RNN
RNN (循環神經網路) Introduction
Long Short Term Memory (LSTM)
Blog: Understanding LSTM Networks


Stock Price Forecast
Paper: Stock price forecast with deep learning
Kaggle: rkuo2000/Stock-LSTM, rkuo2000/Stock-LSTM-PyTorch

Kaggle: rkuo2000/Stock-CNN-LSTM

Code: huseinzol05/Stock-Prediction-Models

Word Embedding
Blog: Unsupervised Learning - Word Embedding



Sentiment Analysis
Dataset: First GOP Debate Twitter Sentiment
Code: Sentiment-LSTM vs Sentiment-NLTK
Neural Machine Translation
seq2seq

 Kaggle: rkuo2000/NMT-seq2seq
Kaggle: rkuo2000/NMT-seq2seq
Ipynb: NMT.ipynb
Neural Decipher
 Ugaritic is an extinct Northwest Semitic language, classified by some as a dialect of the Amorite language and so the only known Amorite dialect preserved in writing.
Ugaritic is an extinct Northwest Semitic language, classified by some as a dialect of the Amorite language and so the only known Amorite dialect preserved in writing.

Paper: Neural Decipherment via Minimum-Cost Flow: from Ugaritic to Linear B
Code: j-luo93/NeuroDecipher

Hand Writing Synthesis
Paper: Generating Sequences With Recurrent Neural Networks
Code: Grzego/handwriting-generation

