Generative Speech
Text-To-Speech (using TTS)
WaveNet
Paper: WaveNet: A Generative Model for Raw Audio

Code: https://github.com/r9y9/wavenet_vocoder
Colab: Tacotron2_and_WaveNet_text_to_speech_demo.ipynb
Tacotron-2
Paper: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Code: https://github.com/Rayhane-mamah/Tacotron-2
Code: Tacotron 2 (without wavenet)

Few-shot Transformer TTS
Paper: Multilingual Byte2Speech Models for Scalable Low-resource Speech Synthesis
Code: https://github.com/mutiann/few-shot-transformer-tts
MetaAudio
Paper: MetaAudio: A Few-Shot Audio Classification Benchmark
Code: MetaAudio-A-Few-Shot-Audio-Classification-Benchmark
Dataset: ESC-50, NSynth, FSDKaggle18, BirdClef2020, VoxCeleb1
SeamlessM4T
Paper: SeamlessM4T: Massively Multilingual & Multimodal Machine Translation
Code: https://github.com/facebookresearch/seamless_communication
Colab: seamless_m4t_colab
Audiobox Aesthetics
Paper: Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Code: https://github.com/facebookresearch/audiobox-aesthetics

SV2TTS
Paper: Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Code: CorentinJ/Real-Time-Voice-Cloning
Spark-TTS
Paper: Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Code: https://github.com/SparkAudio/Spark-TTS
-
Inference Overview of Voice Cloning

-
Inference Overview of Controlled Generation

ComfyUI: https://github.com/billwuhao/ComfyUI_SparkTTS
Kaggle: rkuo2000/Spark-TTS
IndexTTS2
Paper: IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech


Code: https://github.com/index-tts/index-tts
ComfyUI: https://github.com/billwuhao/ComfyUI_IndexTTS
Kaggle: rkuo2000/Index-TTS2
VibeVoice
Paper: VibeVoice Technical Report
model: microsoft/VibeVoice-1.5B
Code: https://github.com/microsoft/VibeVoice

ComfyUI: https://github.com/Enemyx-net/VibeVoice-ComfyUI
FireRedTTS-2
Paper: FireRedTTS-2: Towards Long Conversational Speech Generation for Podcast and Chatbot
Code: https://github.com/FireRedTeam/FireRedTTS2

