Model FineTuning
Model Training
Three Phases of Model Training
Blog: 解密 LLM 訓練三部曲:深入解析 SFT 與關鍵的 RLHF 技術
- 第一階段 (Self-Supervised Pre-Training):Pre-trained LLM
- 第二階段 (Supervised Fine-Tuning):SFT LLM
- 第三階段 (Reinforcement Learning from Human Feedback):Reward Model 與 Final Model
Blog: RLHF: Reinforcement Learning from Human Feedback
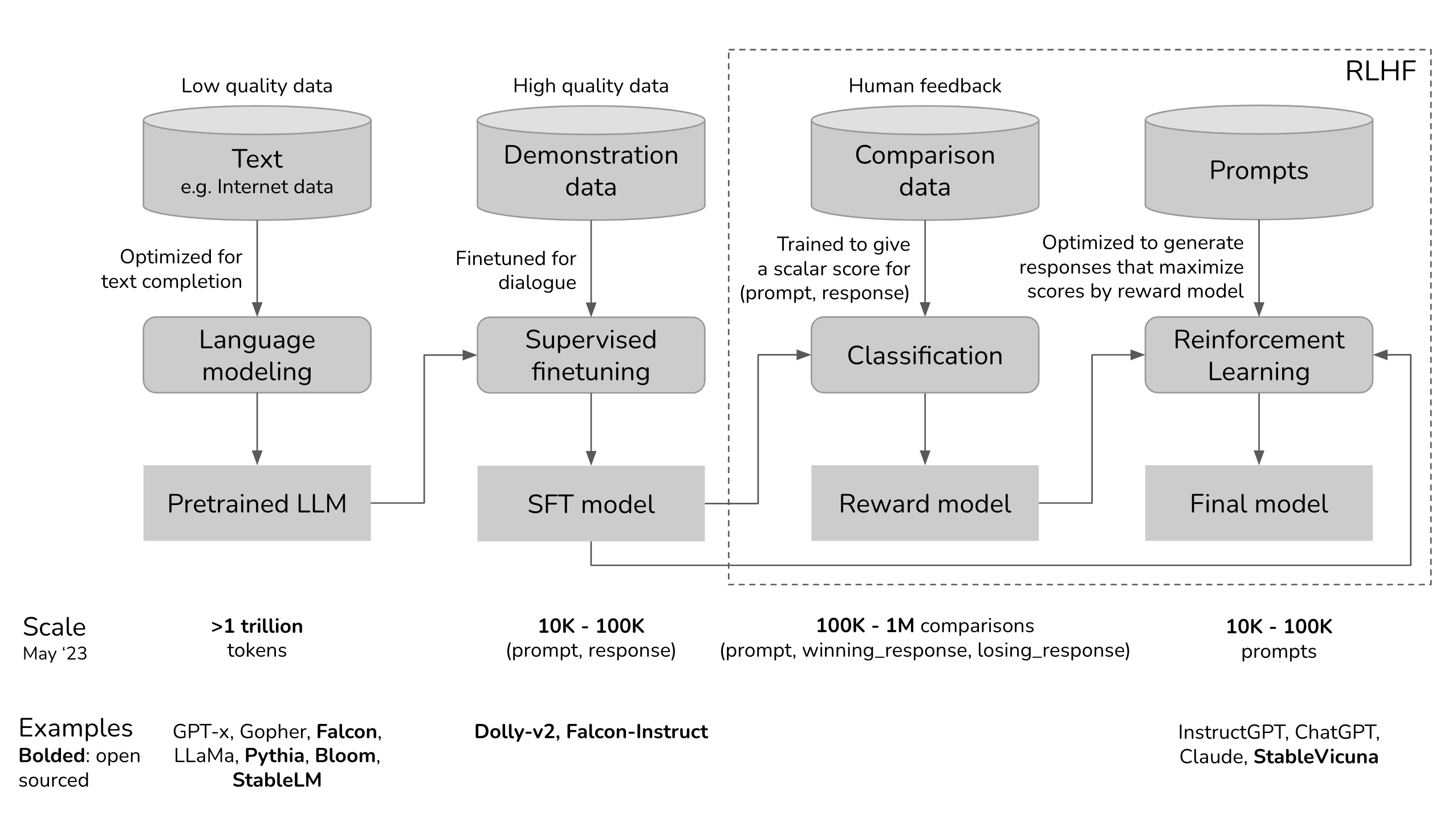
Pre-Train & Alignment (SFT, RLHF)
Post-Training & Forgetting
Build a Large Language Model (From Scratch)
Book: 讓 AI 好好說話!從頭打造 LLM (大型語言模型) 實戰秘笈

Build A Reasoning Model (From Scratch)
Model Fine-Tuning
SmolVLM with TRL (for ChartQA)
Blog: Fine-tuning SmolVLM with TRL on a consumer GPU
Model: HuggingFaceTB/SmolVLM-Instruct
Dataset: HuggingFaceM4/ChartQA
SmolVLM with TRL (for Invoice Parser)
Prompt: Fine-tuning Invoice Parser
Model: HuggingFaceTB/SmolVLM-Instruct
Dataset: mychen76/invoices-and-receipts_ocr_v1
VLM with DPO (for Super GPT-4V)
Blog: 使用 TRL 對視覺語言模型進行偏好最佳化
Model: HuggingFaceM4/idefics2-8b
Dataset: openbmb/RLAIF-V-Dataset
LLM with GRPO (for GSM8K)
Blog: Advanced GRPO Fine-tuning for Mathematical Reasoning with Multi-Reward Training
Model: Qwen/Qwen2.5-3B-Instruct
Dataset: openai/gsm8k
VLM with GRPO (for Reasoning)
Blog: Post training a VLM for reasoning with GRPO using TRL
Model: Qwen/Qwen2.5-VL-3B-Instruct
Dataset: lmms-lab/multimodal-open-r1-8k-verified

Codegen Enmpowerment
Paper: Training LLM Agents to Empower Humans
Code: https://github.com/festusev/codegen_empowerment