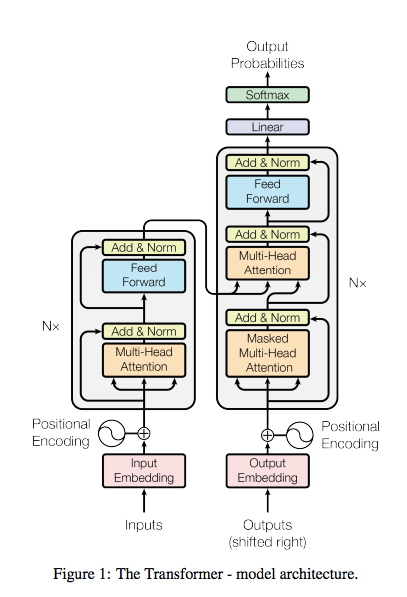
Transformer
Paper: Attention Is All You Need
Code: huggingface/transformers
Self-supervised Learning (自督導式學習)
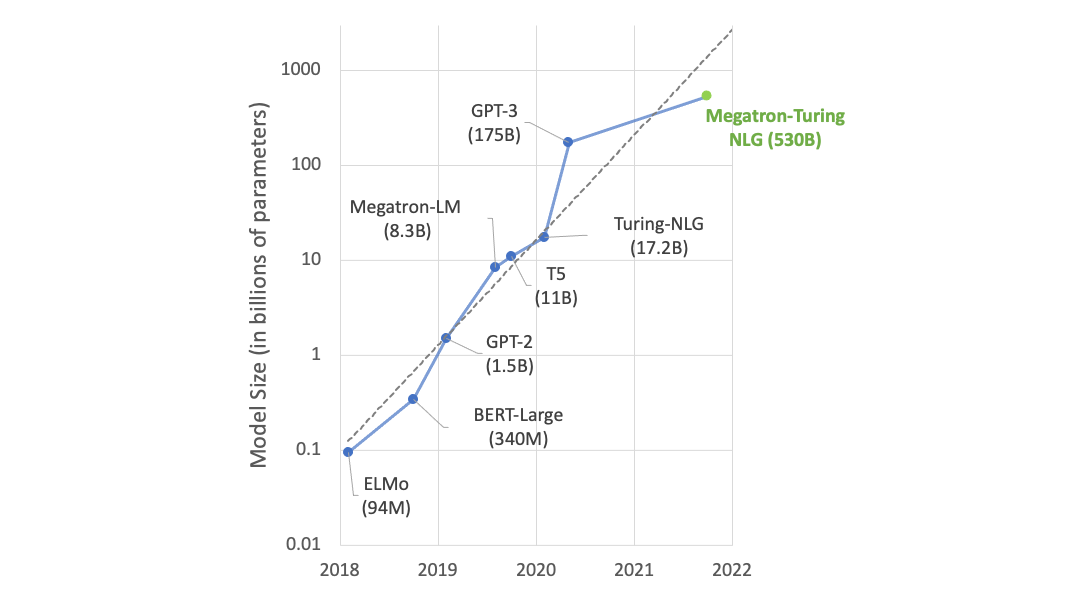
模型參數比例比較:
- ELMO (94M)
- BERT (340M)
- GPT-2 (1542M)
- Megatron (8B)
- T5 (11B)
- Turing-NRG (17B)
- GPT-3 (175B)
- Megatron-Turing NRG (530B)
- Switch Transfer (1.6T)
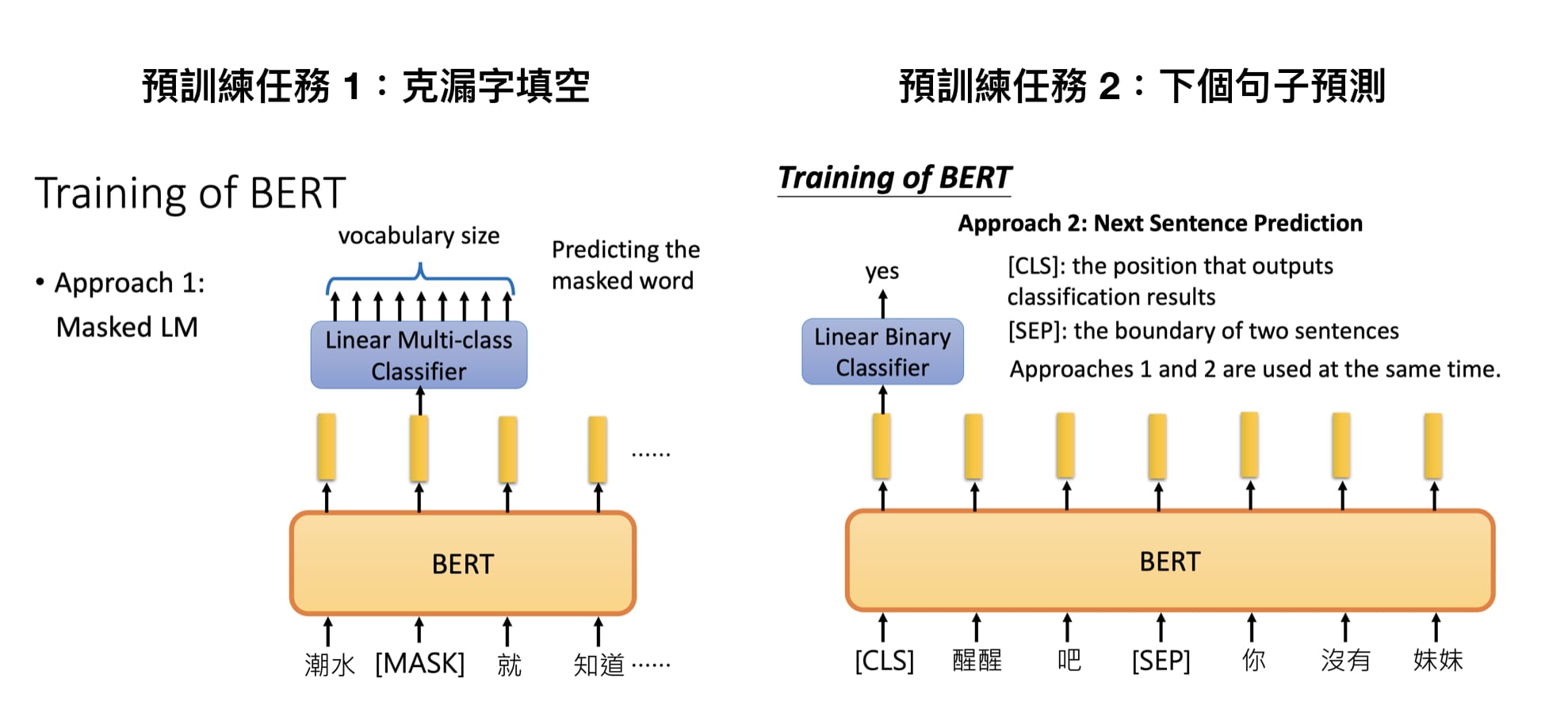
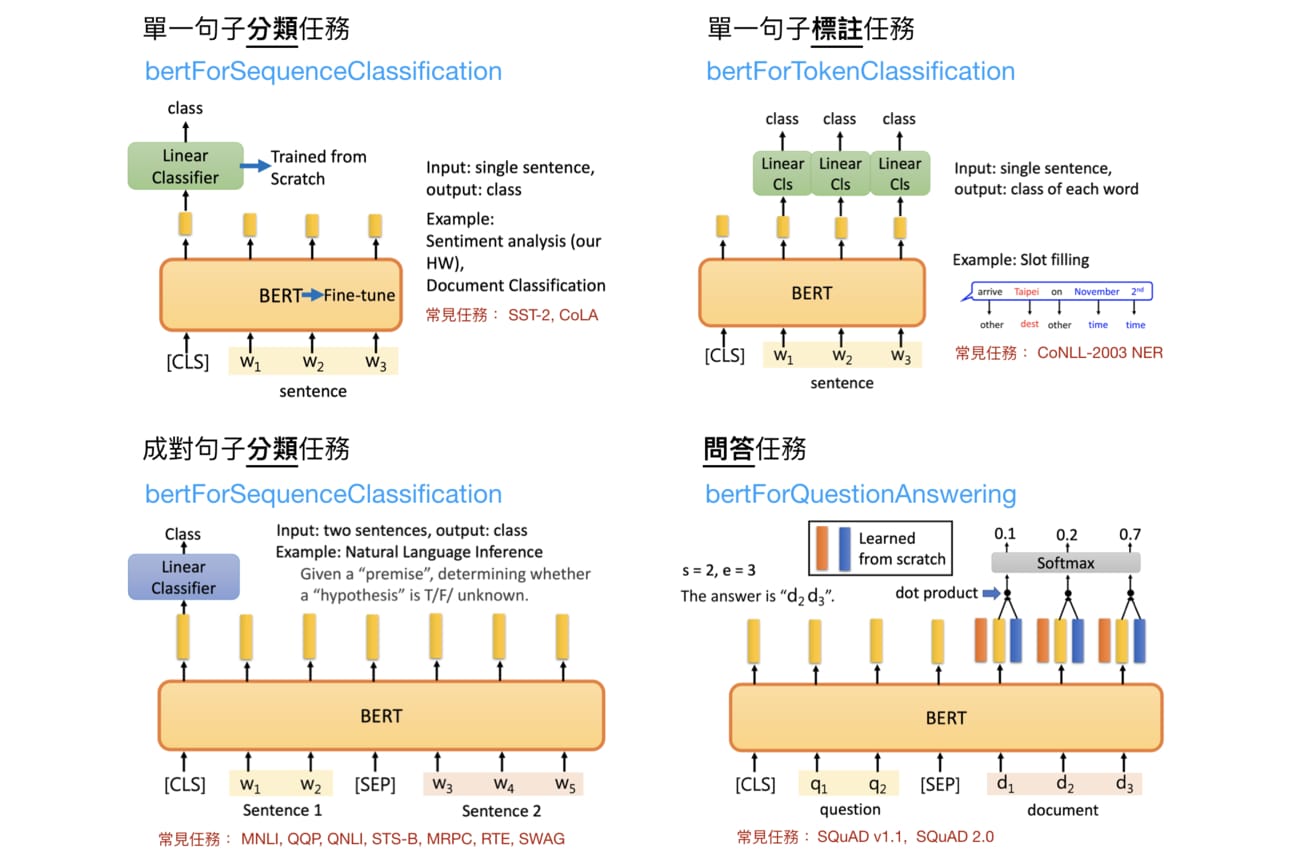
BERT
Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Blog: 進擊的BERT:NLP 界的巨人之力與遷移學習
GPT (Generative Pre-Training Transformer)
Paper: Improving Language Understanding by Generative Pre-Training
Paper: Language Models are Few-Shot Learners
Code: openai/gpt-2
MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism
Paper: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Code: NVIDIA/Megatron-LM
Blog: MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism
