Generative Video
Image-to-Video
Turn-A-Video
Paper: Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Code: https://github.com/showlab/Tune-A-Video
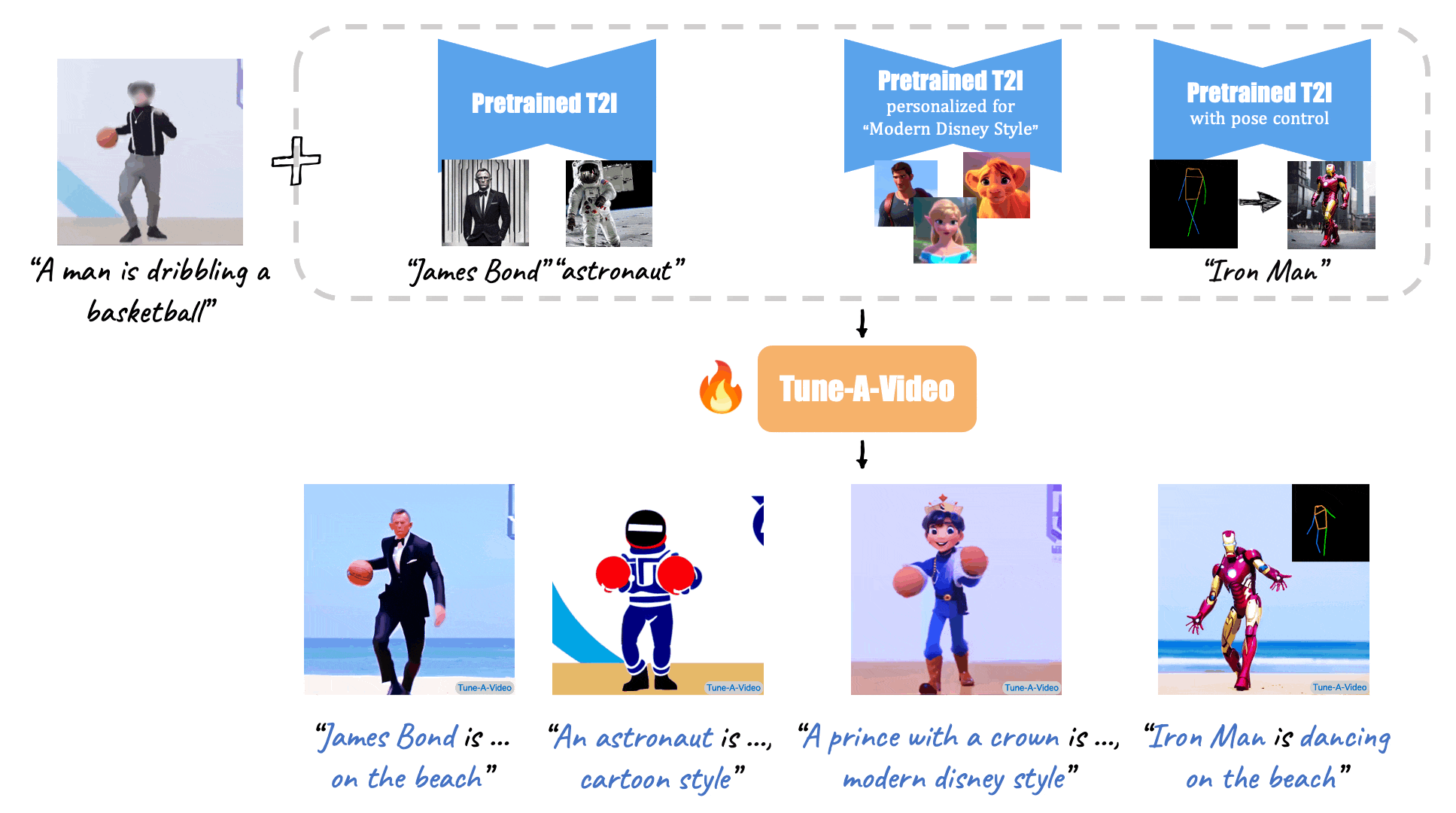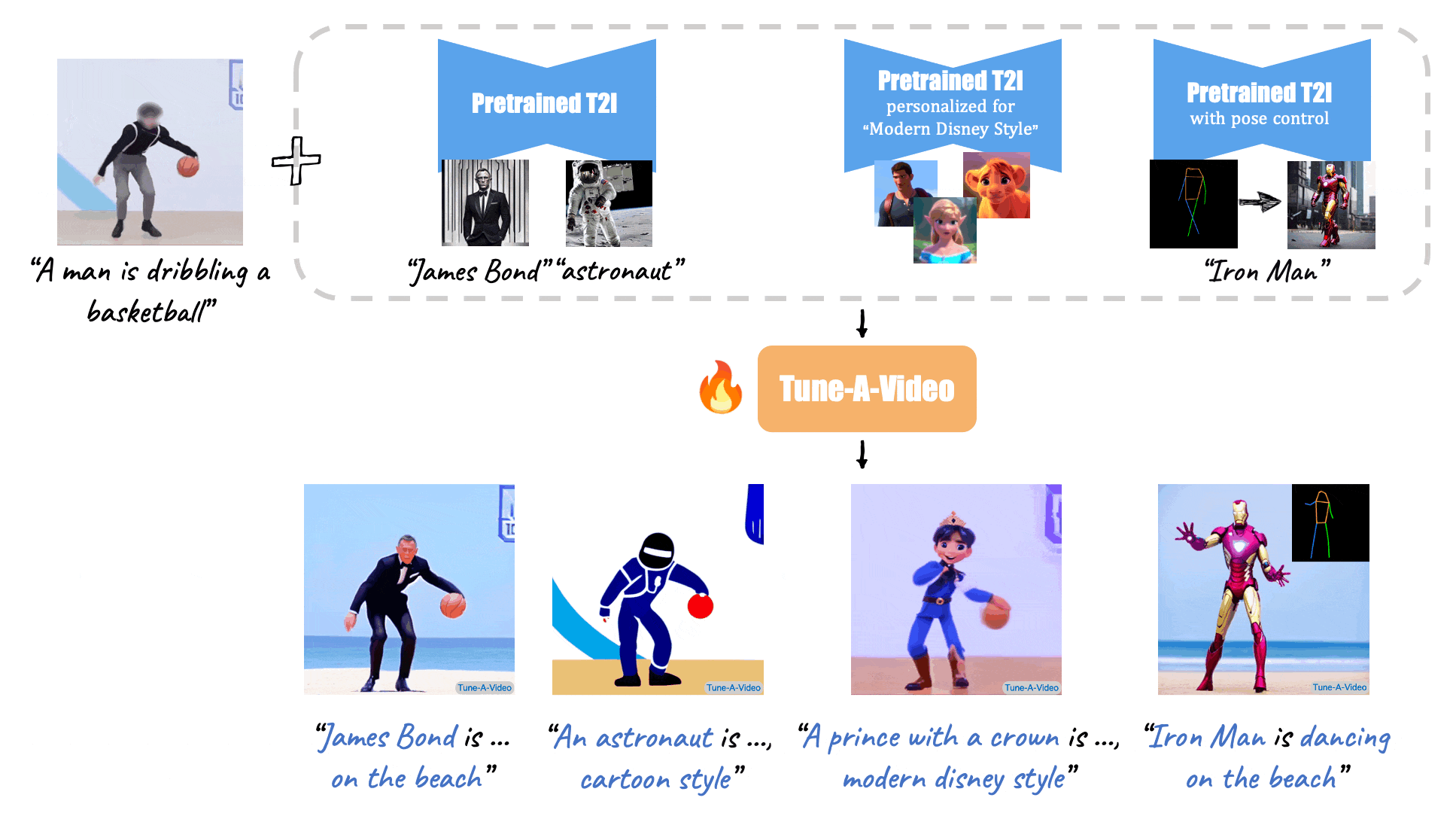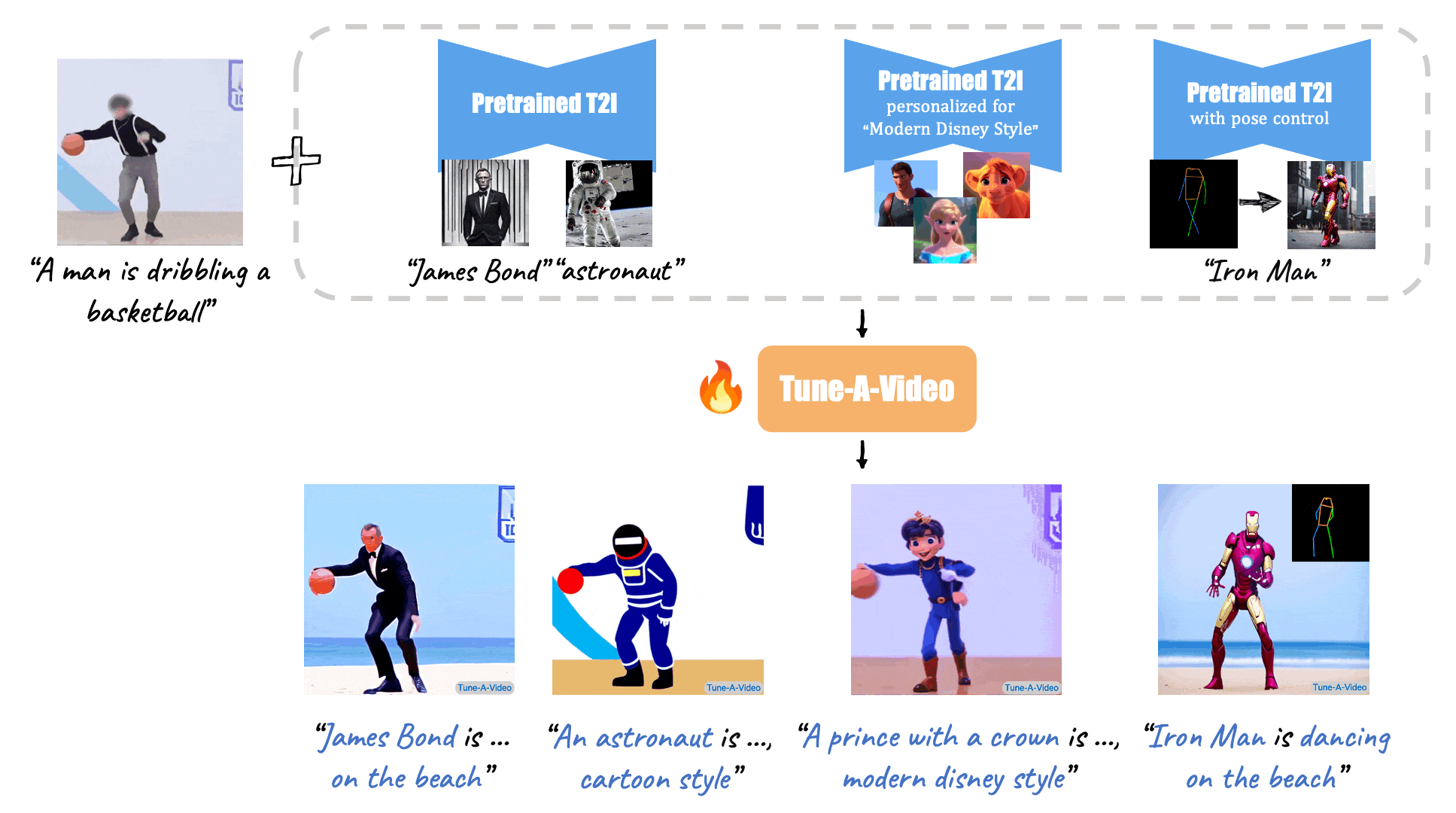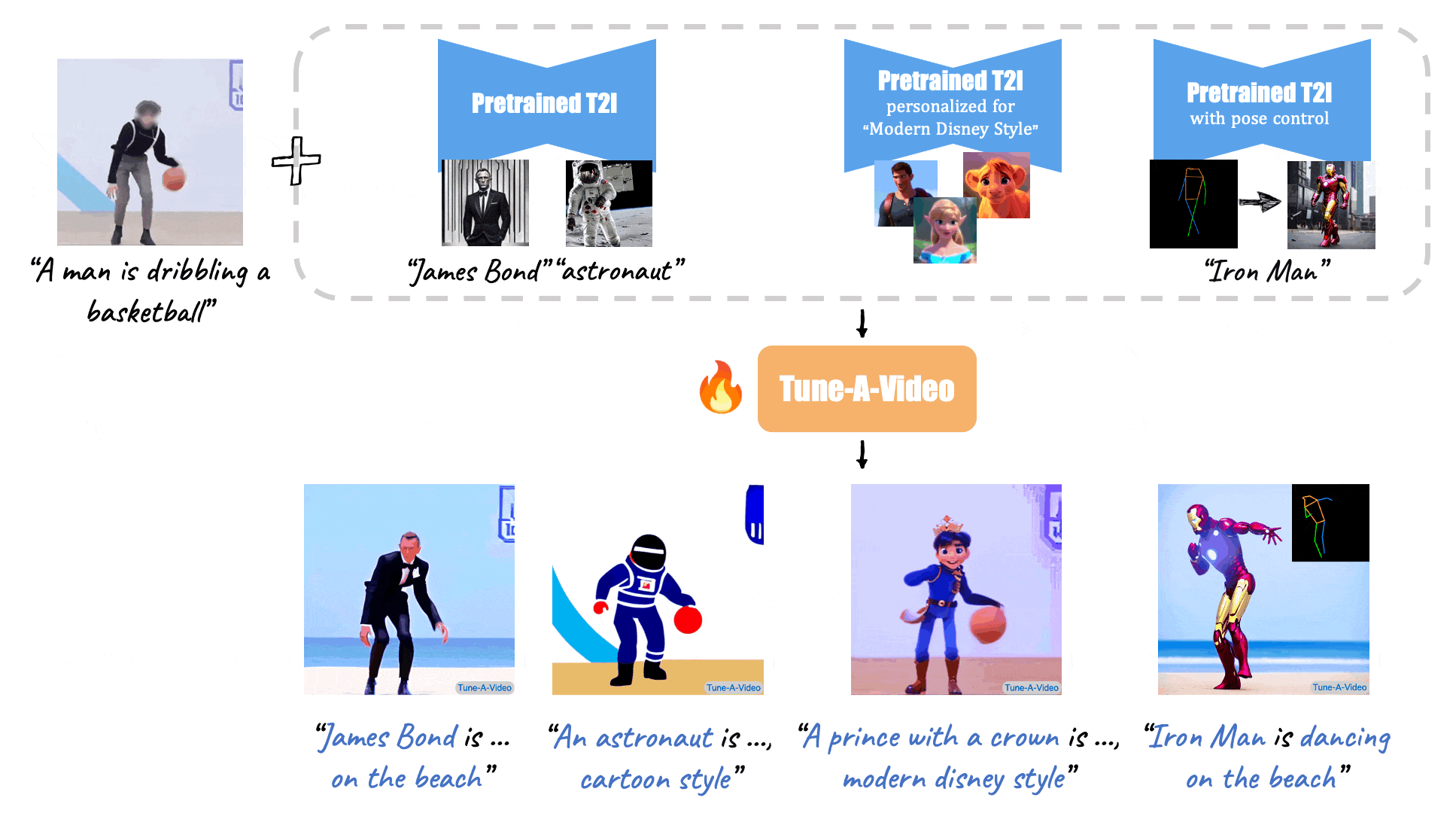
Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.
Open-VCLIP
Paper: Open-VCLIP: Transforming CLIP to an Open-vocabulary Video Model via Interpolated Weight Optimization
Paper: Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Code: https://github.com/wengzejia1/Open-VCLIP/

