Generative Video
李宏毅_生成式導論 2024
李宏毅_生成式導論 2024_第17講:有關影像的生成式AI (上) — AI 如何產生圖片和影片 (Sora 背後可能用的原理)
李宏毅_生成式導論 2024_第18講:有關影像的生成式AI (下) — 快速導讀經典影像生成方法 (VAE, Flow, Diffusion, GAN) 以及與生成的影片互動
Image-to-Video
Turn-A-Video
Paper: Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Code: https://github.com/showlab/Tune-A-Video
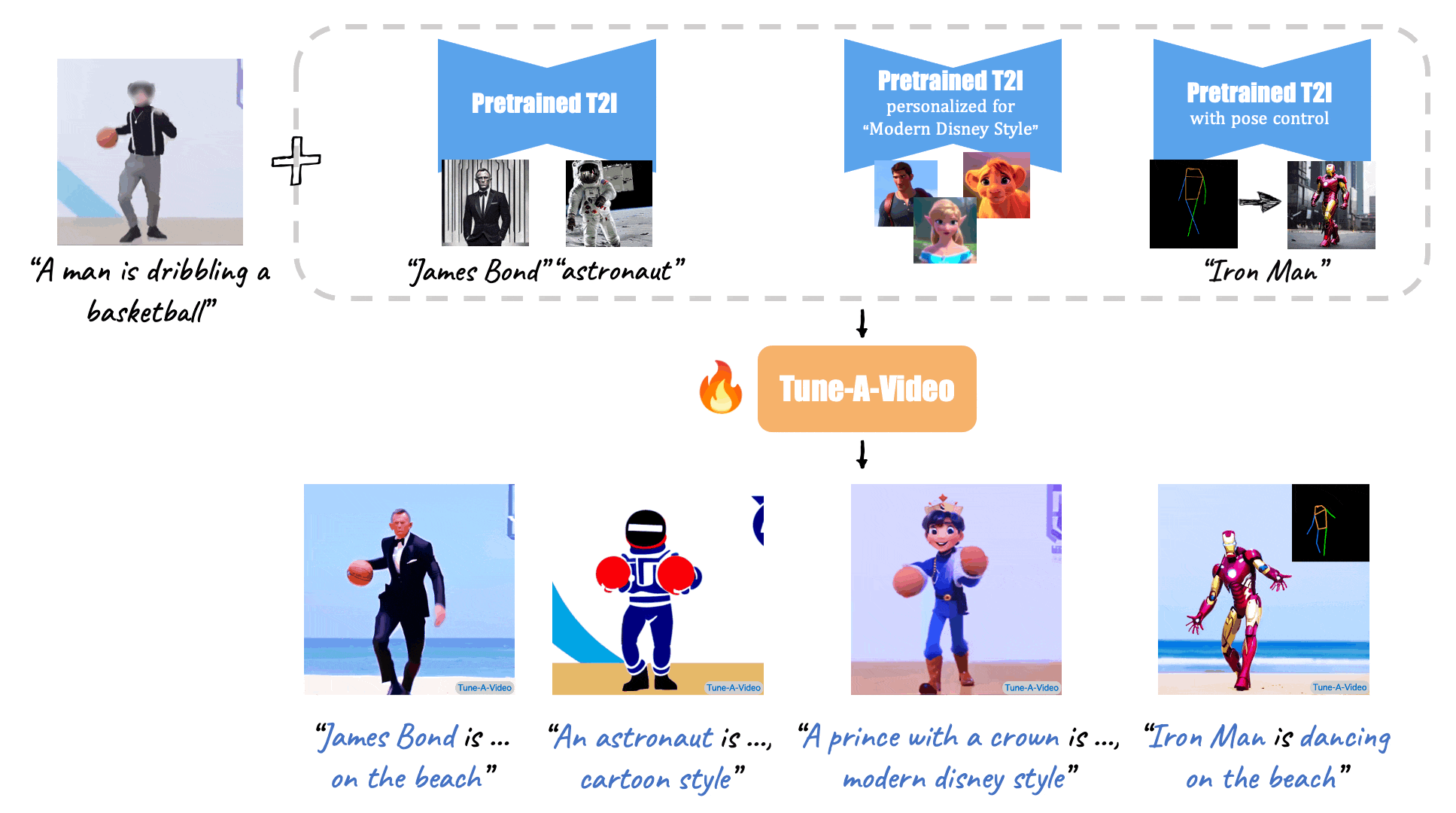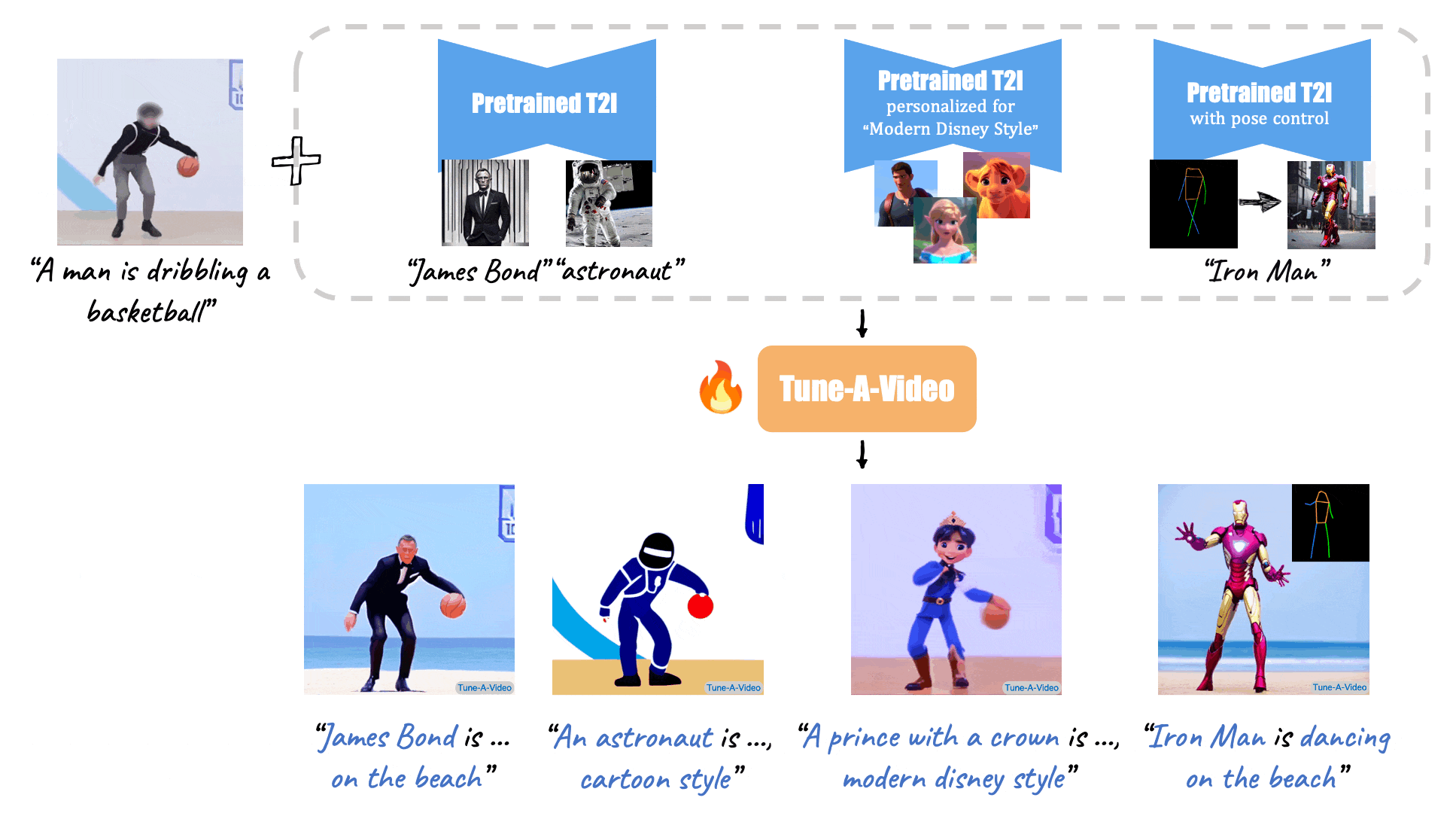