We train all models using a dataset of 4,138 unique questions from Codeforces, each of which is paired with one attempted solution by Gemma-3-27B-it.
- Assistant models: Llama-3.1-8B-Instruct, Qwen3-8B, and Qwen3-14B
- Human model: Gemma-3-27B-it
- Dataset: all based on MatrixStudio/Codeforces-Python_submissions
This dataset comes with actual human submissions, which we do not need. All we use are the problems themselves. - Prompts: See Section D in paper
- Algorithm: Logit Threshold Empowerment

TurboQuant
Paper: TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
Intelligence Benchmarks
OpenAI Evals
SWE-Bench
Paper: SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Code: https://github.com/SWE-bench/SWE-bench
MLE-Bench
Paper: MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Code: https://github.com/openai/mle-bench
SWE-Lancer
Paper: SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?
PaperBench
Paper: PaperBench: Evaluating AI’s Ability to Replicate AI Research
Code: https://github.com/openai/frontier-evals
SWE-Bench Pro
Paper: SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Code: https://github.com/scaleapi/SWE-bench_Pro-os
GPDval
Paper: GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
 Dataset: https://huggingface.co/datasets/openai/gdpval
Dataset: https://huggingface.co/datasets/openai/gdpval
- 220 real-world knowledge tasks across 44 occupations.
- Each task consists of a text prompt and a set of supporting reference files.
