LLM
History of LLMs
A Survey of Large Language Models
LLM Timeline

計算記憶體的成長與Transformer大小的關係
Paper: AI and Memory Wall

Scaling Law
我們可以用模型大小、Dataset大小、總計算量,來預測模型最終能力。(通常以相對簡單的函數型態, ex: Linear relationship)
GPT-4 Technical Report. OpenAI. 2023
Blog: 【LLM 10大觀念-1】Scaling Law
Papers:
- Hestness et al. 於2017發現在Machine Translation, Language Modeling, Speech Recognition和Image Classification都有出現Scaling law.
- OpenAI Kaplan et al.2020 於2020年從計算量、Dataset大小、跟參數量分別討論了Scaling Law。
- Rosenfeld et al. 於2021年發表了關於Scaling Law的survey paper。在各種architecture更進一步驗證Scaling Law的普適性。
Chinchilla Scaling Law
Paper: Training Compute-Optimal Large Language Models
如果我們接受原本Scaling Law的定義(模型性能可藉由參數量、Dataset大小、計算量預測),馬上就會衍伸出兩個很重要的問題:
Return(收益): 在固定的訓練計算量之下,我們所能得到的最好性能是多好?
Allocation(分配):我們要怎麼分配我們的模型參數量跟Dataset大小。
(假設計算量 = 參數量 * Dataset size,我們要大模型 * 少量data、中模型 * 中量data、還是小模型 * 大量data)
2022年DeepMind提出Chinchilla Scaling Law,同時解決了這兩個問題,並且依此改善了當時其他大模型的訓練方式。
他們基於三種方式來找到訓練LLM的Scaling Law:
- 固定模型大小,變化訓練Data數量。
- 固定計算量(浮點運算),變化模型大小。
- 對所有實驗結果,直接擬合參數化損失函數。
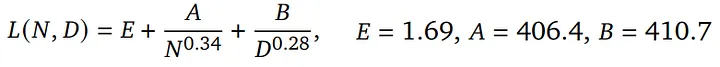
Method 3 result from Chinchilla Scaling Law,N是模型參數量、D是數據量、其他都是係數
LLM最終的Loss(Perplexity),會隨著模型放大、數據量變多而下降,並且是跟他們呈現指數映射後線性關係。
Chinchilla最大的貢獻更是在解決Allocation的問題,他們發現
- 數據量(Tokens數)應該要約等於模型參數量的20倍
- 並且數據量跟模型參數量要同比放大(Ex: 模型放大一倍,數據也要跟著增加一倍)
Large Language Models
生成式AI時代下的機器學習(2025) by Hung-Yi Lee
Open LLM Leaderboard
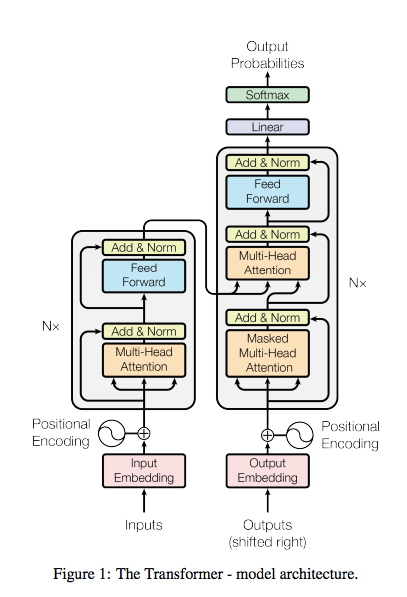
Transformer
Paper: Attention Is All You Need
ChatGPT
ChatGPT: Optimizing Language Models for Dialogue
ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.

LLaMA
Paper: LLaMA: Open and Efficient Foundation Language Models
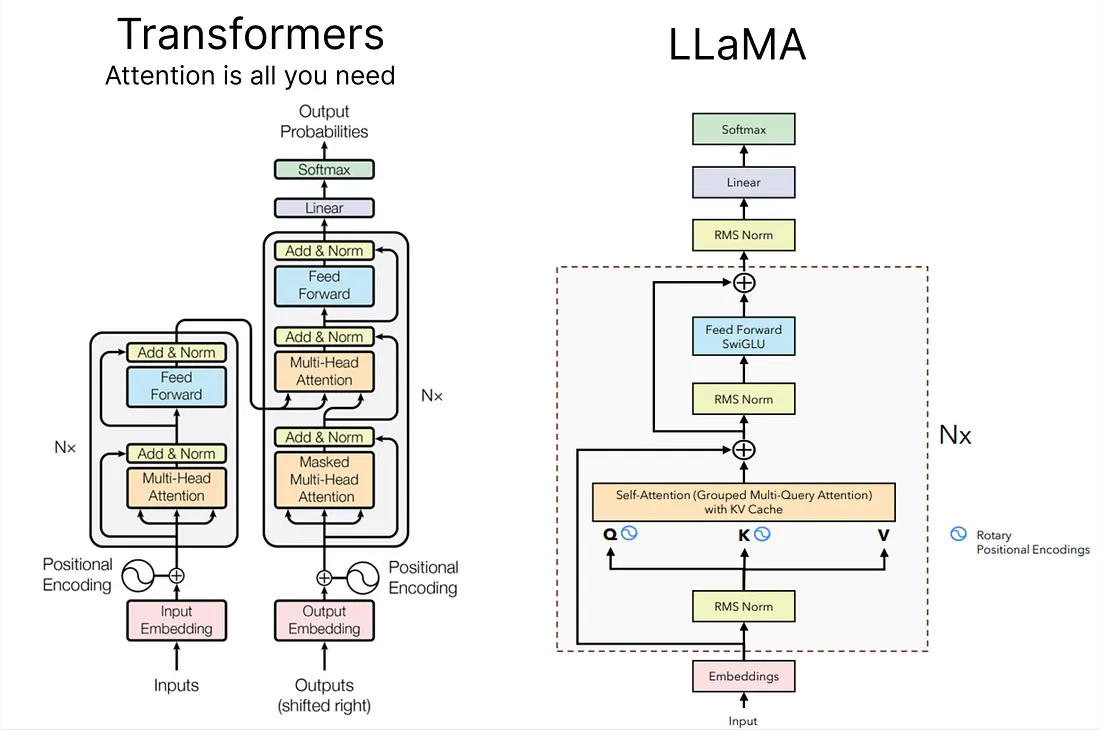
Blog: Building a Million-Parameter LLM from Scratch Using Python
Code: LLaMA from scratch
GPT-4
Paper: GPT-4 Technical Report

Paper: From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
Blog: GPT-4 Code Interpreter: The Next Big Thing in AI
Falcon-40B
HuggingFace: tiiuae/falcon-40b
Paper: The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
Vicuna
HuggingFace: lmsys/vicuna-7b-v1.5
Paper: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Code: https://github.com/lm-sys/FastChat
LLaMA-2
HuggingFace: meta-llama/Llama-2-7b-chat-hf
Paper: Llama 2: Open Foundation and Fine-Tuned Chat Models
Code: https://github.com/facebookresearch/llama
Mistral
HuggingFace: mistralai/Mistral-7B-Instruct-v0.2
Paper: Mistral 7B
Code: https://github.com/mistralai/mistral-src
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-mistral-7b-instruct

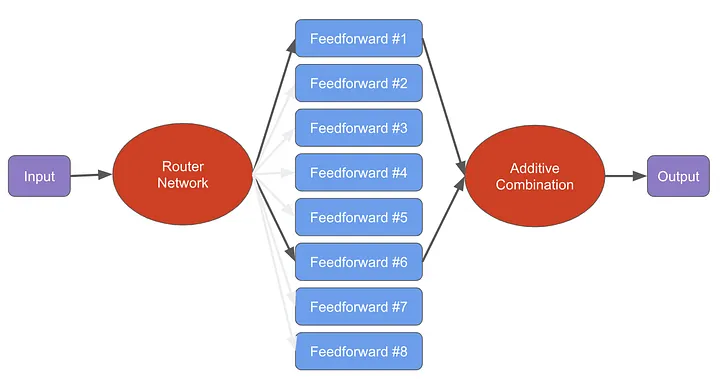
Mistral 8X7B
HuggingFace: mistralai/Mixtral-8x7B-v0.1
Paper: Mixtral of Experts
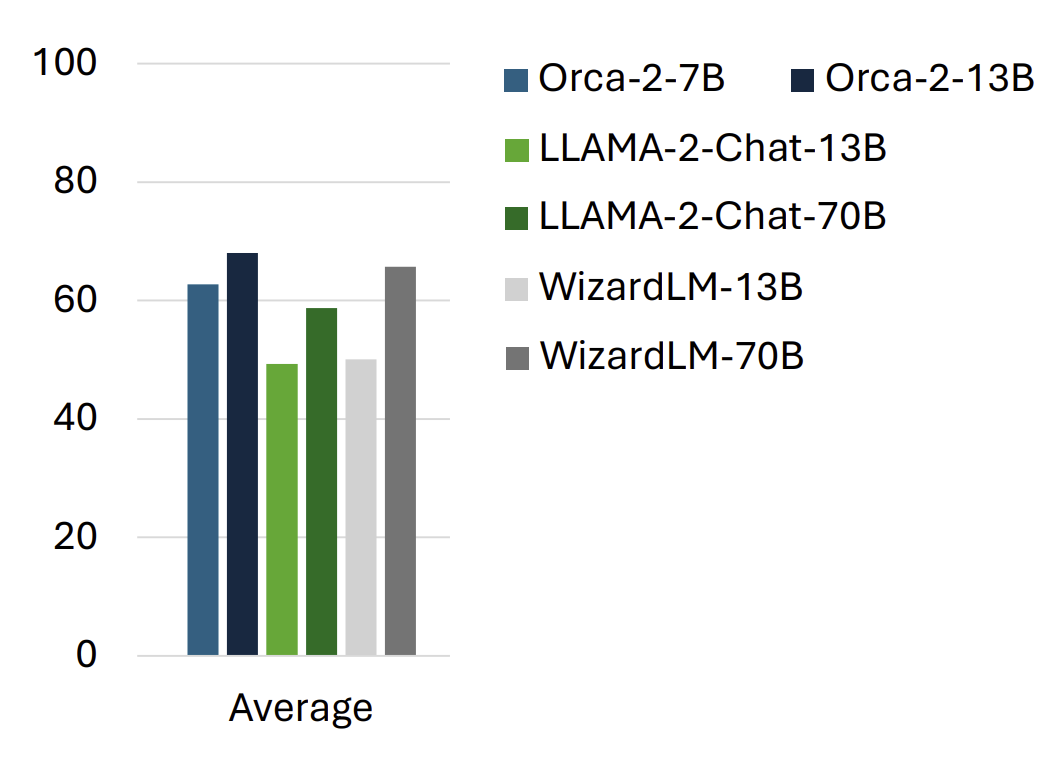
Orca 2
HuggingFace: microsoft/Orca-2-7b
Paper: https://arxiv.org/abs/2311.11045
Blog: Microsoft’s Orca 2 LLM Outperforms Models That Are 10x Larger
Taiwan-LLM (優必達+台大)
HuggingFace: yentinglin/Taiwan-LLM-7B-v2.1-chat
Paper: TAIWAN-LLM: Bridging the Linguistic Divide with a Culturally Aligned Language Model
Blog: 專屬台灣!優必達攜手台大打造「Taiwan LLM」,為何我們需要本土化的AI?
Code: https://github.com/MiuLab/Taiwan-LLM
Phi-2
HuggingFace: microsoft/phi-2
Blog: Phi-2: The surprising power of small language models
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-phi-2
Mamba
HuggingFace: Q-bert/Mamba-130M
Paper: Mamba: Linear-Time Sequence Modeling with Selective State Spaces

