Generative Speech
Introduction to Text-To-Speech, Voice Cloning, Voice Conversion, Automatic Speech Recognition(ASR).
Text-To-Speech (using TTS)
WaveNet
Paper: WaveNet: A Generative Model for Raw Audio
Code: r9y9/wavenet_vocoder
With a pre-trained model provided here, you can synthesize waveform given a mel spectrogram, not raw text.
You will need mel-spectrogram prediction model (such as Tacotron2) to use the pre-trained models for TTS.
Demo: An open source implementation of WaveNet vocoder
Blog: WaveNet: A generative model for raw audio

Tacotron-2
Paper: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Code: Rayhane-mamah/Tacotron-2
Code: Tacotron 2 (without wavenet)

Few-shot Transformer TTS
Paper: Multilingual Byte2Speech Models for Scalable Low-resource Speech Synthesis
Code: https://github.com/mutiann/few-shot-transformer-tts
MetaAudio
Paper: MetaAudio: A Few-Shot Audio Classification Benchmark
Code: MetaAudio-A-Few-Shot-Audio-Classification-Benchmark
Dataset: ESC-50, NSynth, FSDKaggle18, BirdClef2020, VoxCeleb1
SeamlessM4T
Paper: SeamlessM4T: Massively Multilingual & Multimodal Machine Translation
Code: https://github.com/facebookresearch/seamless_communication
Colab: seamless_m4t_colab
app.py
Stable-TTS
Paper: Stable-TTS: Stable Speaker-Adaptive Text-to-Speech Synthesis via Prosody Prompting
 Demo: https://huggingface.co/spaces/KdaiP/StableTTS1.1
Demo: https://huggingface.co/spaces/KdaiP/StableTTS1.1
Audiobox Aesthetics
Paper: Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Github: https://github.com/facebookresearch/audiobox-aesthetics

Spark-TTS
Paper: Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Github: https://github.com/SparkAudio/Spark-TTS
Inference Overview of Voice Cloning
 Inference Overview of Controlled Generation
Inference Overview of Controlled Generation

Kaggle: https://www.kaggle.com/code/rkuo2000/spark-tts
T2S
Paper: T2S: High-resolution Time Series Generation with Text-to-Series Diffusion Models

IndexTTS2
Paper: IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech

 Github: https://github.com/index-tts/index-tts
Github: https://github.com/index-tts/index-tts
FireRedTTS-2
Paper: FireRedTTS-2: Towards Long Conversational Speech Generation for Podcast and Chatbot
HuggingFace: FireRedTeam/FireRedTTS2https
Github: https://github.com/FireRedTeam/FireRedTTS2

Voice Conversion
Paper: An Overview of Voice Conversion and its Challenges: From Statistical Modeling to Deep Learning

Blog: Voice Cloning Using Deep Learning
Voice Cloning
Paper: Voice Cloning: Comprehensive Survey