ToolOrchestra
Paper: ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration
Code: https://github.com/NVlabs/ToolOrchestra
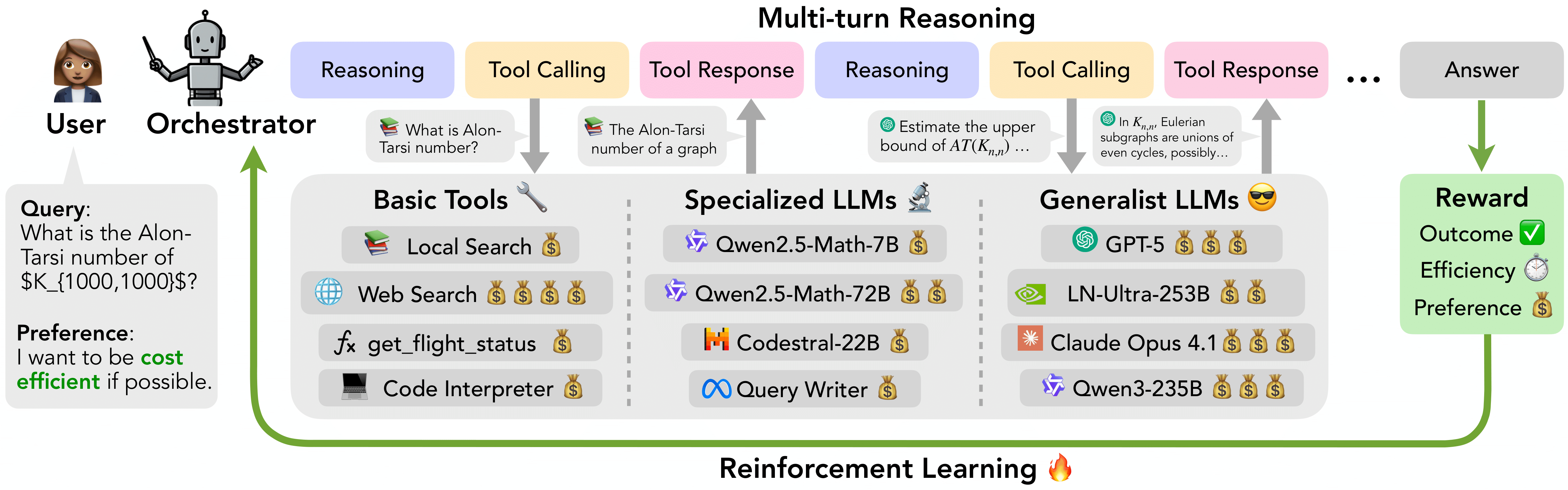
RLVR
Nemotron-Cascade 2
Paper: Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
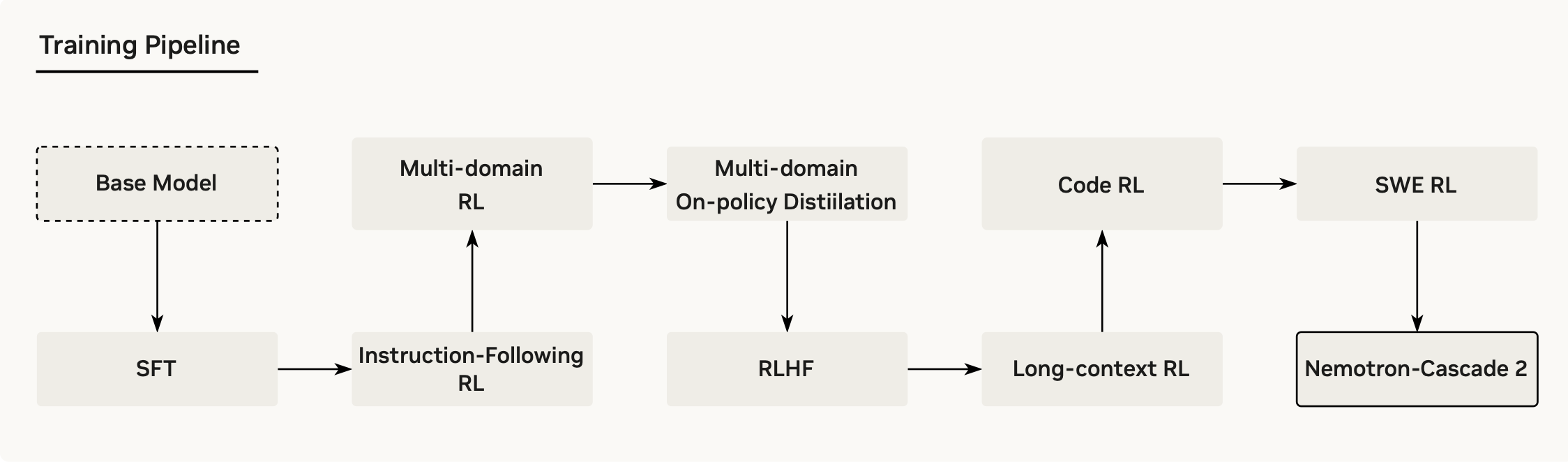
- Cascade RL Framework
- Multi-domain On-policy Distillation
Data:
- Nemotron-Cascade-2 SFT Data: the data used for the SFT stage of Nemotron-Cascade-2 training pipeline.
- Nemotron-Cascade-2 RL Data: the data used for our Nemotron-Cascade 2 RL training pipeline.
This site was last updated May 30, 2026.