ComfyUI: https://github.com/1038lab/ComfyUI-FireRedTTS
VoxCPM
Paper: VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning
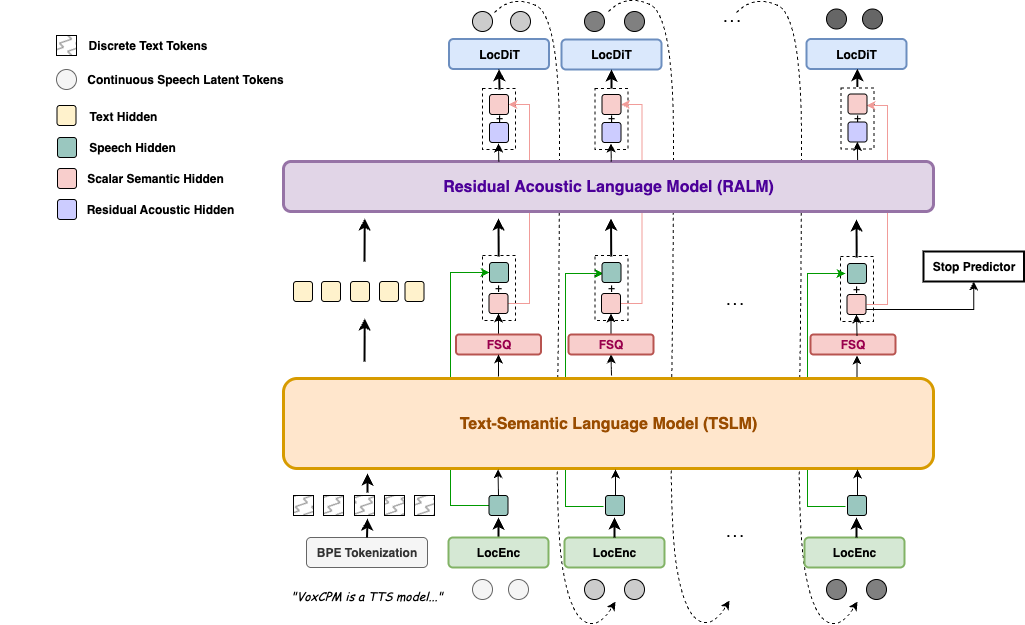
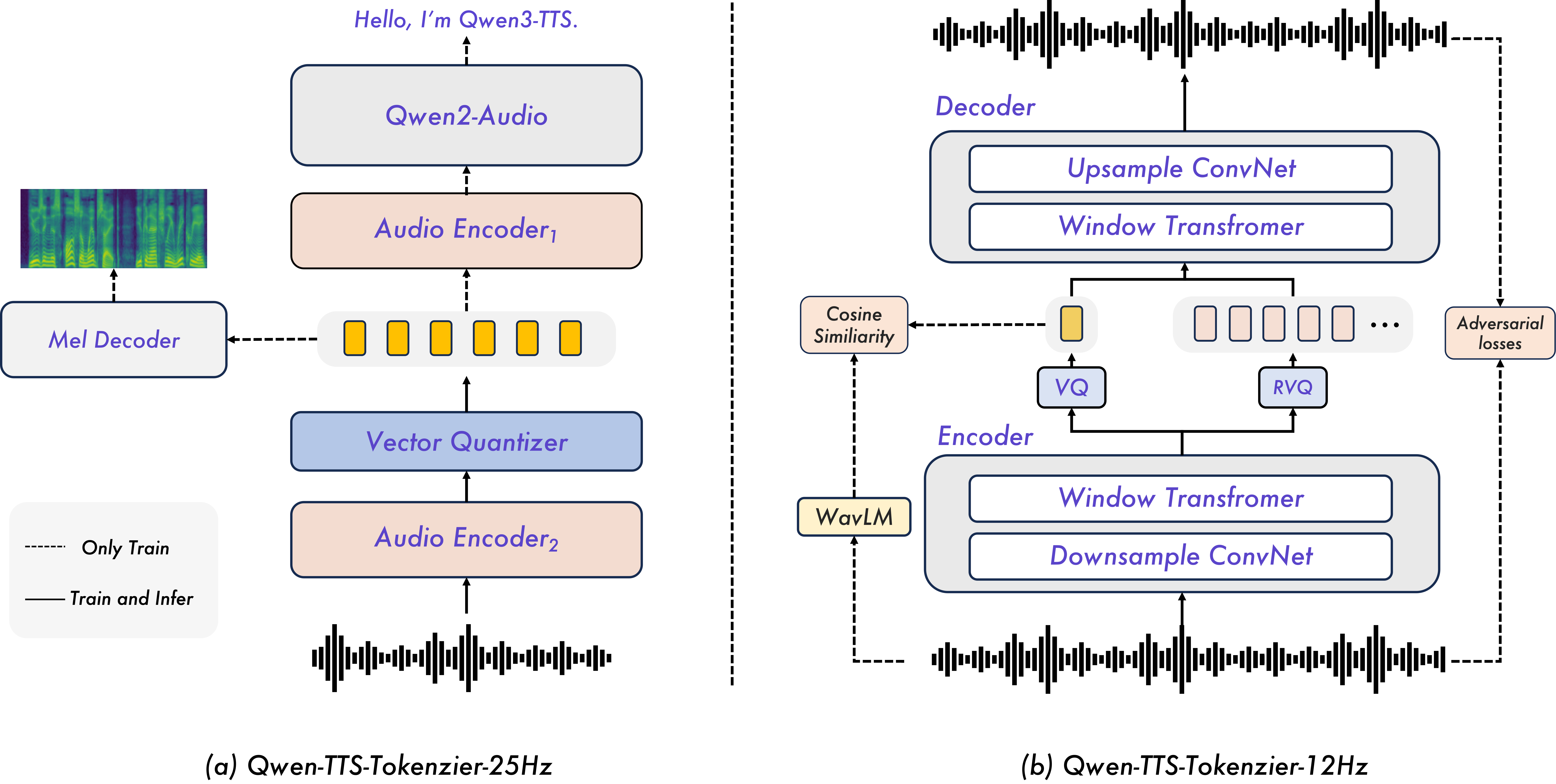
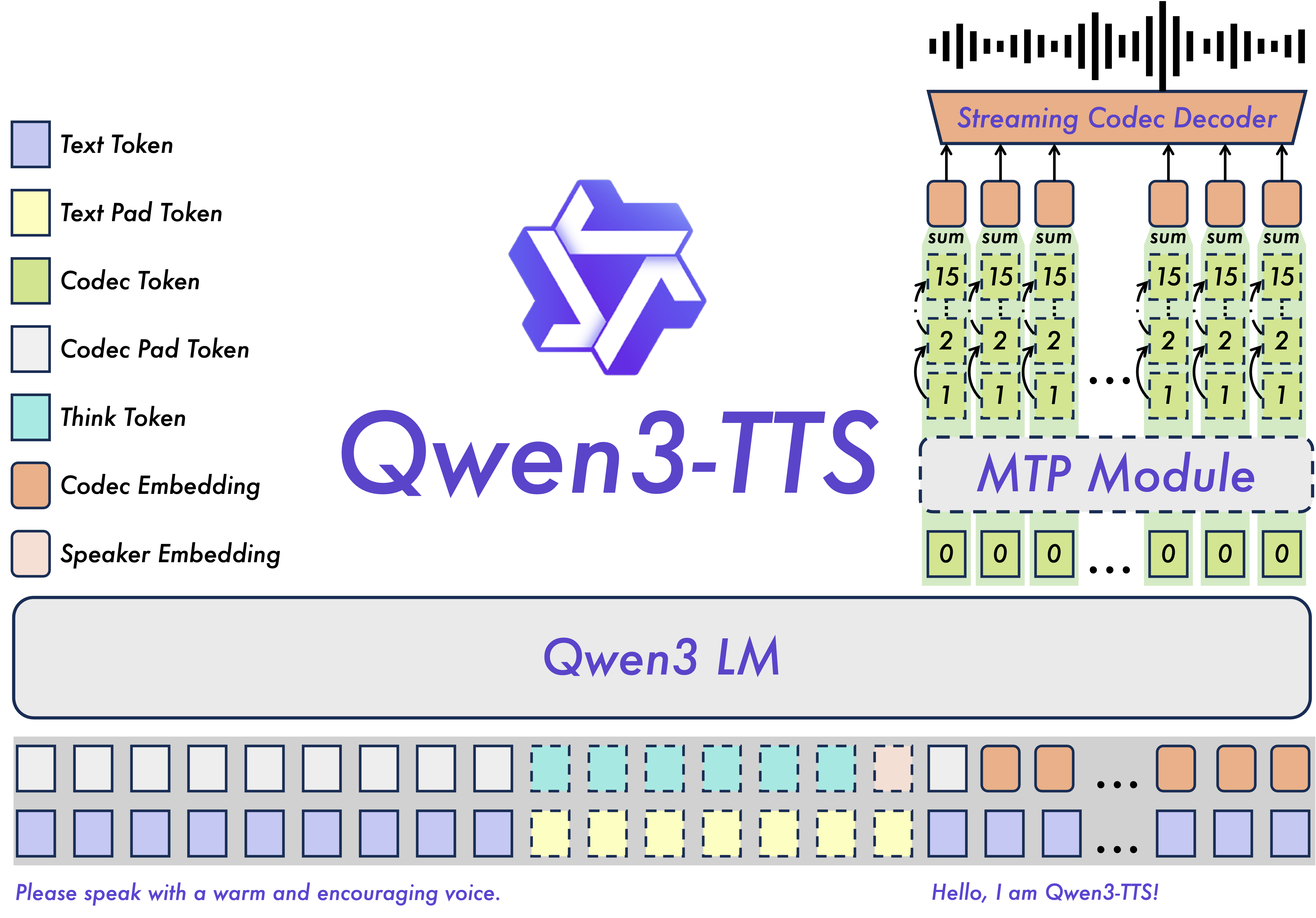
Qwen3-TTS
Paper: Qwen3-TTS Technical Report
Code: https://github.com/QwenLM/Qwen3-TTS
PersonaPlex
Paper: PersonaPlex: Voice and Role Control for Full Duplex Conversational Speech Models
Blog: NVIDIA PersonaPlex:開源全雙工語音新紀元,打造零停頓的真正 AI 對話
Code: https://github.com/NVIDIA/personaplex