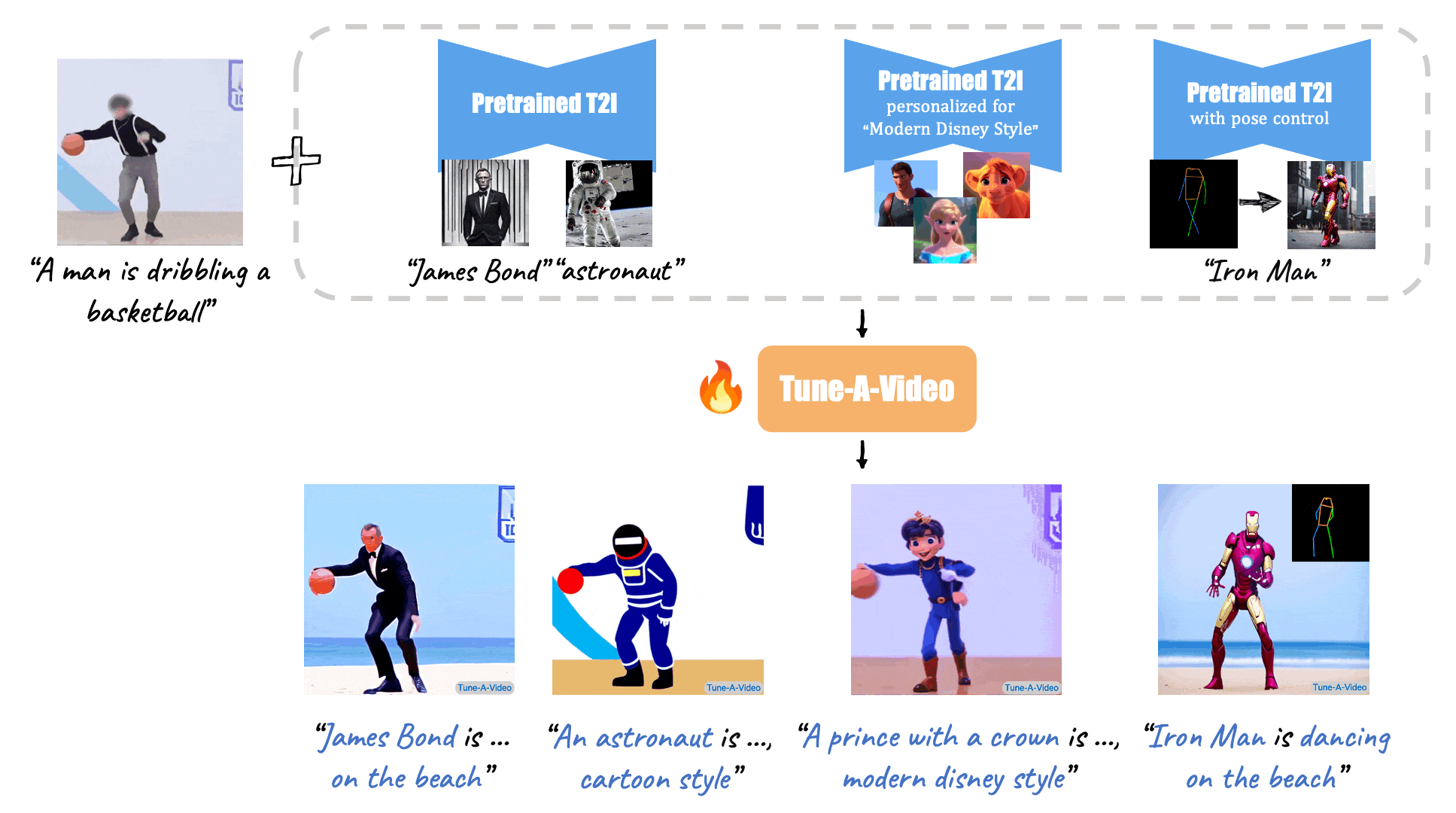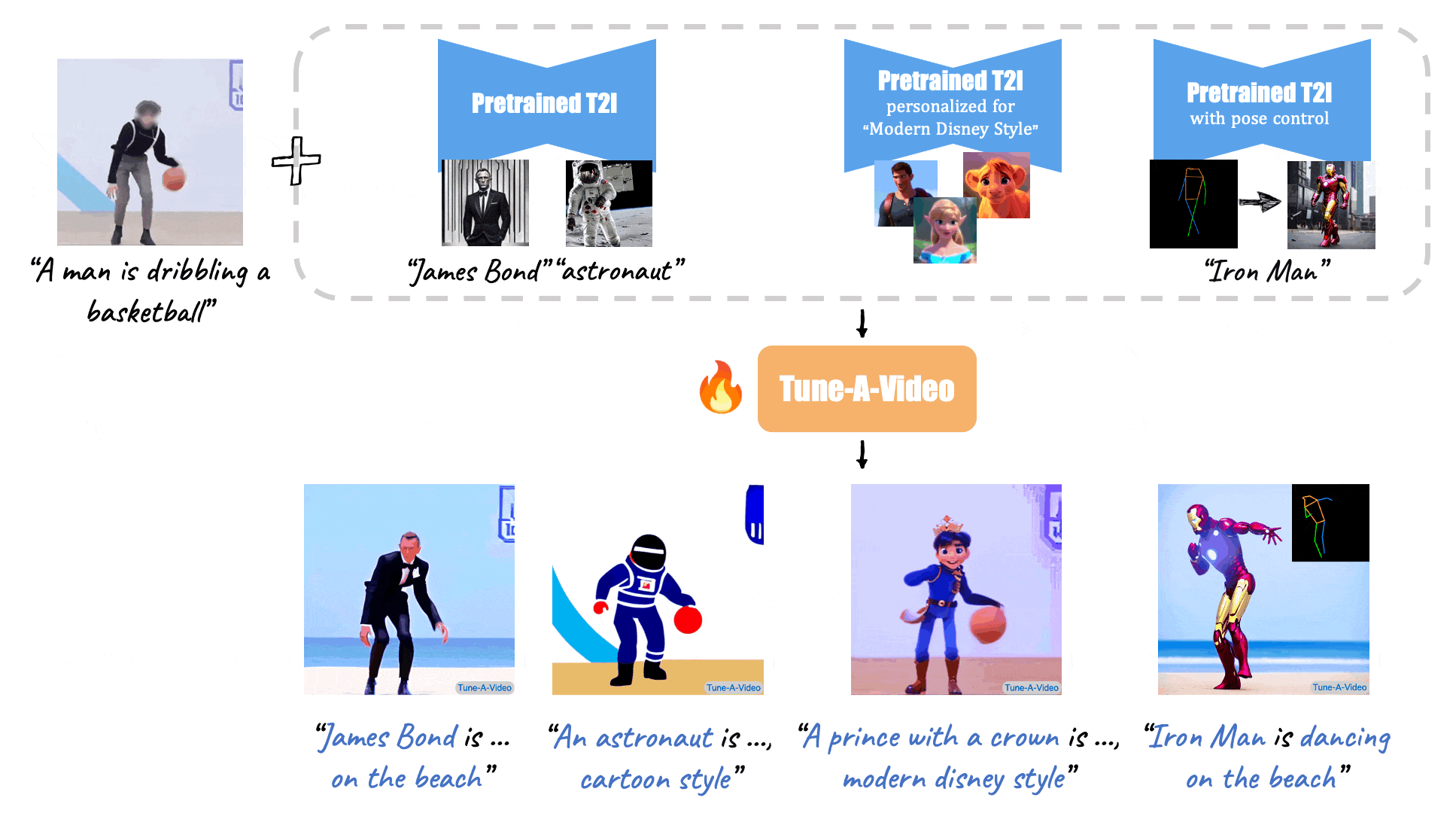
Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.
Open-VCLIP
Paper: Open-VCLIP: Transforming CLIP to an Open-vocabulary Video Model via Interpolated Weight Optimization
Paper: Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Code: https://github.com/wengzejia1/Open-VCLIP/