T5: Text-To-Text Transfer Transformer (by Google)
Paper: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Code: google-research/text-to-text-transfer-transformer
Dataset: C4
Blog: Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer
Turing-NLG (by Microsoft)
Blog: Turing-NLG: A 17-billion-parameter language model by Microsoft
GPT-3
Code: openai/gpt-3
GPT-3 Demo
Megatron-Turing NLG (by Nvidia)
Blog: Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B
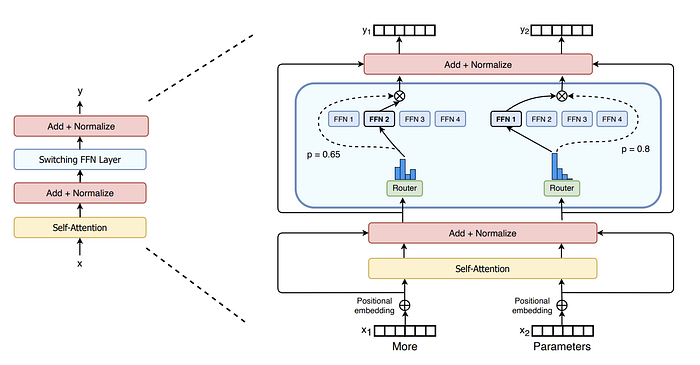
Switch Transformer (by Google)
Paper: Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
The Switch Transformer is a switch feed-forward neural network (FFN) layer that replaces the standard FFN layer in the transformer architecture.
Gopher
Blog: DeepMind推出2800亿参数模型;剑桥团队首次检测到量子自旋液体
Paper: Scaling Language Models: Methods, Analysis & Insights from Training Gopher
- Six models of Transformer:

