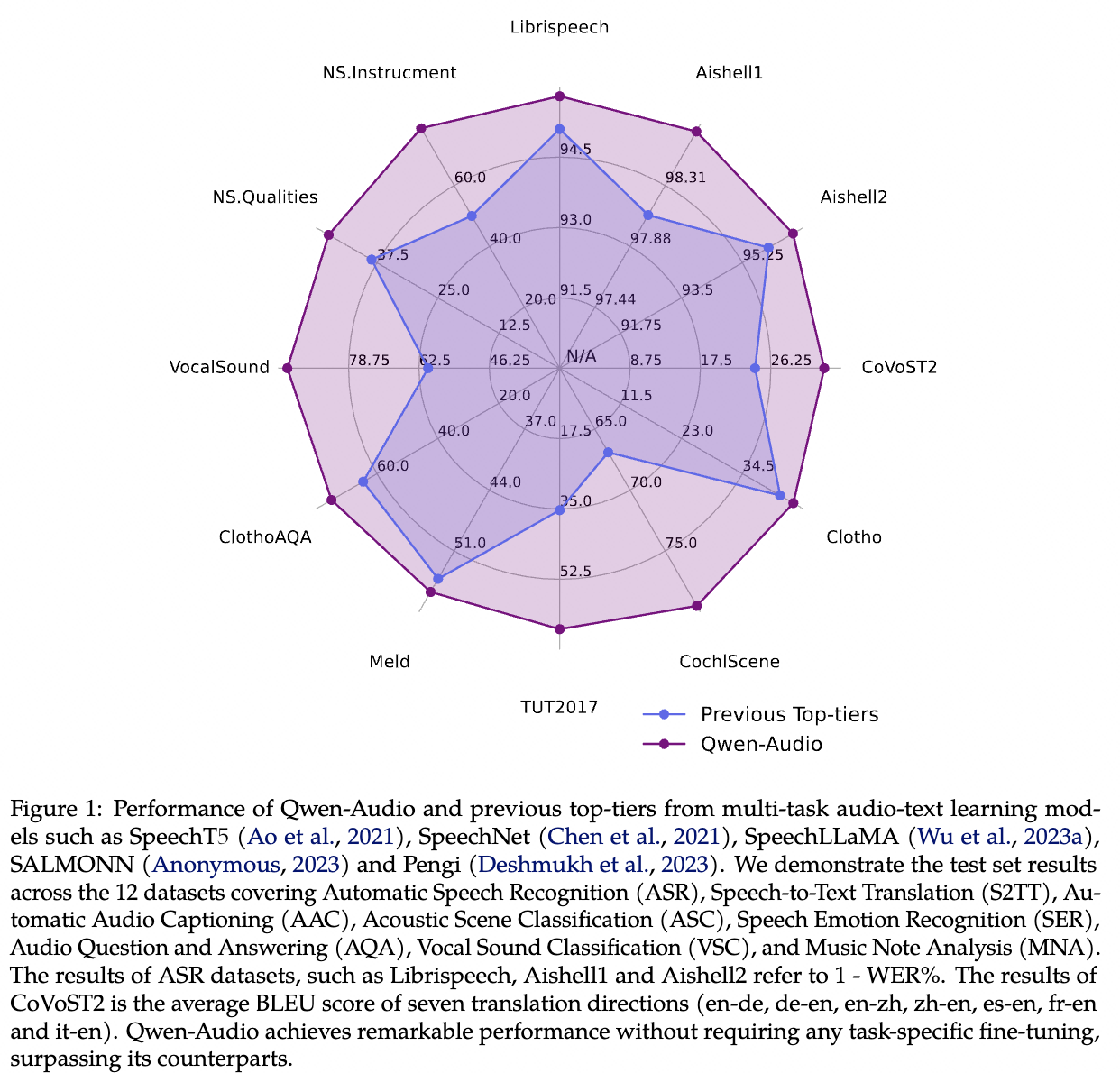
Octopus
Paper: Octopus: Embodied Vision-Language Programmer from Environmental Feedback
Code: https://github.com/dongyh20/Octopus
VLM-R1
VLM-R1: A stable and generalizable R1-style Large Vision-Language Model