DyST
Paper: DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
Text-to-Motion
TMR
Paper: TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis
Code: https://github.com/Mathux/TMR
Text-to-Motion Retrieval
Paper: Text-to-Motion Retrieval: Towards Joint Understanding of Human Motion Data and Natural Language
Code: https://github.com/mesnico/text-to-motion-retrieval
A person walks in a counterclockwise circle

A person is kneeling down on all four legs and begins to crawl

MotionDirector
Paper: MotionDirector: Motion Customization of Text-to-Video Diffusion Models
GPT4Motion
Paper: GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning
Motion Editing
Paper: Iterative Motion Editing with Natural Language
Text-to-Video
Awesome Video Diffusion Models
Stable Diffusion Video
Paper: Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Code: https://github.com/nateraw/stable-diffusion-videos

AnimateDiff
Paper: AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Paper: SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models
Code: https://github.com/guoyww/AnimateDiff

Animate Anyone
Paper: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
StyleCrafter
Paper: StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
Code: https://github.com/GongyeLiu/StyleCrafter

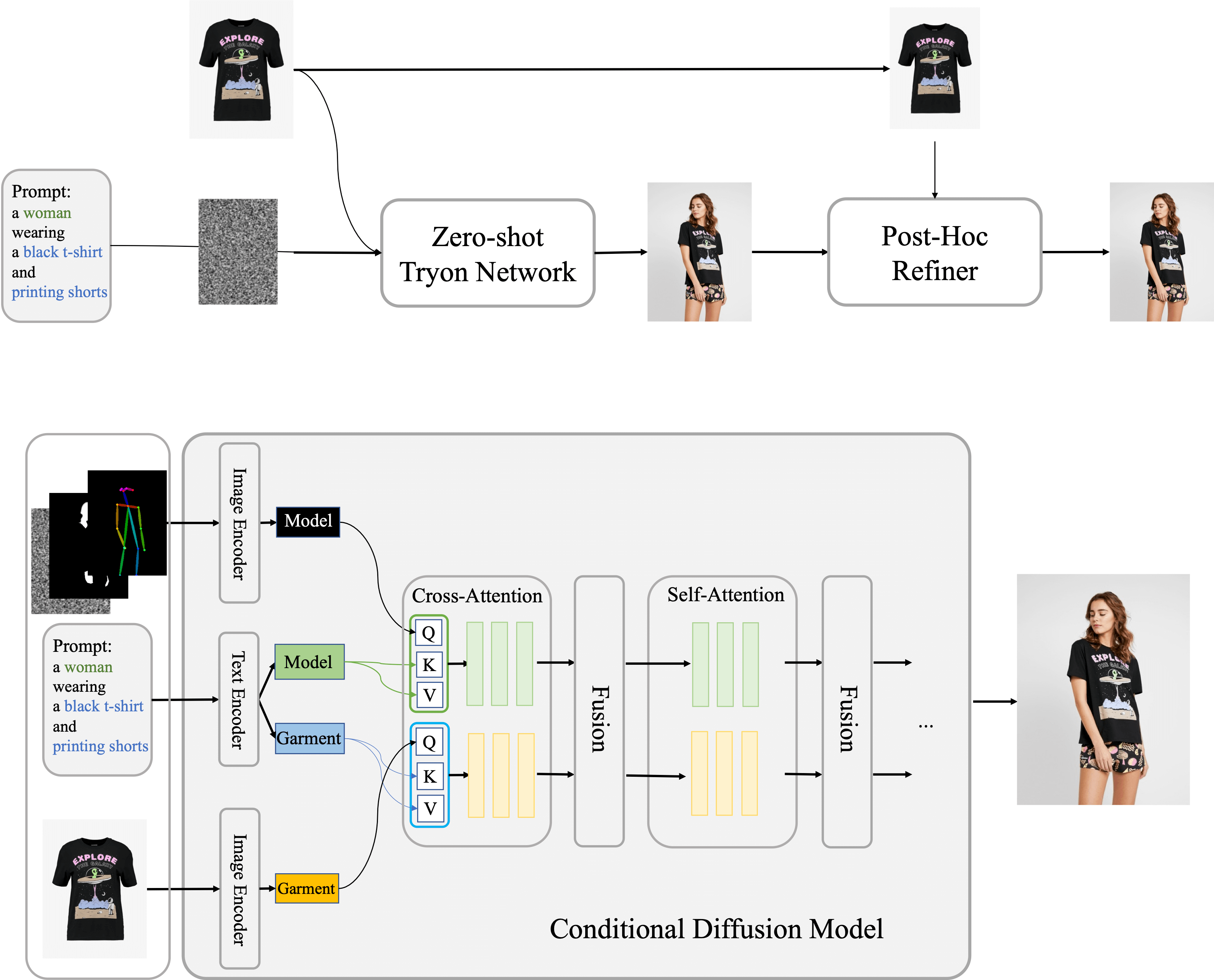
Outfit Anyone
Paper: OutfitAnyone: Ultra-high Quality Virtual Try-On for Any Clothing and Any Person
Code: https://github.com/HumanAIGC/OutfitAnyone


Sora
Paper: Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models

AIF for Dynamic T2V
Paper: Improving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback

OpenAI Sora2
LTX-Video
Paper: LTX-Video: Realtime Video Latent Diffusion

![]()
Open-Sora
Paper: Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Code: https://github.com/hpcaitech/Open-Sora


WAN 2.2
Paper: Wan: Open and Advanced Large-Scale Video Generative Models
Github: https://github.com/Wan-Video/Wan2.2
ComfyUI + WAN2.2
Multi-Talk
Paper: Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
Code: https://github.com/MeiGen-AI/MultiTalk

InfiniteTalk
Paper: InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Code: https://github.com/MeiGen-AI/InfiniteTalk