SV2TTS
Blog: Voice Cloning: Corentin’s Improvisation On SV2TTS
Paper: Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Code: CorentinJ/Real-Time-Voice-Cloning
Synthesizer : The synthesizer is Tacotron2 without Wavenet
SV2TTS Toolbox
NeMO
Nemo ASR
Automatic Speech Recognition (ASR)
RVC vs SoftVC
“Retrieval-based Voice Conversion” 和 “SoftVC VITS Singing Voice Conversion” 是兩種聲音轉換技術的不同變種。以下是它們之間的一些區別:
1.方法原理:
Retrieval-based Voice Conversion:這種方法通常涉及使用大規模的語音資料庫或語音庫,從中檢索與輸入語音相似的聲音樣本,並將輸入語音轉換成與檢索到的聲音樣本相似的聲音。它使用檢索到的聲音作為目標來進行聲音轉換。
SoftVC VITS Singing Voice Conversion:這是一種基於神經網路的聲音轉換方法,通常使用變分自動編碼器(Variational Autoencoder,VAE)或其他神經網路架構。專注於歌聲轉換,它的目標是將輸入歌聲樣本轉換成具有不同特徵的歌聲,例如性別、音調等。
2.應用領域:
Retrieval-based Voice Conversion 通常用於語音轉換任務,例如將一個人的語音轉換成另一個人的語音。它也可以用於歌聲轉換,但在歌聲轉換方面通常不如專門設計的方法表現出色。
SoftVC VITS Singing Voice Conversion 主要用於歌聲轉換任務,特別是針對歌手之間的音樂聲音特徵轉換,例如將男性歌手的聲音轉換成女性歌手的聲音,或者改變歌曲的音調和音樂特徵。
3.技術複雜性:
Retrieval-based Voice Conversion 的實現通常較為簡單,因為它主要依賴於聲音樣本的檢索和聲音特徵的映射。
SoftVC VITS Singing Voice Conversion 更複雜,因為它需要訓練深度神經網路模型,可能需要大量的數據和計算資源。
Retrieval-based Voice Conversion
Blog: RVC-WebUI開源專案教學
Code: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
GPT-SoVITS
Blog: GPT-SoVITS 用 AI 快速複製你的聲音,搭配 Colab 免費入門
Code: https://github.com/RVC-Boss/GPT-SoVITS/
Kaggle: https://www.kaggle.com/code/rkuo2000/so-vits-svc-5-0
VITS SVC
Variational Inference with adversarial learning for end-to-end Singing Voice Conversion based on VITS
Github: https://github.com/PlayVoice/whisper-vits-svc
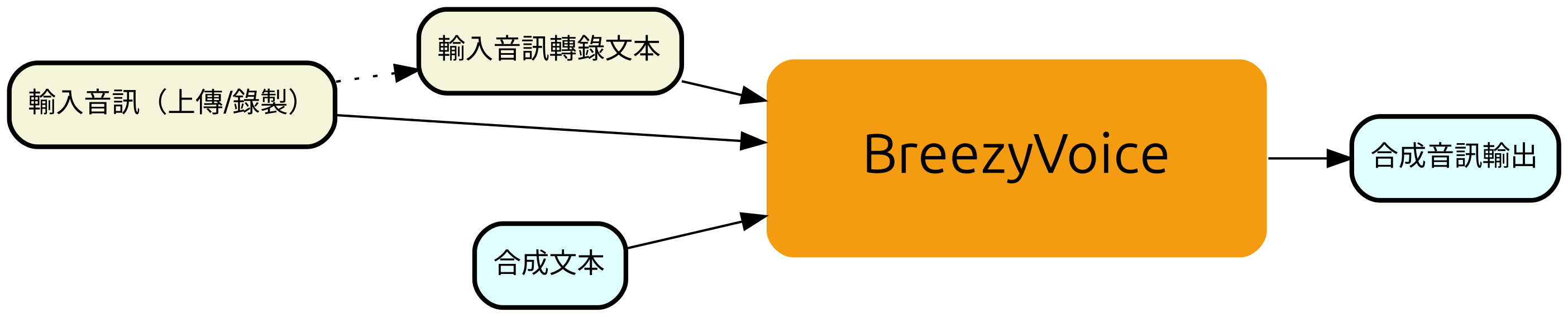
BreezyVoice
Paper: BreezyVoice: Adapting TTS for Taiwanese Mandarin with Enhanced Polyphone Disambiguation – Challenges and Insights
Code: https://github.com/mtkresearch/BreezyVoice
Speech Seperation
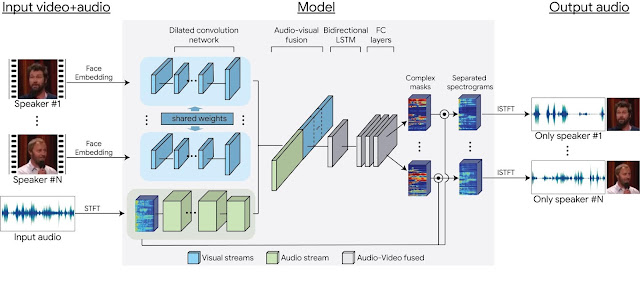
Looking to Listen
Paper: Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
Blog: Looking to Listen: Audio-Visual Speech Separation
VoiceFilter
Paper: VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Github: https://github.com/maum-ai/voicefilter
Training took about 20 hours on AWS p3.2xlarge(NVIDIA V100)