Qwen (通义千问)
HuggingFace: Qwen/Qwen1.5-7B-Chat
Blog: Introducing Qwen1.5
Code: https://github.com/QwenLM/Qwen1.5
Yi (零一万物)
HuggingFace: 01-ai/Yi-6B-Chat
Paper: CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Paper: Yi: Open Foundation Models by 01.AI
Orca-Math
Paper: Orca-Math: Unlocking the potential of SLMs in Grade School Math
HuggingFace: https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k
BitNet
Paper: BitNet: Scaling 1-bit Transformers for Large Language Models
Paper: The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Code: bitnet.cpp

Gemma
Blog: Gemma: Introducing new state-of-the-art open models
Kaggle: https://www.kaggle.com/code/nilaychauhan/fine-tune-gemma-models-in-keras-using-lora
Gemini-1.5
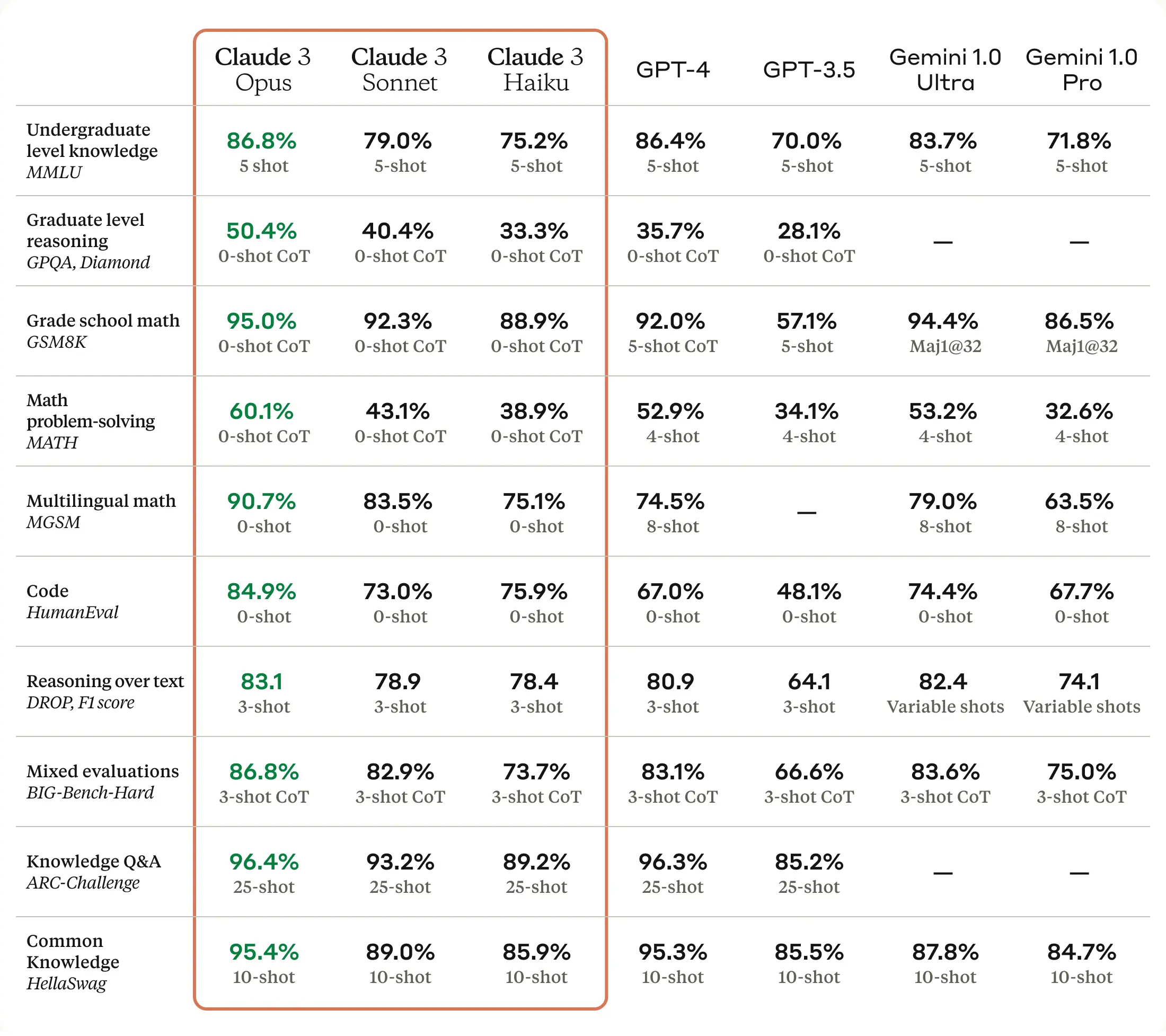
Claude 3
Breeze (達哥)
HuggingFace: MediaTek-Research/Breeze-7B-Instruct-v0_1
Paper: Breeze-7B Technical Report
Blog: Breeze-7B: 透過 Mistral-7B Fine-Tune 出來的繁中開源模型
Bialong (白龍)
HuggingFace: INX-TEXT/Bailong-instruct-7B
Paper: Bailong: Bilingual Transfer Learning based on QLoRA and Zip-tie Embedding
TAIDE
HuggingFace: taide/TAIDE-LX-7B-Chat
- TAIDE-LX-7B: 以 LLaMA2-7b 為基礎,僅使用繁體中文資料預訓練 (continuous pretraining)的模型,適合使用者會對模型進一步微調(fine tune)的使用情境。因預訓練模型沒有經過微調和偏好對齊,可能會產生惡意或不安全的輸出,使用時請小心。
- TAIDE-LX-7B-Chat: 以 TAIDE-LX-7B 為基礎,透過指令微調(instruction tuning)強化辦公室常用任務和多輪問答對話能力,適合聊天對話或任務協助的使用情境。TAIDE-LX-7B-Chat另外有提供4 bit 量化模型,量化模型主要是提供使用者的便利性,可能會影響效能與更多不可預期的問題,還請使用者理解與注意。
Llama-3
HuggingFace: meta-llama/Meta-Llama-3-8B-Instruct
Code: https://github.com/meta-llama/llama3/

Phi-3
HuggingFace: microsoft/Phi-3-mini-4k-instruct”
Blog: Introducing Phi-3: Redefining what’s possible with SLMs
Octopus v4
HuggingFace: NexaAIDev/Octopus-v4
Paper: Octopus v4: Graph of language models
Code: https://github.com/NexaAI/octopus-v4
ChatGLM
Paper: ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Llama 3.1
HuggingFace: meta-llama/Meta-Llama-3.1-8B-Instruct

Grok-2
Grok-2 & Grok-2 mini, achieve performance levels competitive to other frontier models in areas such as graduate-level science knowledge (GPQA), general knowledge (MMLU, MMLU-Pro), and math competition problems (MATH). Additionally, Grok-2 excels in vision-based tasks, delivering state-of-the-art performance in visual math reasoning (MathVista) and in document-based question answering (DocVQA).
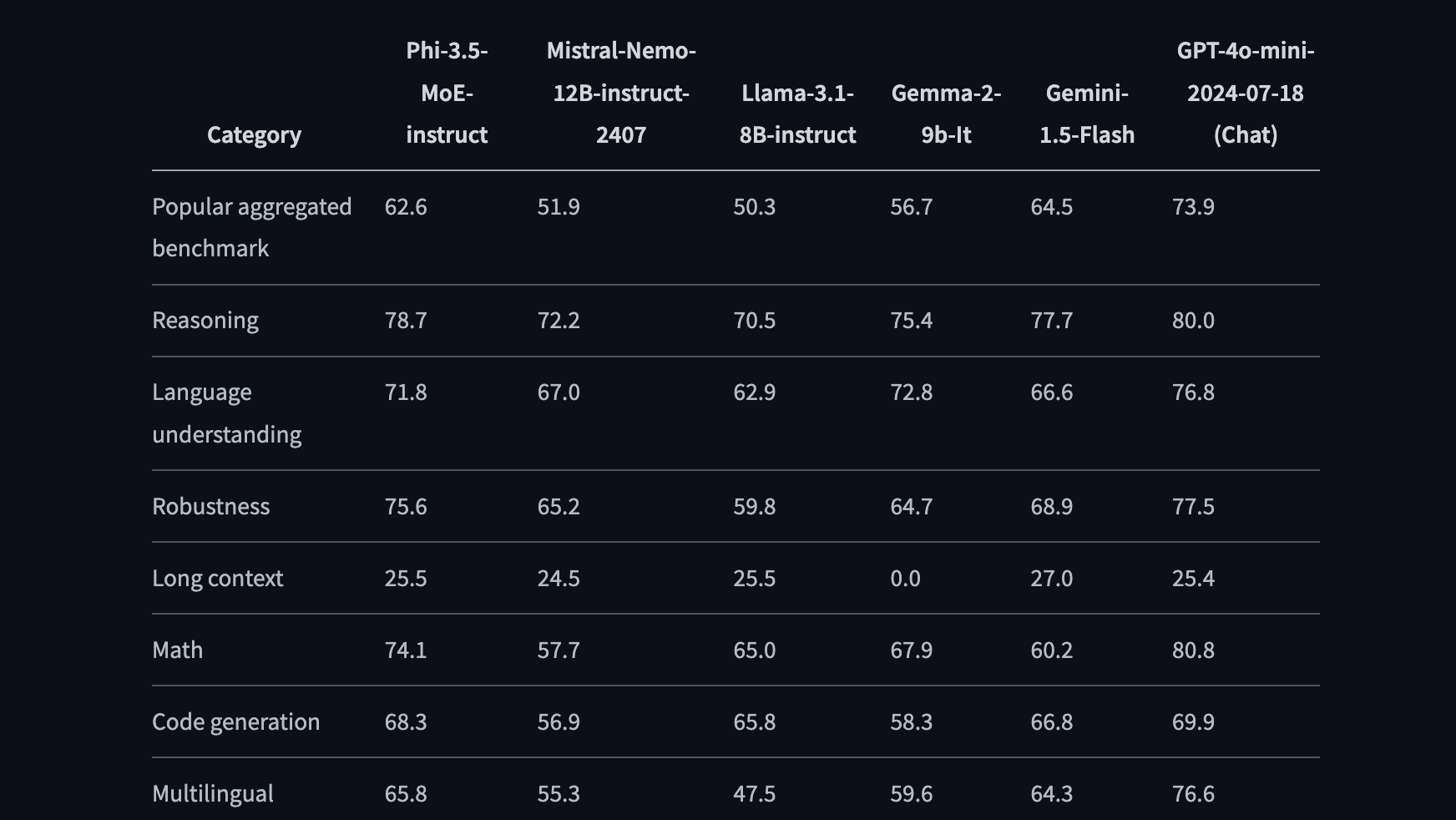
Phi-3.5
News: Microsoft Unveils Phi-3.5: Powerful AI Models Punch Above Their Weight
OpenAI o1
Blog: Introducing OpenAI o1-preview