Wan-S2V
HuggingFace: Wan-AI/Wan2.2-S2V-14B
Paper: Wan-S2V: Audio-Driven Cinematic Video Generation
UniVerse-1
Paper: UniVerse-1: Unified Audio-Video Generation via Stitching of Experts
Code: https://github.com/Dorniwang/UniVerse-1-code/

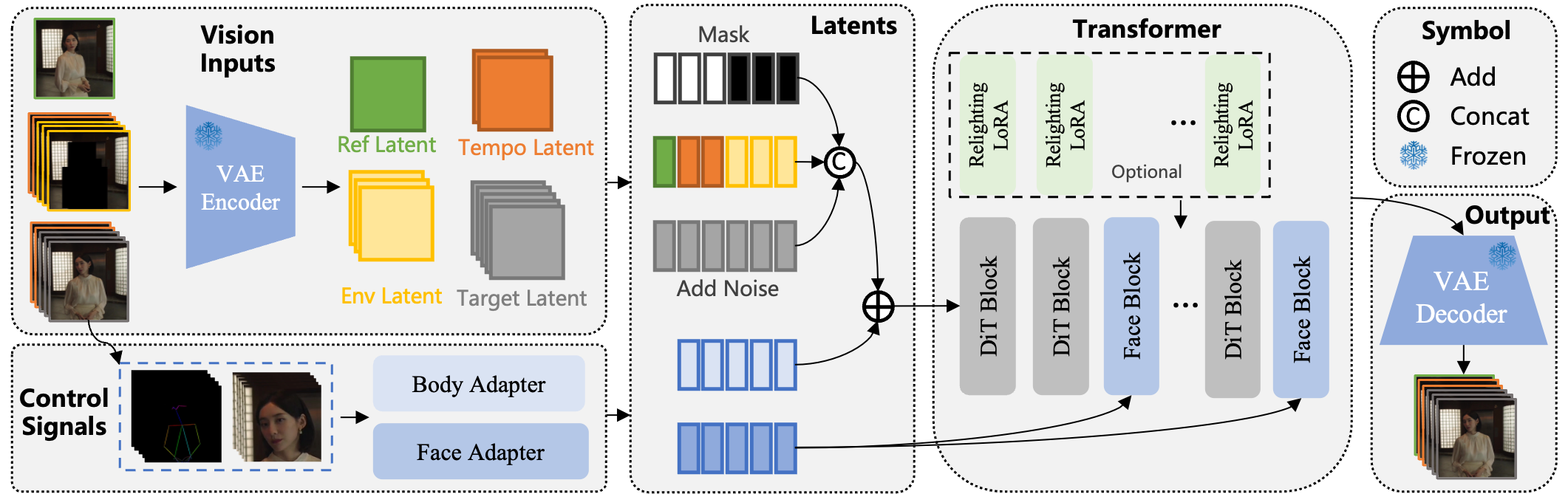
Wan-Animate
Paper: Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
VEO 3
Paper: Video models are zero-shot learners and reasoners
Sora2
FlashVSR
Paper: FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution
Code: https://github.com/OpenImagingLab/FlashVSR

Runway Gen-4.5
Kling 3.0
SeedDance 2.0
LTX-2.3
Blog: Lightricks 發布 LTX 2.3 開源影片生成模型,可在本地端製作 4K 50FPS 同步音訊 AI 影片
- 首先,文字編碼器規模擴大 4 倍,大幅提升提示詞理解能力,能精確呈現攝影機運動、構圖和角色動作,讓生成結果更符合創作者的預期。
- 全新設計的 VAE(變分自編碼器)提供更清晰的細節和更穩定的運動畫質,有效改善前代作品常見的畫面模糊問題。也支援 Lora 可進行影片風格轉換功能。
- 圖像轉影片(I2V)功能從訓練階段即整合至模型架構中,顯著減少畫面停滯現象,並降低所謂的「肯納伯斯效應」(can nabs effect),使連續幀之間的過渡更加自然,而且也支援首尾幀功能與原生直橫格式影片生成。
- 音訊品質同步提升,是目前開源模型中少數支援音畫同時生成的本地端模型。新型 vocoder 降低背景雜音並強化音畫同步,解決過往 AI 生成的影片常見的音訊延遲或不同步問題。大家可以看看官方所釋出的宣傳影片,效果相當驚艷(以開源模型來說)
World Models
SANA-WM
Paper: SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
Code: https://github.com/NVlabs/Sana

This site was last updated May 30, 2026.