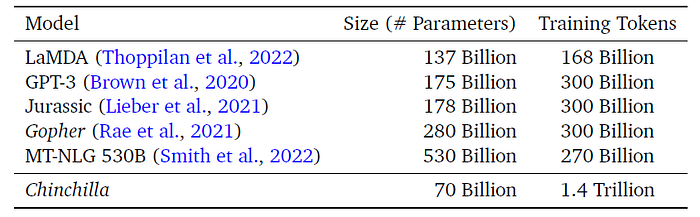
Chinchilla (by DeepMind)
Blog: An empirical analysis of compute-optimal large language model training
Paper: Training Compute-Optimal Large Language Models
PaLM (by Google)
Blog: Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
Paper: PaLM: Scaling Language Modeling with Pathways
Code: lucidrains/PaLM-pytorch

CKIP Transformers
CKIP (CHINESE KNOWLEDGE AND INFORMATION PROCESSING) 繁體中文詞庫小組
繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具。
CKIP Lab 下載軟體與資源
CKIP Transformers
SQuAD 2.0 - The Stanford Question Answering Dataset
Paper: Know What You Don’t Know: Unanswerable Questions for SQuAD

ELECTRA
Paper: ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators

Instruct GPT
Paper: Training language models to follow instructions with human feedback
Blog: Aligning Language Models to Follow Instructions
Methods:

ChatGPT
ChatGPT: Optimizing Language Models for Dialogue
ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.
Methods:

Video Representation Learning
SimCLR
Paper: A Simple Framework for Contrastive Learning of Visual Representations
Code: google-research/simclr

BYOL
Paper: Bootstrap your own latent: A new approach to self-supervised Learning
Code: lucidrains/byol-pytorch

VideoMoCo
Paper: VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples
Code: tinapan-pt/VideoMoCo
Dataset: Kinetics400, UCF101
Blog: VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples (CVPR2021)