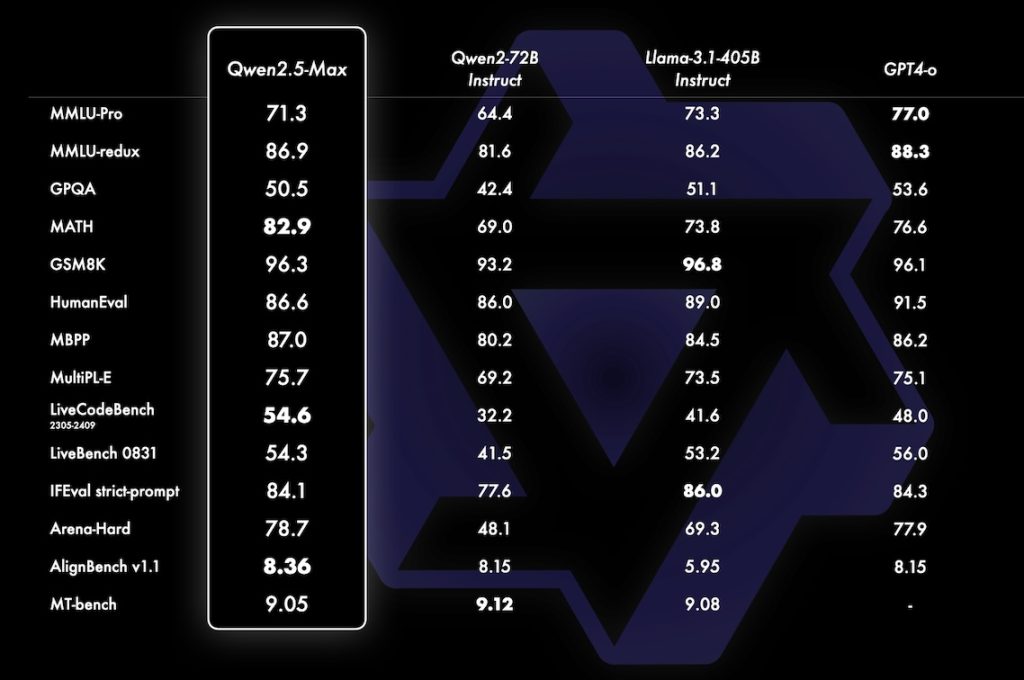
Qwen2.5
HuggingFace: Qwen/Qwen2.5-7B-Instruct
Blog: 阿里雲AI算力大升級!發佈100個開源Qwen 2.5模型及視頻AI模型
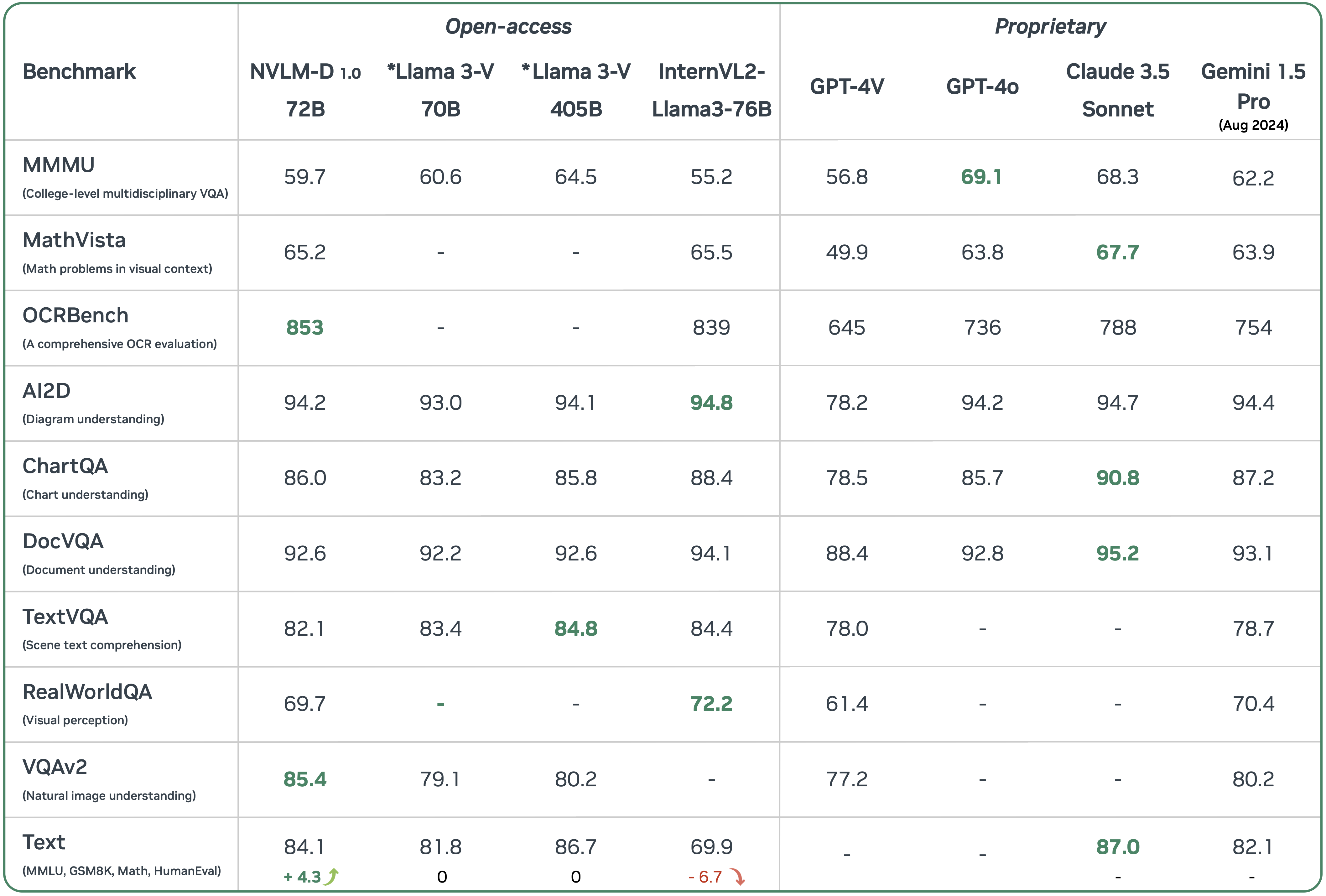
NVLM 1.0
Paper: NVLM: Open Frontier-Class Multimodal LLMs
Llama 3.2
Blog: Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
HuggingFace: meta-llama/Llama-3.2-3B-Instruct

LFM Liquid-3B

Llama 3.3
HuggingFace: meta-llama/Llama-3.3-70B-Instruct
Blog: Meta公布輕巧版多語言模型Llama 3.3
OpenAI o3-mini

DeepSeek-R1
Paper: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Code: https://github.com/deepseek-ai/DeepSeek-R1