VoxCPM2
Blog: VoxCPM2 開源語音模型實測:清華團隊 20 億參數 TTS 在相似度基準上大幅領先 ElevenLabs
Code: https://github.com/OpenBMB/VoxCPM

Voice Cloning
Paper: Voice Cloning: Comprehensive Survey

RVC-WebUI
Code: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
AI 用你的聲音創建歌詞曲
GPT-SoVITS
Blog: GPT-SoVITS 用 AI 快速複製你的聲音,搭配 Colab 免費入門
Code: https://github.com/RVC-Boss/GPT-SoVITS/
Kaggle: rkuo2000/so-vits-svc-5-0
VITS SVC
Variational Inference with adversarial learning for end-to-end Singing Voice Conversion based on VITS
Code: https://github.com/PlayVoice/whisper-vits-svc
Speech Seperation
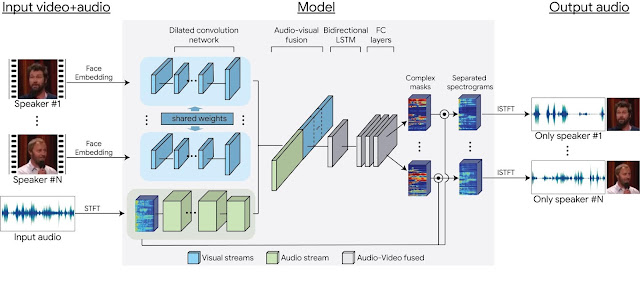
Looking to Listen
Paper: Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
Blog: Looking to Listen: Audio-Visual Speech Separation
VoiceFilter
Paper: VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Code: https://github.com/maum-ai/voicefilter
Training took about 20 hours on AWS p3.2xlarge(NVIDIA V100)

VoiceFilter-Lite
Paper: VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Blog:
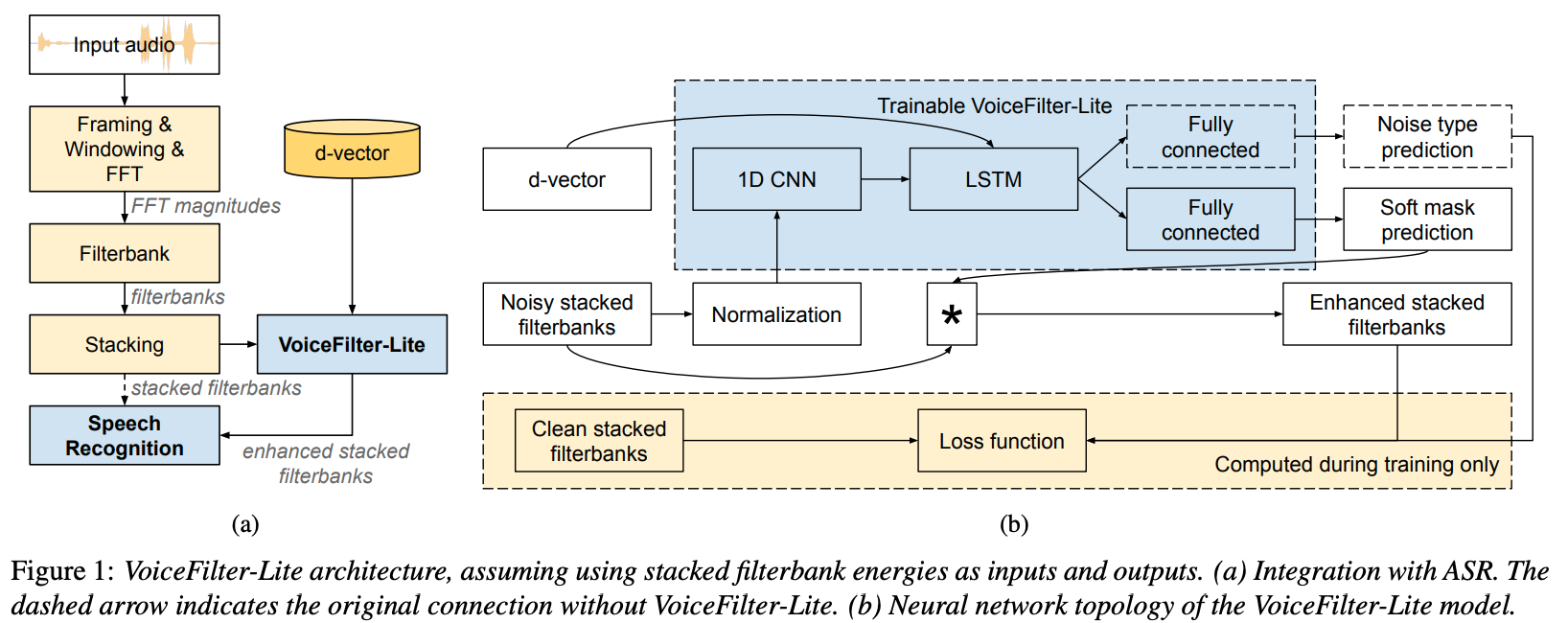
Automatic Speech Recognition (ASR)
NeMO
Paper: NeMo: a toolkit for building AI applications using Neural Modules
Nemo ASR
Whisper
Paper: Robust Speech Recognition via Large-Scale Weak Supervision

Kaggle: rkuo2000/asr-whisper
Qwen-Audio
Paper: Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Code: https://github.com/QwenLM/Qwen-Audio