DyST
Paper: DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
Text-to-Motion
TMR
Paper: TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis
Code: https://github.com/Mathux/TMR
Text-to-Motion Retrieval
Paper: Text-to-Motion Retrieval: Towards Joint Understanding of Human Motion Data and Natural Language
Code: https://github.com/mesnico/text-to-motion-retrieval
A person walks in a counterclockwise circle

A person is kneeling down on all four legs and begins to crawl

MotionDirector
Paper: MotionDirector: Motion Customization of Text-to-Video Diffusion Models
GPT4Motion
Paper: GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning
Motion Editing
Paper: Iterative Motion Editing with Natural Language
Text-to-Video
Awesome Video Diffusion Models
Stable Diffusion Video
Paper: Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Code: https://github.com/nateraw/stable-diffusion-videos

AnimateDiff
Paper: AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Paper: SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models
Code: https://github.com/guoyww/AnimateDiff

Animate Anyone
Paper: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
StyleCrafter
Paper: StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
Code: https://github.com/GongyeLiu/StyleCrafter

Outfit Anyone
Code: https://github.com/HumanAIGC/OutfitAnyone
SignLLM
Paper: SignLLM: Sign Languages Production Large Language Models
Code: https://github.com/SignLLM/Prompt2Sign
AIF for Dynamic T2V
Paper: Improving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback

VEO3
Flow
Meet Flow: AI-powered filmmaking with Veo 3
Wan2.2
Arxiv: Wan: Open and Advanced Large-Scale Video Generative Models
Github: https://github.com/Wan-Video/Wan2.2
ComfyUI + WAN2.2
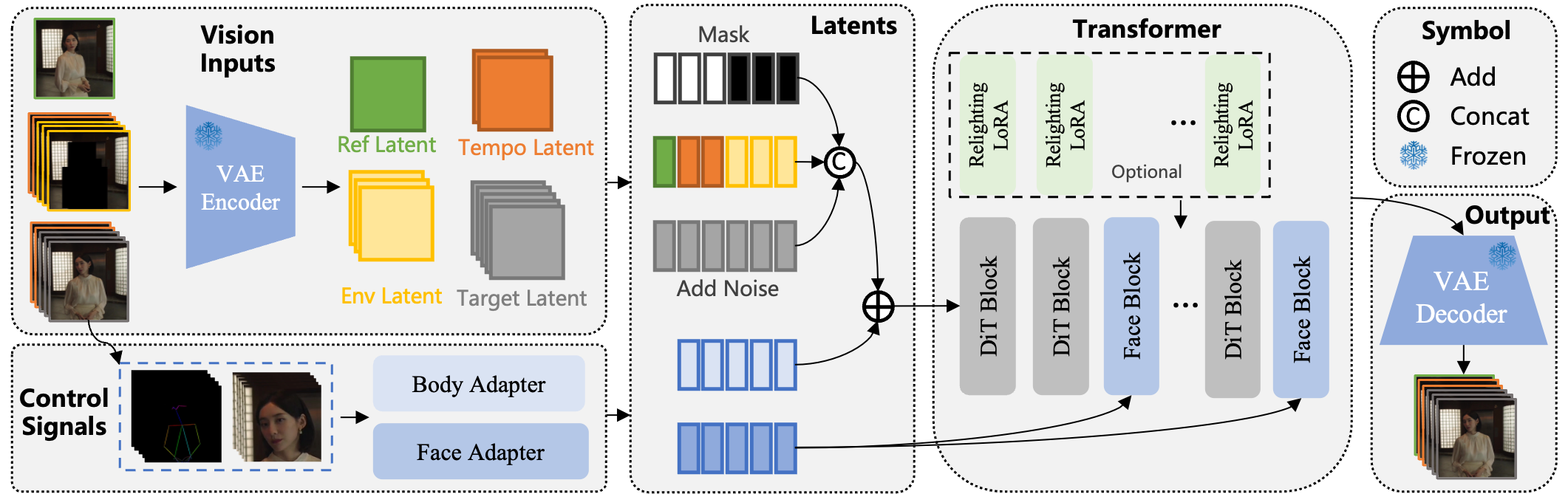
Wan-Animate
HuggingFace: Wan-AI/Wan2.2-Animate-14B
Arxiv: Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Demo: https://huggingface.co/spaces/Wan-AI/Wan2.2-Animate
Audio-to-Video
Multi-Talk
Paper: Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
Code: https://github.com/MeiGen-AI/MultiTalk

InfiniteTalk
Paper: InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Code: https://github.com/MeiGen-AI/InfiniteTalk

Wan-S2V
HuggingFace: Wan-AI/Wan2.2-S2V-14B
Arxiv: Wan-S2V: Audio-Driven Cinematic Video Generation
Demo: https://huggingface.co/spaces/Wan-AI/Wan2.2-S2V
UniVerse-1
Paper: UniVerse-1: Unified Audio-Video Generation via Stitching of Experts
 Code: https://github.com/Dorniwang/UniVerse-1-code/
Code: https://github.com/Dorniwang/UniVerse-1-code/
This site was last updated October 16, 2025.