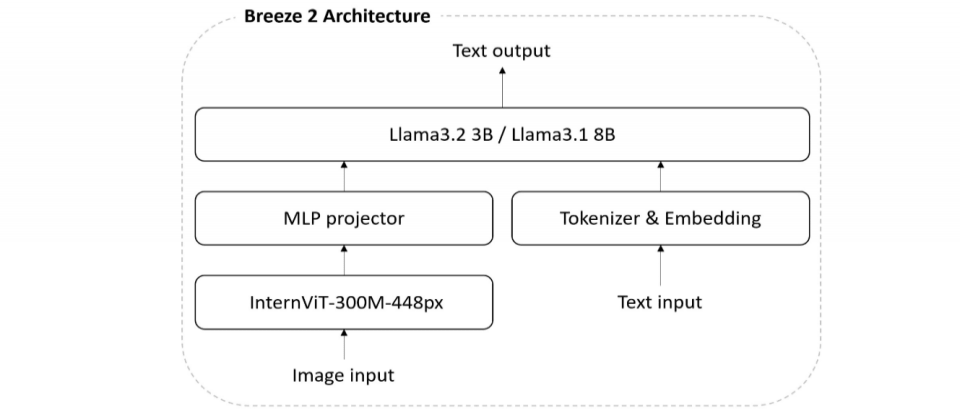
Llama-Breeze2
HuggingFace: MediaTek-Research/Llama-Breeze2-8B-Instruct
Paper: The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on Llama with Vision-Aware and Function-Calling Capabilities
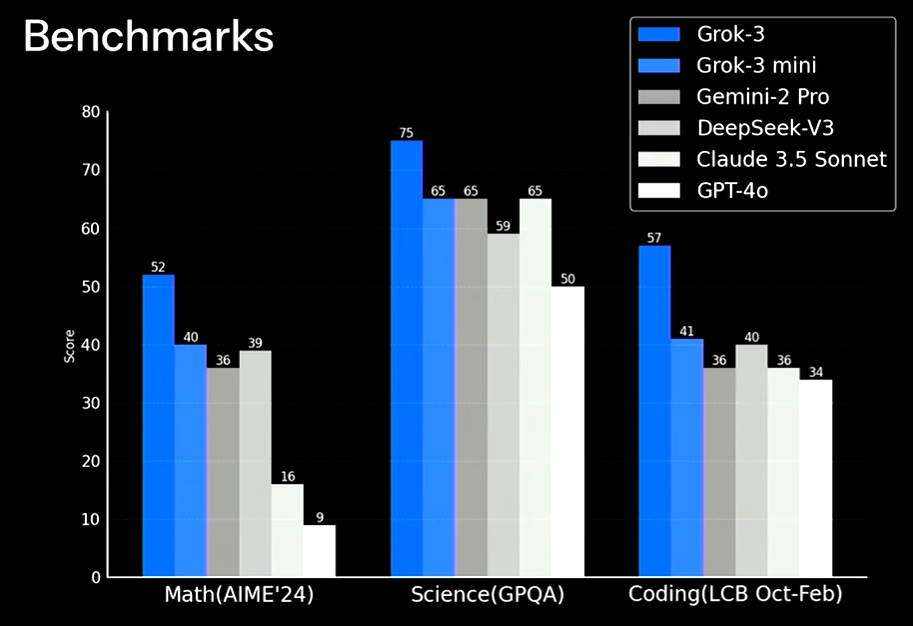
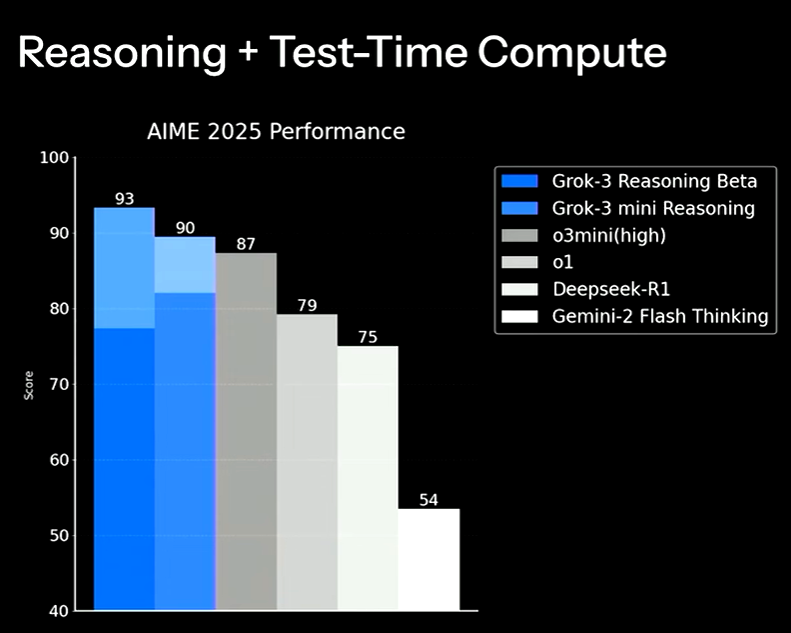
Grok-3 The Age of Reasoning Agents
Phi-4-multimodal
Phi-4-multimodal具有56億參數,支援12.8萬Token的上下文長度,並透過監督式微調、直接偏好最佳化(DPO)與人類回饋強化學習(RLHF)等方式,提升指令遵循能力與安全性。在語言支援方面,文字處理涵蓋超過20種語言,包括中文、日文、韓文、德文與法文等,語音處理則涵蓋英語、中文、西班牙語、日語等主要語種,圖像處理目前則以英文為主。
GuggingFace: microsoft/Phi-4-multimodal-instruct