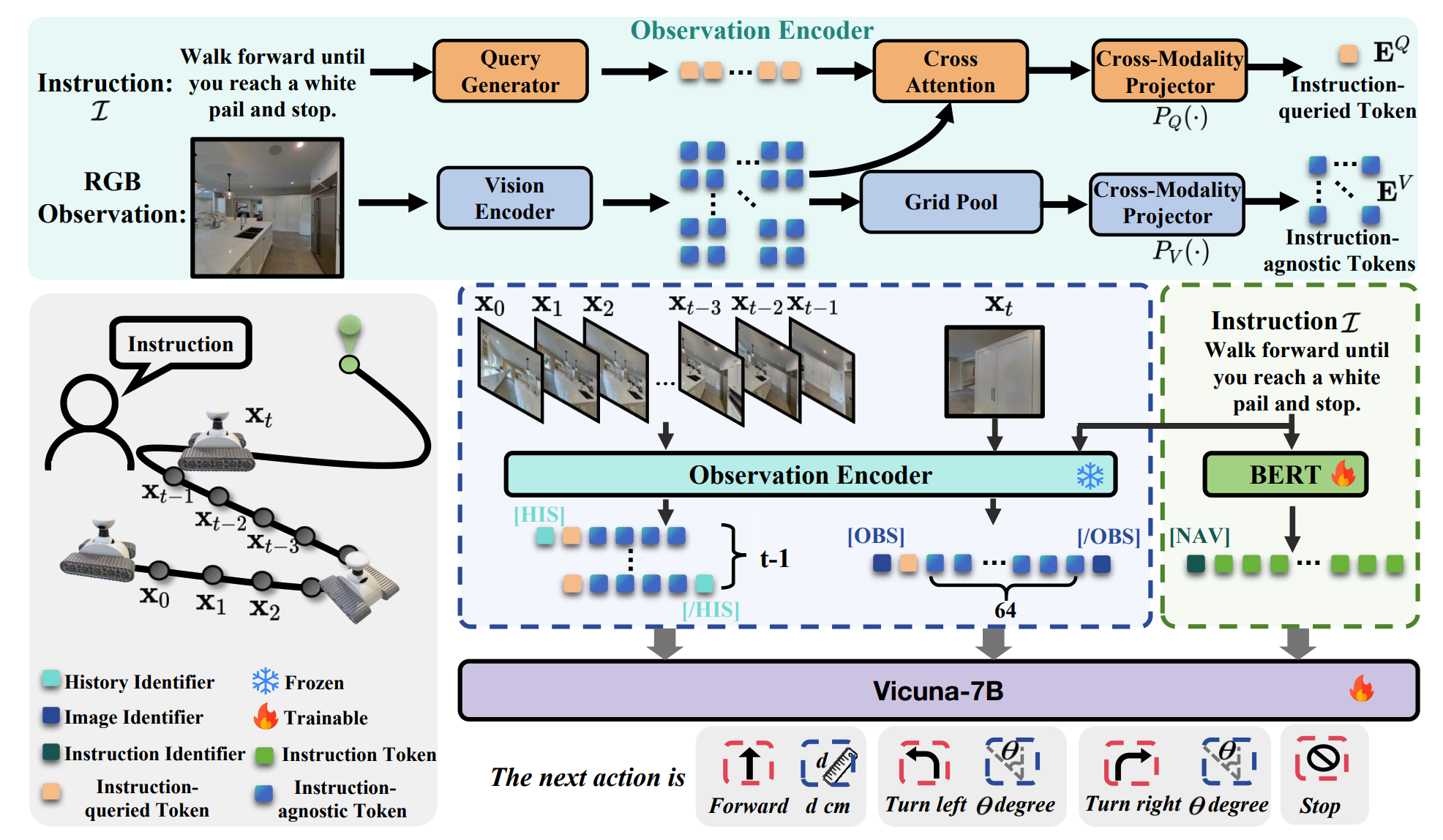
NaVid
Paper: NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Qwen3-VL
Blog: Qwen3-VL:明察、深思、广行
Code: https://github.com/QwenLM/Qwen3-VL
PaddleOCR-VL
Paper: PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
Code: https://github.com/PaddlePaddle/PaddleOCR


DeepSeek-OCR
Paper: DeepSeek-OCR: Contexts Optical Compression
Code: https://github.com/deepseek-ai/DeepSeek-OCR


V-JEPA 2.1
Paper: V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Code: https://github.com/facebookresearch/vjepa2

This site was last updated May 28, 2026.