Faster-Whisper
faster-whisper is a reimplementation of OpenAI’s Whisper model using CTranslate2, which is a fast inference engine for Transformer models.
Kaggle: rkuo2000/faster-whisper
Open Whisper-style Speech Models (OWSM)
Paper: OWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
Canary
Paper: Less is More: Accurate Speech Recognition & Translation without Web-Scale Data
Kaggle: rkuo2000/asr-canary-1b
Whisper Large-v3
Kaggle: rkuo2000/whisper-large-v3-turbo
Omnilingual-ASR
Paper: Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Code: https://github.com/facebookresearch/omnilingual-asr
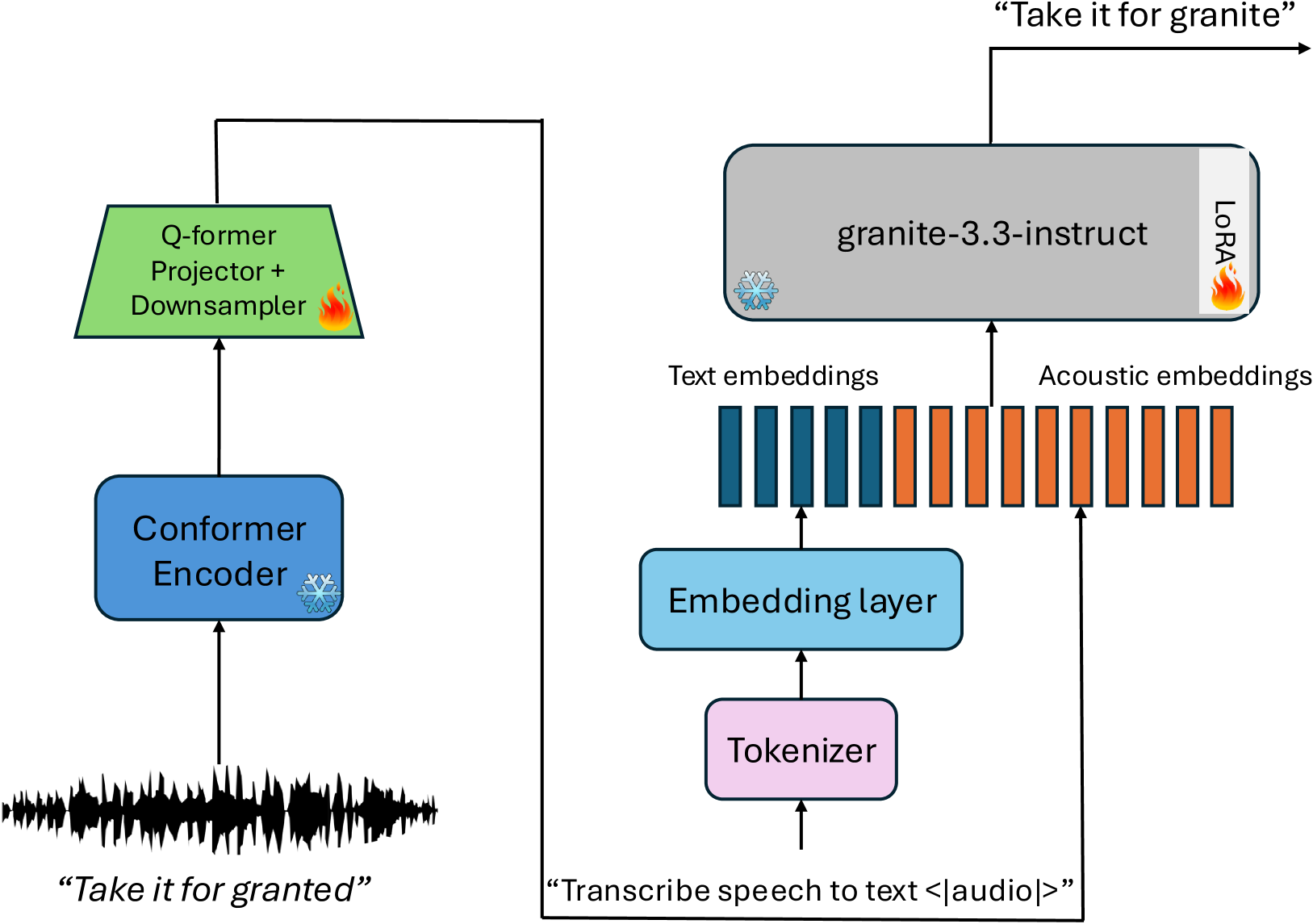
Granite-Speech
Paper: Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
GPT-Realtime-2
OpenAI發布三款可透過Realtime API使用的新音訊模型,分別是GPT-Realtime-2, GPT-Realtime-Translate與GPT-Realtime-Whisper

This site was last updated May 30, 2026.