Gemini-2.5
Llama-4
Blog: Implementing LLaMA 4 from Scratch
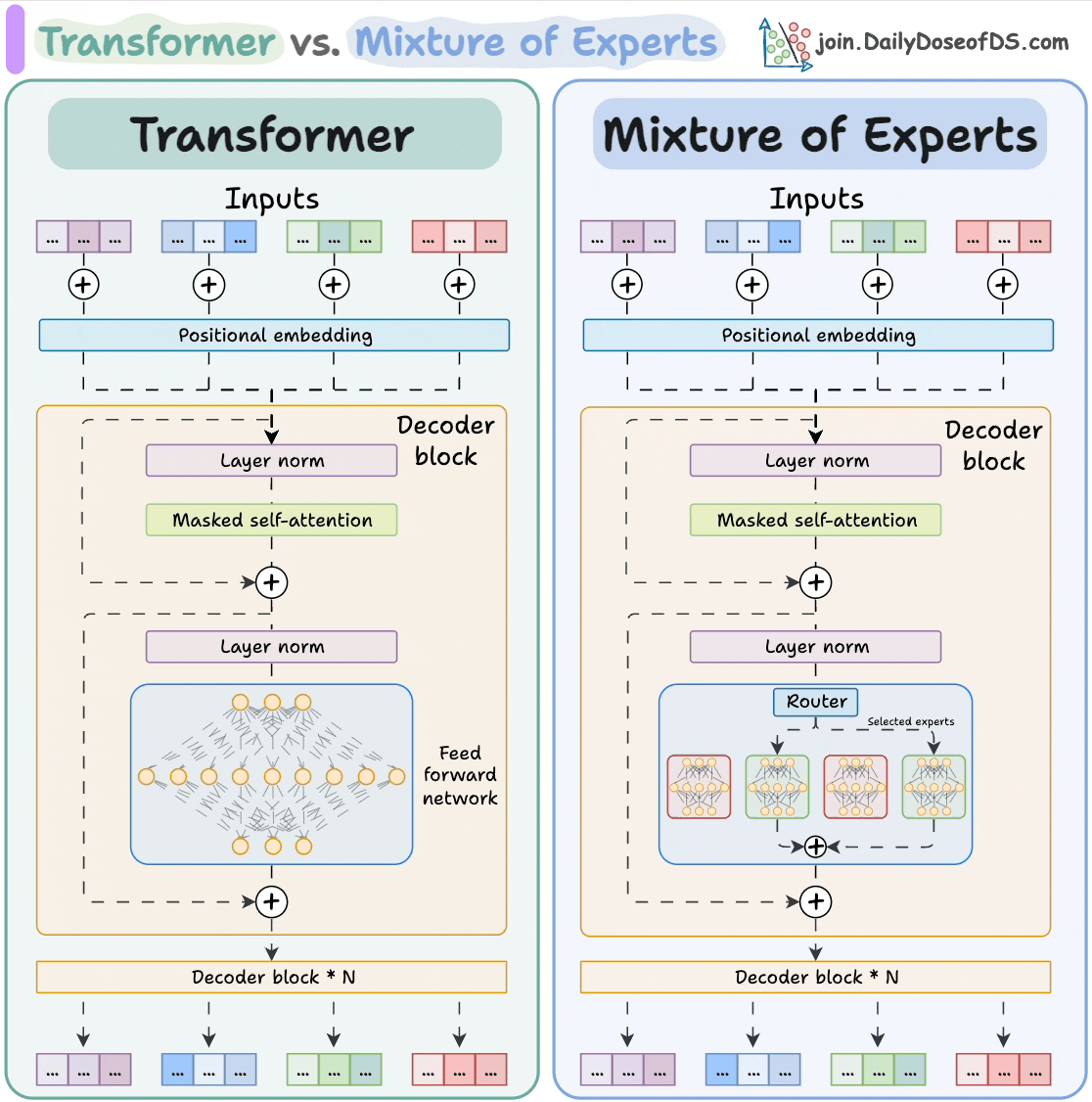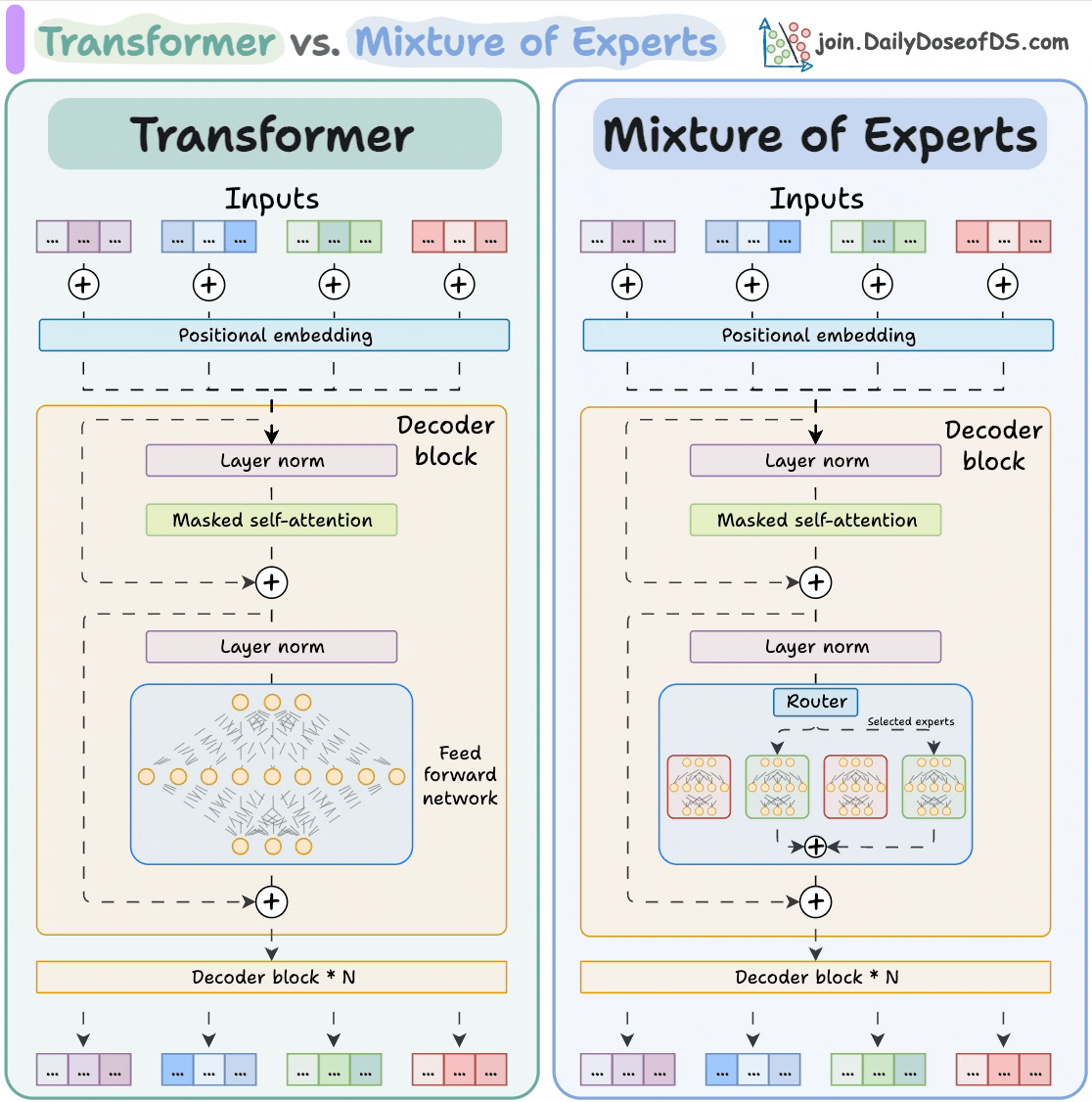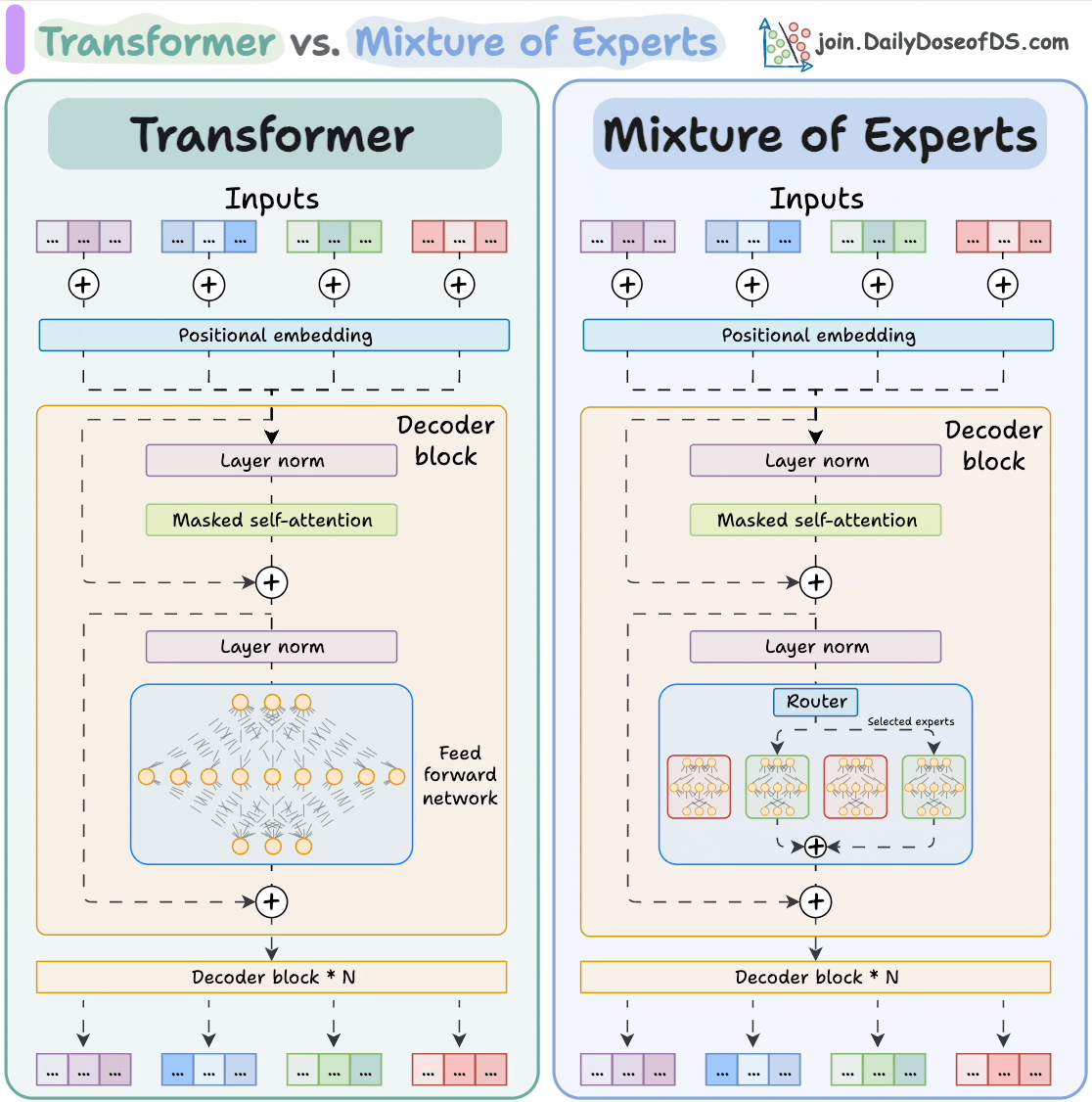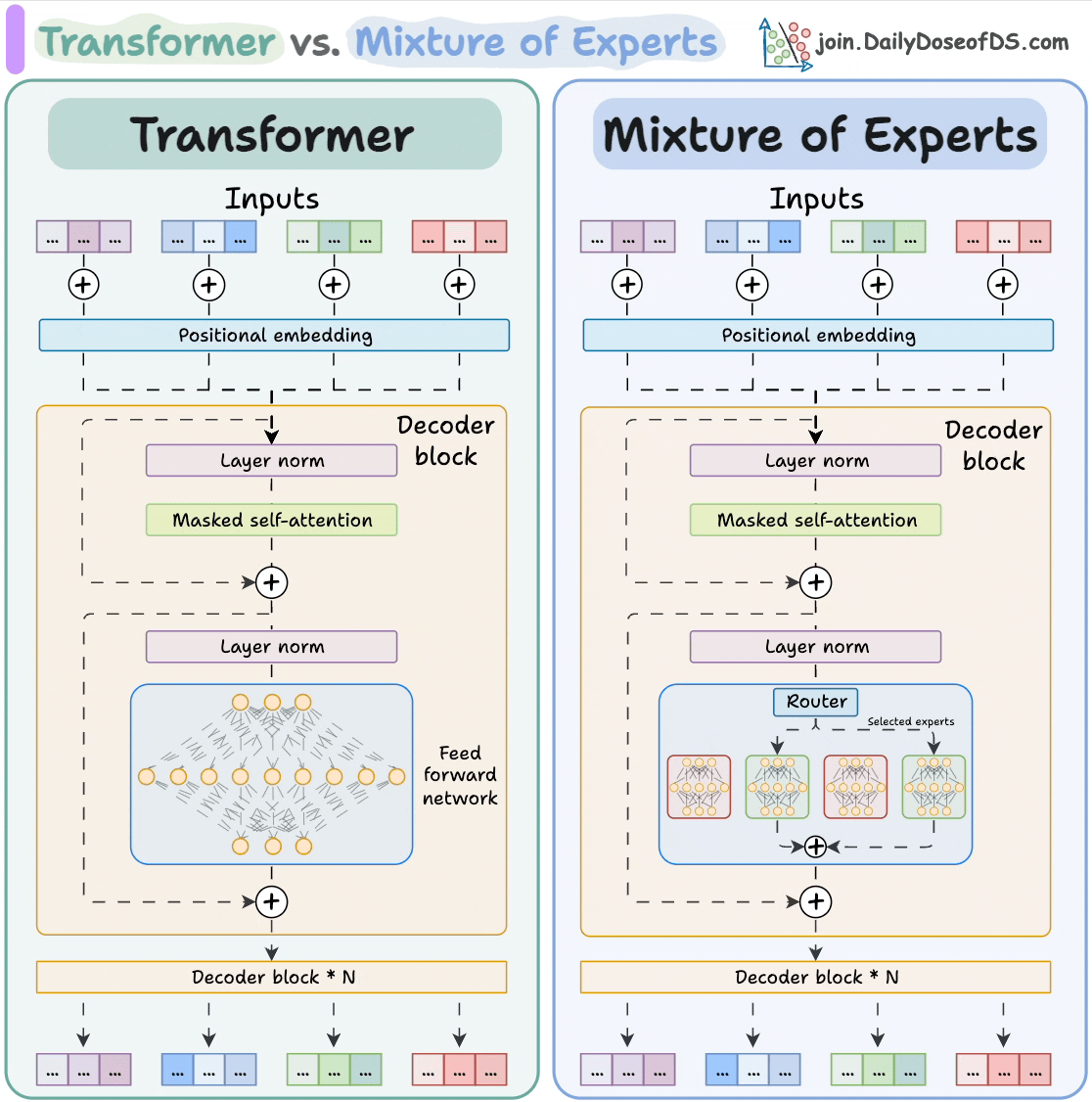
Kaggle: https://www.kaggle.com/code/rkuo2000/llama4-from-scratch
Grok-4
GPT-5
Gemini-2.5 Family
Qwen3-Next
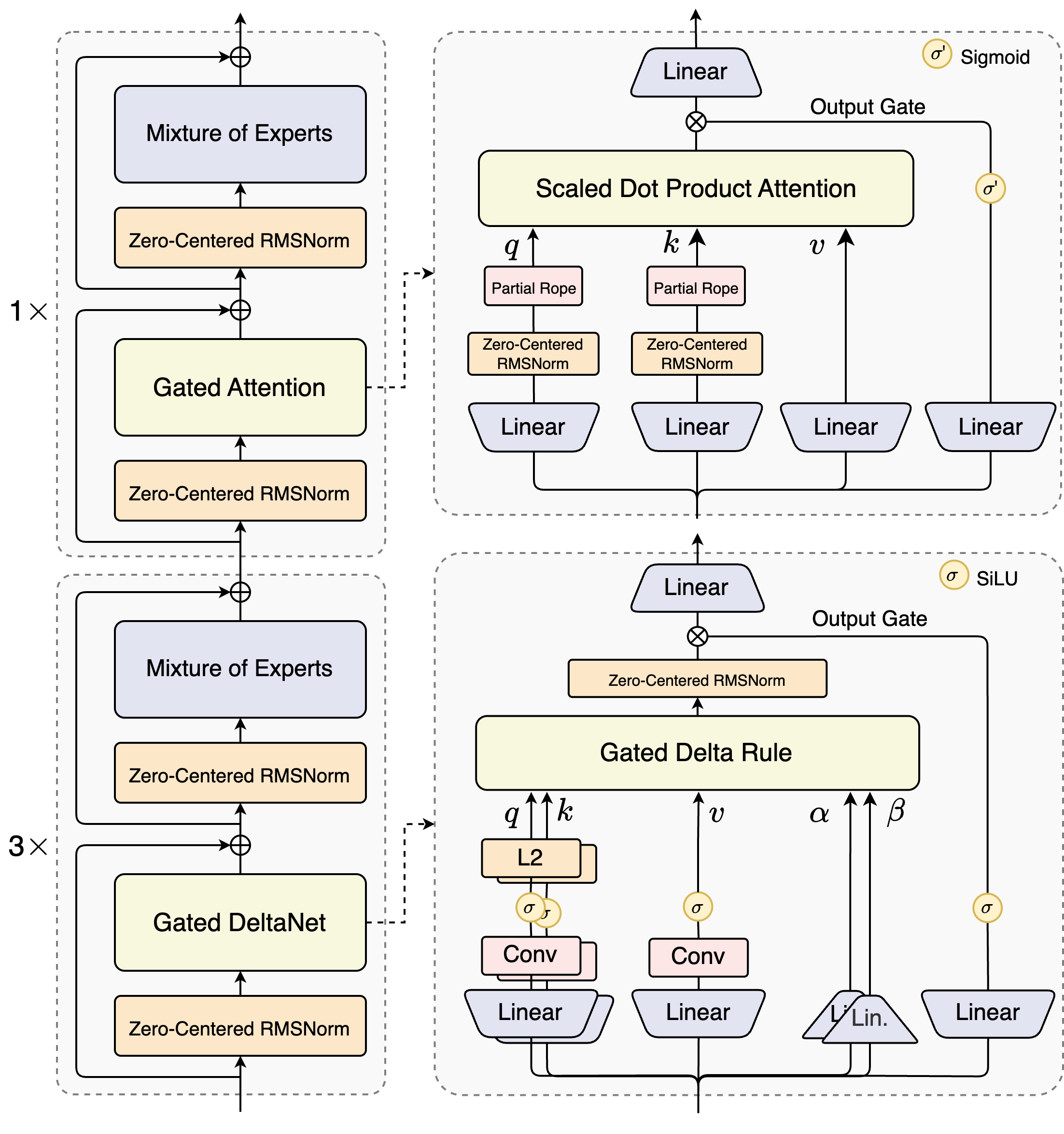
Qwen3-Omni
Paper: Qwen3-Omni Technical Report