PolyViT
Paper: PolyViT: Co-training Vision Transformers on Images, Videos and Audio
Speech Datasets
General Voice Recognition Datasets
- The LJ Speech Dataset/ : This is a public domain speech dataset consisting of 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books. A transcription is provided for each clip. Clips vary in length from 1 to 10 seconds and have a total length of approximately 24 hours.
- The M-AILABS Speech Dataset
- Speech Accent Archive: The speech accent archive was established to uniformly exhibit a large set of speech accents from a variety of language backgrounds. As such, the dataset contains 2,140 English speech samples, each from a different speaker reading the same passage. Furthermore, participants come from 177 countries and have 214 different native languages.
- Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): RAVDESS contains 24 professional actors (12 female and 12 male), vocalizing the same statements. Not only this, but the speech emotions captured include calm, happy, sad, angry, fearful, surprise, and disgust at two levels of intensity.
- TED-LIUM Release 3: The TED-LIUM corpus is made from TED talks and their transcriptions available on the TED website. It consists of 2,351 audio samples, 452 hours of audio. In addition, the dataset contains 2,351 aligned automatic transcripts in STM format.
- Google Audioset: This dataset contains expanding ontology of 635 audio event classes and a collection of over 2 million 10-second sound clips from YouTube videos. Moreover, Google used human labelers to add metadata, context and content analysis.
- LibriSpeech ASR Corpus: This corpus contains over 1,000 hours of English speech derived from audiobooks. Most of the recordings are based on texts from Project Gutenberg. Kaggle librispeech-clean, Tensorflow librispeech
Speaker Identification Datasets
- Gender Recognition by Voice: This database’s goal is to help systems identify whether a voice is male or female based upon acoustic properties of the voice and speech. Therefore, the dataset consists of over 3,000 recorded voice samples collected from male and female speakers.
- Common Voice: This dataset contains hundreds of thousands of voice samples for voice recognition. It includes over 500 hours of speech recordings alongside speaker demographics. To build the corpus, the content came from user submitted blog posts, old movies, books, and other public speech.
- VoxCeleb: VoxCeleb is a large-scale speaker identification dataset that contains over 100,000 phrases by 1,251 celebrities. Similar to the previous datasets, VoxCeleb includes a diverse range of accents, professions and age.
Speech Command Datasets
- Google Speech Commands Dataset: Created by the TensorFlow and AIY teams, this dataset contains 65,000 clips, each one second in duration. Each clip contains one of the 30 different voice commands spoken by thousands of different subjects.
- Synthetic Speech Commands Dataset: Created by Pete Warden, the Synthetic Speech Commands Dataset is made up of small speech samples. For example, each file contains single-word utterances such as yes, no, up, down, on, off, stop, and go.
- Fluent Speech Commands Dataset: This comprehensive dataset contains over 30,000 utterances from nearly 100 speakers. In this dataset, each .wav file contains a single utterance used to control smart-home appliances or virtual assistants. For example, sample recordings include “put on the music” or “turn up the heat in the kitchen”. In addition, all audio contains action, object, and location labels.
Conversational Speech Recognition Datasets
- The CHiME-5 Dataset: This dataset is made up of the recordings of 20 separate dinner parties that took place in real homes. Each file is a minimum of 2 hours and includes audio recorded in the kitchen, living and dining room.
- 2000 HUB5 English Evaluation Transcripts: Developed by the Linguistic Data Consortium (LDC), HUB5 consists of transcripts of 40 English telephone conversations. The HUB5 evaluation series focuses on conversational speech over the telephone with the task of transcribing conversational speech into text.
- CALLHOME American English Speech: Developed by the Linguistic Data Consortium (LDC), this dataset consists of 120 unscripted 30-minute telephone conversations in English. Due to the conditions of the study, most participants called family members or close friends.
Multilingual Speech Datasets
- CSS10: A collection of single speaker speech datasets for 10 languages. The dataset contains short audio clips in German, Greek, Spanish, French, Finnish, Hungarian, Japanese, Dutch, Russian and Chinese.
- BACKBONE Pedagogic Corpus of Video-Recorded Interviews: A web-based pedagogic corpora of video-recorded interviews with native speakers of English, French, German, Polish, Spanish and Turkish as well as non-native speakers of English.
- Arabic Speech Corpus: This speech corpus contains phonetic and orthographic transcriptions of more than 3.7 hours of Modern Standard Arabic (MSA) speech.
- Nijmegen Corpus of Casual French: Another single speech dataset, the Nijmegen corpus includes 35 hours of high-quality recordings. In this case, it features 46 French speakers conversing among friends, orthographically annotated by professional transcribers.
- Free Spoken Digit Dataset: This simple dataset contains recordings of spoken digits trimmed so that they are silent at the beginnings and ends.
- Spoken Wikipedia Corpora: This is a corpus of aligned spoken articles from Wikipedia. In addition to English, the data is also available in German and Dutch.
This site was last updated May 30, 2026.