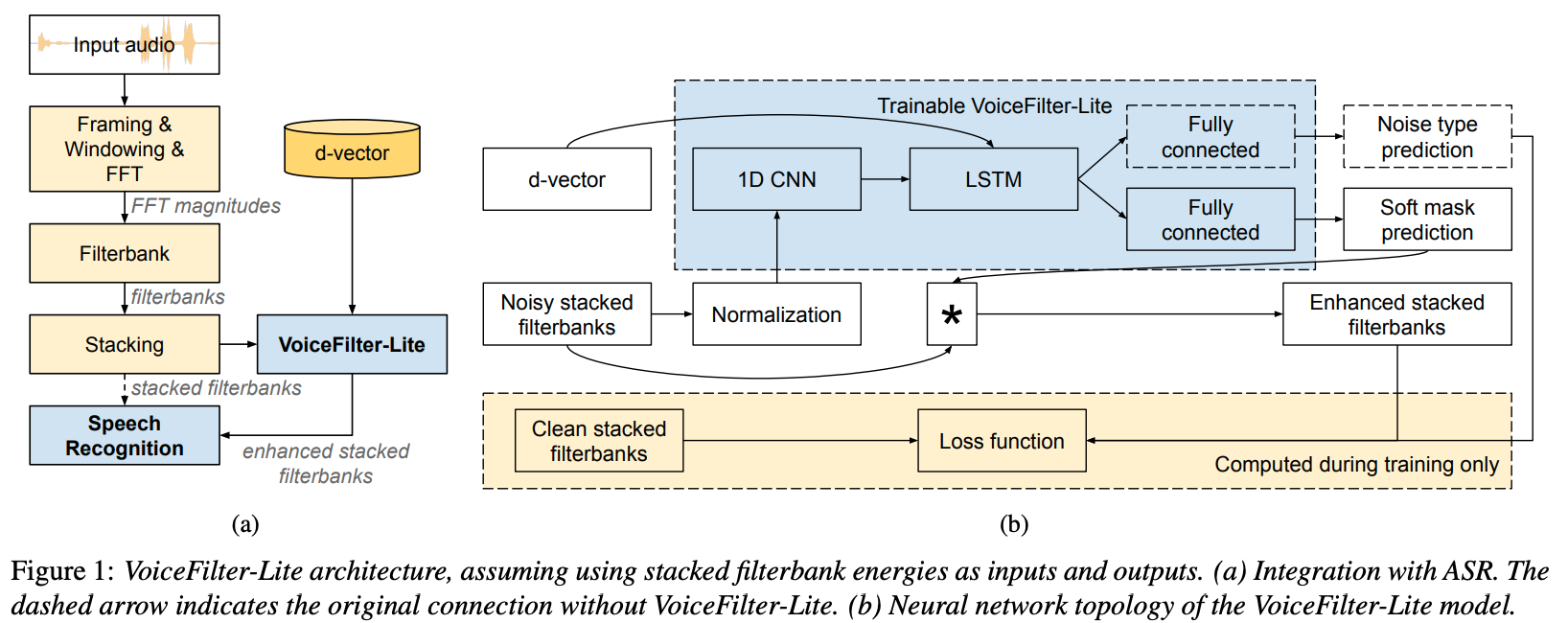
VoiceFilter-Lite
Paper: VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Blog:
Automatic Speech Recognition (ASR)
Whisper
Paper: Robust Speech Recognition via Large-Scale Weak Supervision
 Kaggle: https://www.kaggle.com/code/rkuo2000/whisper
Kaggle: https://www.kaggle.com/code/rkuo2000/whisper
Faster-Whisper
faster-whisper is a reimplementation of OpenAI’s Whisper model using CTranslate2, which is a fast inference engine for Transformer models.
Kaggle: https://www.kaggle.com/code/rkuo2000/faster-whisper
Open Whisper-style Speech Models (OWSM)
Paper: OWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
Qwen-Audio
Github: https://github.com/QwenLM/Qwen-Audio

Meta SpiritLM
Paper: Spirit LM: Interleaved Spoken and Written Language Model
Blog: Meta開源首個多模態語言模型Meta Spirit LM
Github: https://github.com/facebookresearch/spiritlm

Canary
model: nvidia/canary-1b
Paper: Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Whisper Large-v3
model: openai/whisper-large-v3
model: openai/whisper-large-v3-turbo
Kaggle: https://www.kaggle.com/code/rkuo2000/whisper-large-v3-turbo
This site was last updated October 02, 2025.