Olmo3
Blog: Ai2釋出真開源思考模型Olmo 3,支援可回溯推理與長上下文
GLM 4.5
Paper: GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Code: https://github.com/zai-org/GLM-4.5
Gemini 3
Claude Opus 4.5
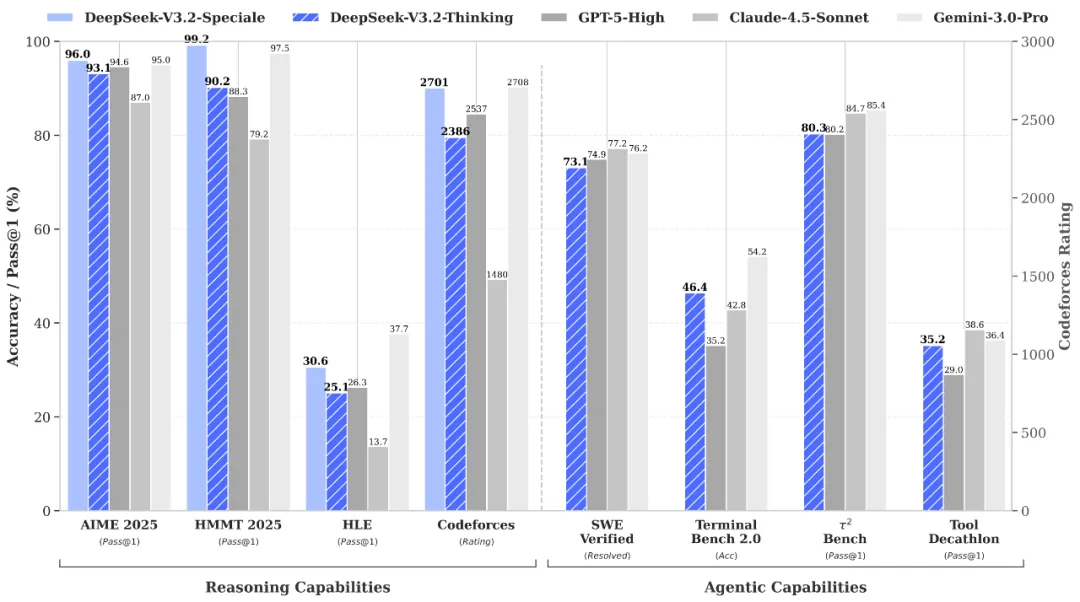
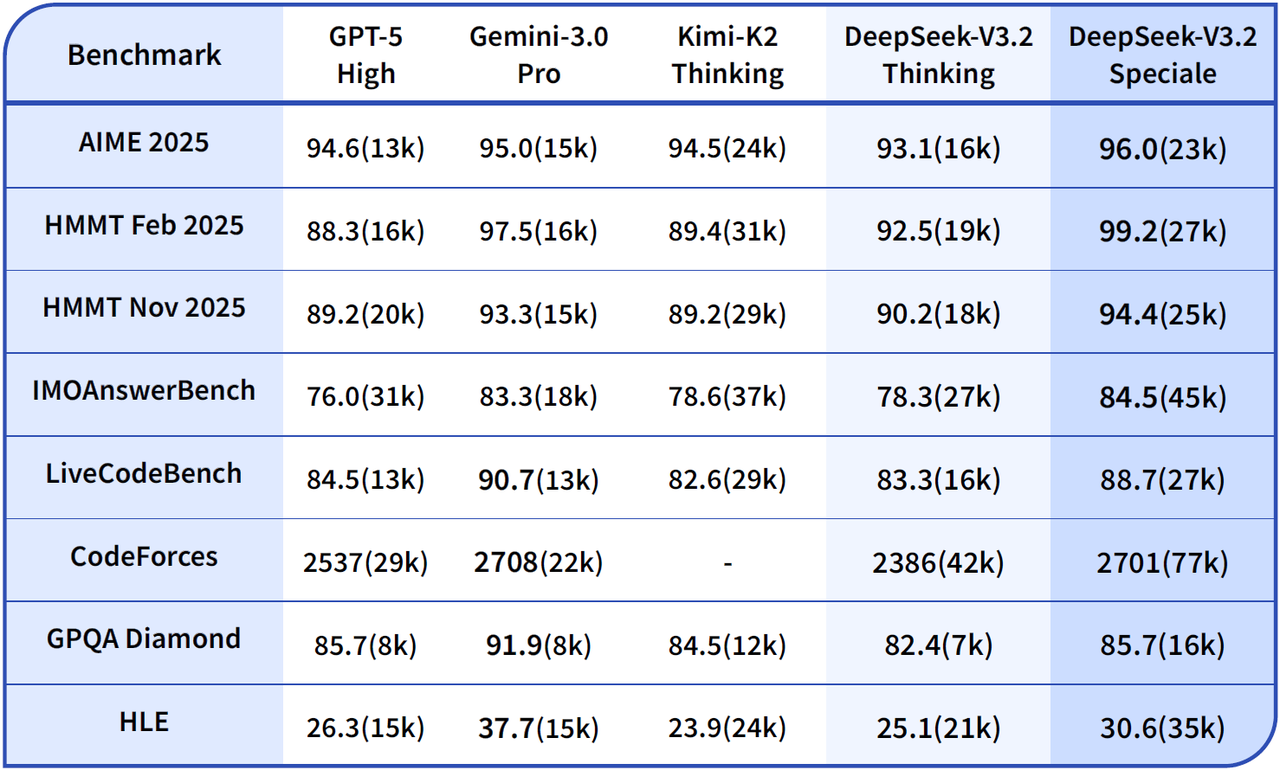
DeepSeek v3.2
Paper: DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
GPT-5.2
GLM-4.7


Kimi K2.5
Paper: Kimi K2.5: Visual Agentic Intelligence
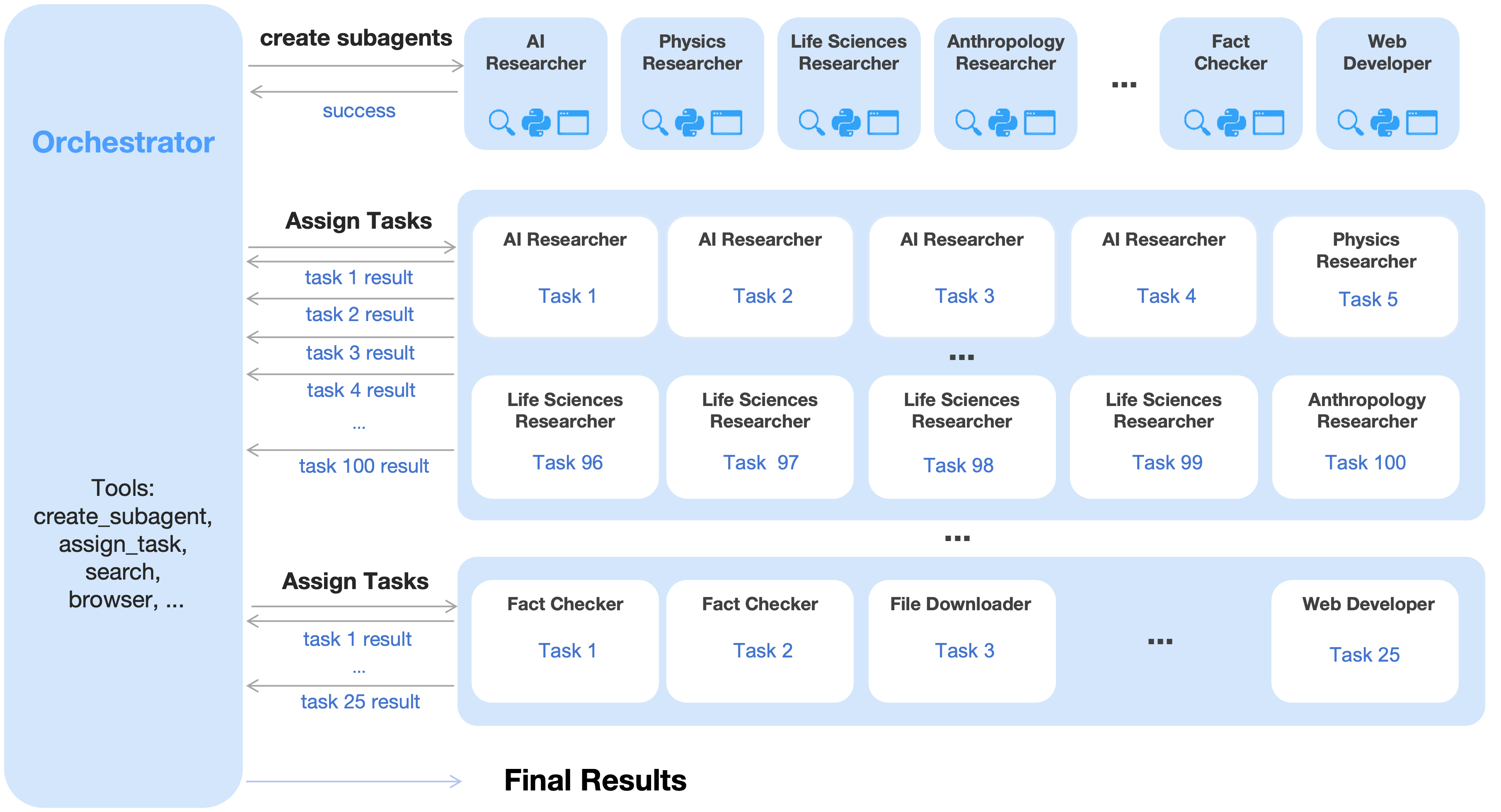 An agent swarm has a trainable orchestrator that dynamically creates specialized frozen subagents and decomposes complex tasks into parallelizable subtasks for efficient distributed execution.
An agent swarm has a trainable orchestrator that dynamically creates specialized frozen subagents and decomposes complex tasks into parallelizable subtasks for efficient distributed execution.
Nemotron-3
Paper: NVIDIA Nemotron 3: Efficient and Open Intelligence

GPT5.3 Codex
Claude Opus 4.6
MiniMax M2.5: Built for Real-World Productivity
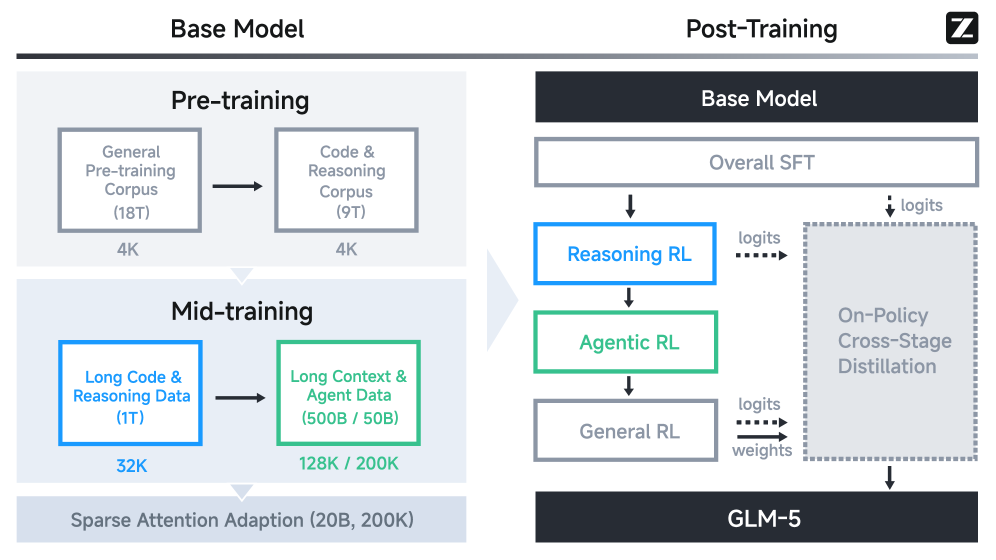
GLM-5
Paper: GLM-5: from Vibe Coding to Agentic Engineering
Qwen3.5:Towards Native Multimodal Agents
GPT-5.4
GPT‑5.4 in ChatGPT (as GPT‑5.4 Thinking), the API, and Codex. It’s our most capable and efficient frontier model for professional work.
We’re also releasing GPT‑5.4 Pro in ChatGPT and the API, for people who want maximum performance on complex tasks.
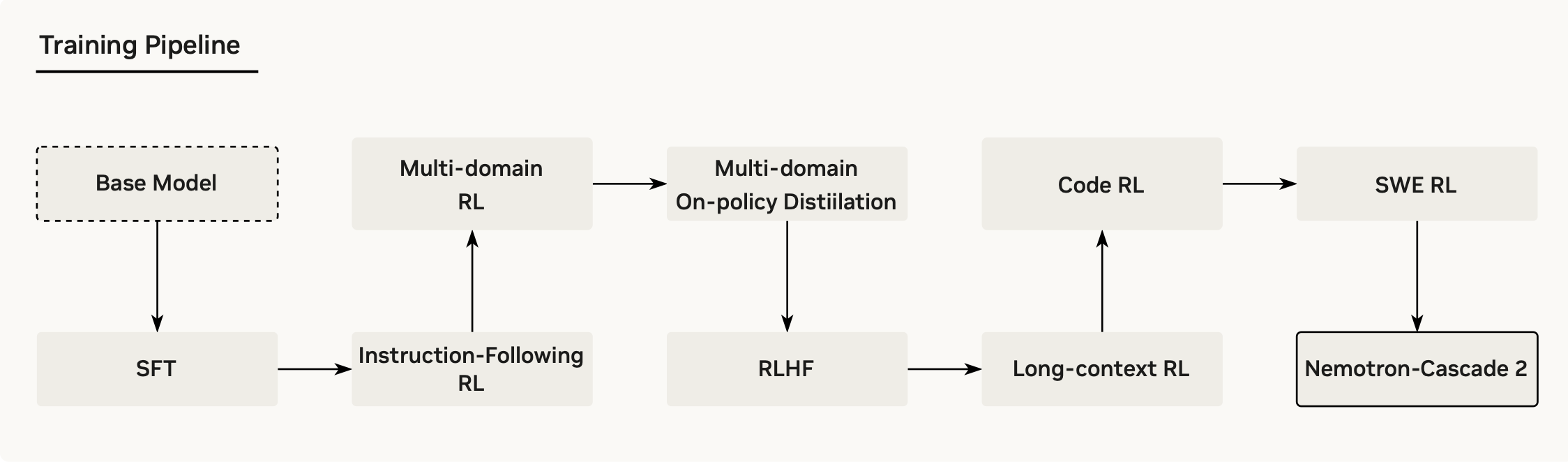
Nemotron-Cascade 2
Paper: Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
Gemma 4
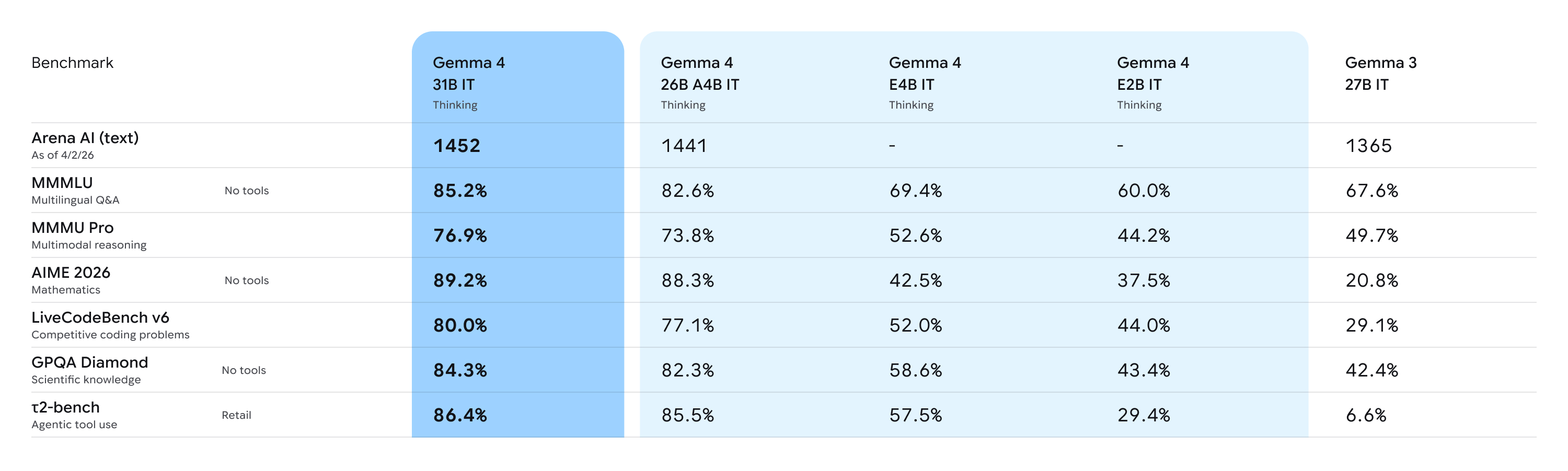
Qwen 3.6
DeepSeek-V4
- DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
- DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world’s top closed-source models.
- DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
GPT-5.5
Claude Opus 4.8

safe AI
Constitutional AI
Paper: Constitutional AI: Harmlessness from AI Feedback
Two key phases:
- Supervised Learning Phase (SL Phase)
- Step1: The learning starts using the samples from the initial model
- Step2: From these samples, the model generates self-critiques and revisions
- Step3: Fine-tine the original model with these revisions
- Reinforcement Learning Phase (RL Phease)
- Step1. The model uses samples from the fine-tuned model.
- Step2. Use a model to compare the outputs from samples from the initial model and the fine-tuned model
- Step3. Decide which sample is better. (RLHF)
- Step4. Train a new “preference model” from the new dataset of AI preferences. This new “prefernece model” will then be used to re-train the RL (as a reward signal). It is now the RLHAF (Reinforcement Learning from AI feedback)
Attack LLM
Blog: 如何攻擊 LLM (ChatGPT) ?
- JailBreak
- Prompt Injection
- Data poisoning
local LLM
Ollama
Code: Code
Kaggle:
vLLM
Code: https://github.com/vllm-project/vllm
pip install vllm
LM Studio


llama.cpp
LLM inference in C/C++
RLM
Paper: Reasoning Language Models: A Blueprint
LLM Reasoning
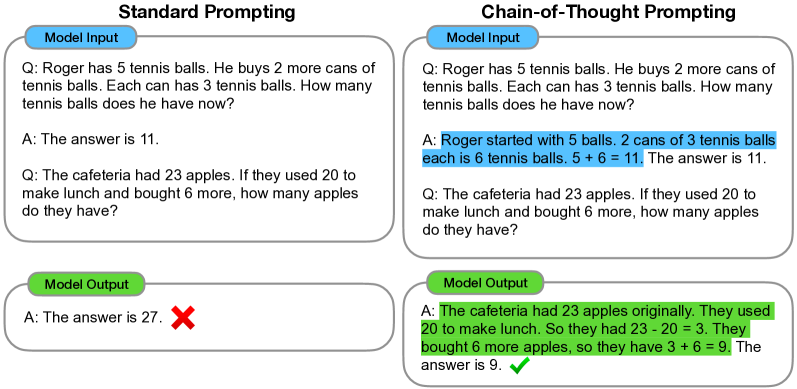
Chain-of-Thought Prompting
Paper: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
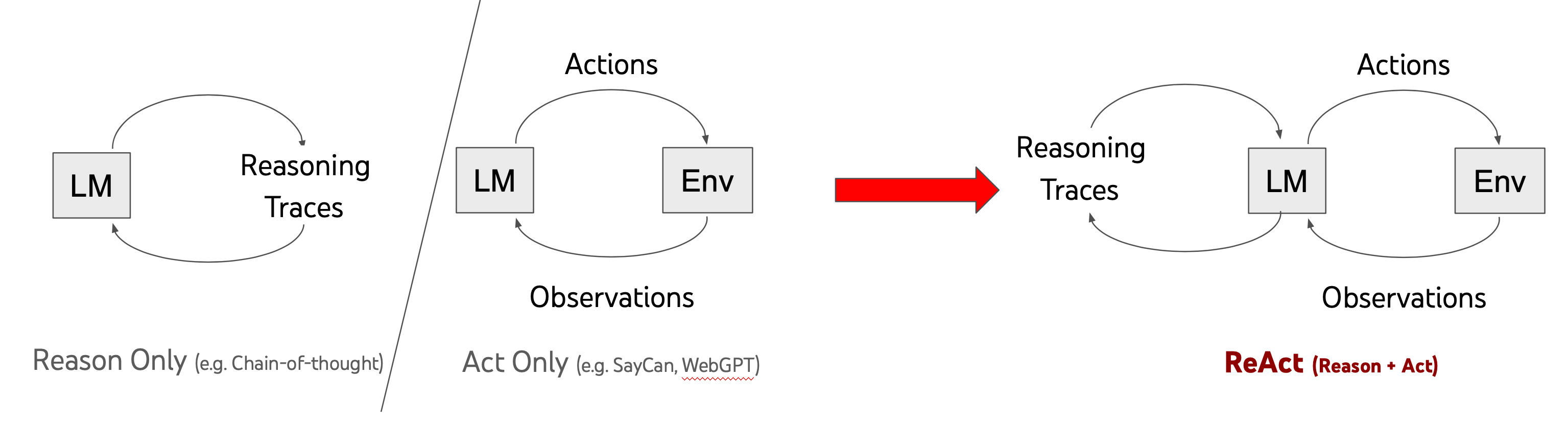
ReAct Prompting
Paper: ReAct: Synergizing Reasoning and Acting in Language Models
Code: https://github.com/ysymyth/ReAct
Tree-of-Thoughts
Paper: Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Code: https://github.com/princeton-nlp/tree-of-thought-llm
Code: https://github.com/kyegomez/tree-of-thoughts

Reinforcement Pre-Training
Paper: Reinforcement Pre-Training
Microsoft and China AI Research Possible Reinforcement Pre-Training Breakthrough

Teaching LLMs to Plan
Paper: Teaching LLMs to Plan: Logical Chain-of-Thought Instruction Tuning for Symbolic Planning
Alpaca-CoT
Alpaca-CoT: An Instruction-Tuning Platform with Unified Interface for Instruction Collection, Parameter-efficient Methods, and Large Language Models

TRM (Tiny Recursive Model)
Paper: Less is More: Recursive Reasoning with Tiny Networks
Code: https://github.com/SamsungSAILMontreal/TinyRecursiveModels
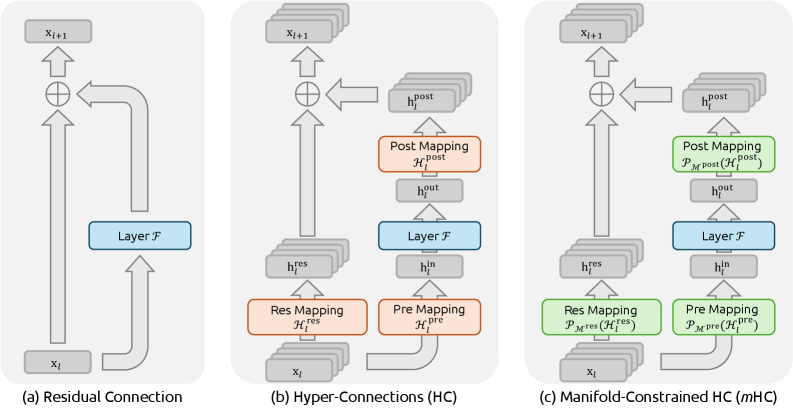
mHC
Paper: mHC: Manifold-Constrained Hyper-Connections
Attention Residuals
Paper: Attention Residuals
Code: https://github.com/MoonshotAI/Attention-Residuals

EverMemOS
Paper: EverMemOS : A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning
Continually Self-Improving AI
Paper: Continually self-improving AI
Prompt Engineering
Perfect Prompt Structure

訓練不了人工智慧?你可以訓練你自己
Thinking Claude
17歲高中生寫出「神級Prompt」強化Claude推理能力媲美o1模型,如何實現?
Thinking Gemini
https://github.com/lanesky/thinking-gemini
Context Engineering
什麼是 Context Engineering 上下文工程?
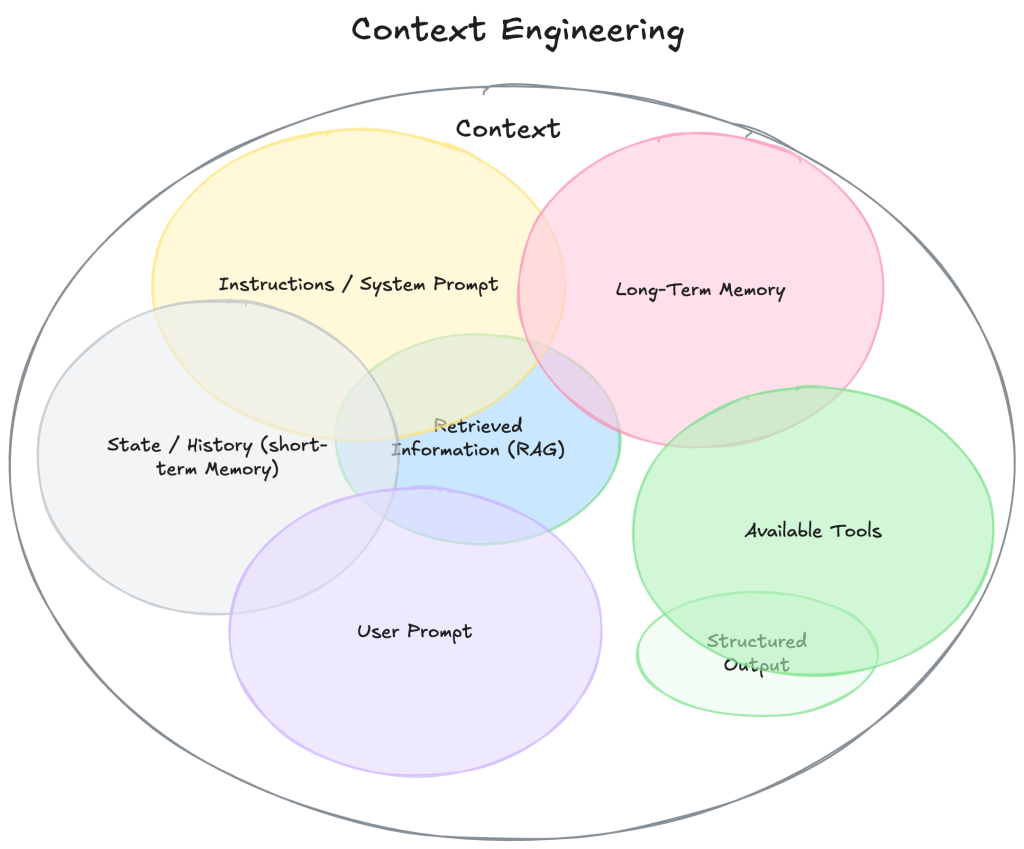
A Survey of Context Engineering for Large Language Models

情境工程(Context Engineering)解析:打造實用 AI Agent 的關鍵技巧,與提示工程(Prompt Engineering)有什麼不同?

ACE-open
Paper: Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Code: https://github.com/sci-m-wang/ACE-open

Agentic Engineering
Blog: 軟體開發新顯學:從 Vibe Coding 進化到 Agentic Engineering
This site was last updated May 28, 2026.