AI Hardwares
AI chips
Top10 AI Chip Makers

Tesla
AI5


Tesla Hardware 4 (AI4) – Full Details and Latest News

Hardware 3 (AI3) – FSD Computer

Tesla’s Hardware & E/E Architecture

Nvidia

Nvidia Draws GPU System Roadmap Out To 2028

Analysis of NVIDIA’s Latest Hardware: B100/B200/GH200/NVL72/SuperPod
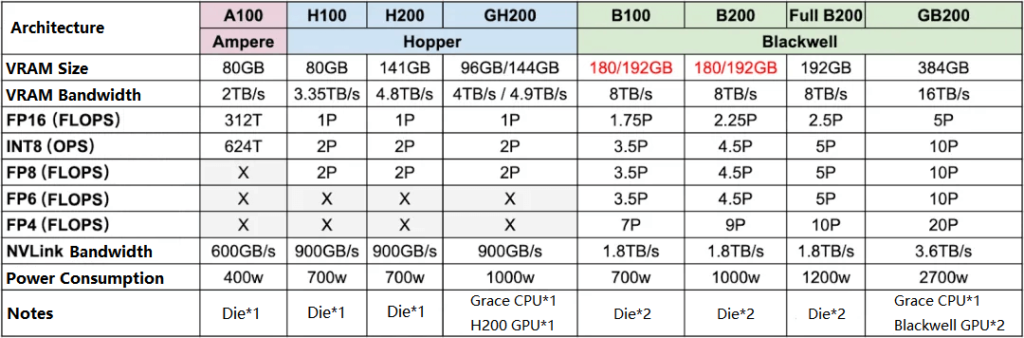
DGX-Spark
Nvidia GB10 Grace Blackwell Superchip單系統晶片。GB10包含具第5代Tensor Cores及FP4精度支援的Nvidia Blackwell GPU,使DGX具備128GB記憶體,並支援最高1000 TOPS

Geforce RTX 50 series

Groq LPU
Google TPU v6e
Edge AI
Nvidia Jetson

Jetson Thor
Introducing NVIDIA Jetson Thor, the Ultimate Platform for Physical AI


NVIDIA Jetson Orin Nano Developer Kit Gets a “Super” Boost
NVIDIA® Jetson Orin Nano™ Super 入門套件包

RPi 5 + Hailo-8L

- Hailo-8L (13 TOPs)
- Broadcom BCM2712 2.4GHz quad-core 64-bit Arm Cortex-A76 CPU, with Cryptographic Extension, 512KB per-core L2 caches, and a 2MB shared L3 cache
MediaTek
Kinara
Ara-2
Kinara Ara-2 AI processor (40 TOPS)
耐能 Kneron KL730 AI Soc
- Quad ARM® Cortex™ A55 CPU。
- 內建DSP,可以加速AI模型後處理,語音處理。
- Linux和RTOS、TSMC 12 納米工藝。
- 高達4K@60fps解析度,與主流感測器的無縫 RGB Bayer 接口,多達4通道影像接口。
- 高達3.6eTOPS@int8 / 7.2eTops@int4。
- 支持Cafee、Tensorflow、Tensorflowlite、Pytorch、Keras、ONNX框架。
- 并兼容CNN、Transformer、RNN Hybrid等多種AI模型, 有更高的處理效率和精度。
堪智 Kendryte
K230
- CPU : 1.6GHz & 0.8GHz Dual-core 64-bit RISC-V
- VPU: H.264/H.265 encoding/decoding up to
- Memory & Storage: 32-bit LPDDR4/DDR4/LPDDR3/DDR3, SD3.01, eMMC 5.0.
- Display Output: 1-lane MIPI DSI, max @ 60fps.
- 3D Depth Engine (DPU): Up to resolution.
- Peripherals: 2x USB 2.0 OTG, 5x UART, 5x I2C, 6x PWM, 4-ch PDM (digital mic).
K210
- CPU : 400MHz Dual-Core 64-bit RISC-V RV64IMAFDC (RV64GC) CPU
- SRAM: 8MB Total On-Chip SRAM (6MB General Purpose + 2MB AI SRAM)
- NPU : 0.6TOPS
- APU : Supports Microphone Array (up to 8 microphones)
STMicro STM32N6 series
效能
- 1280 DMIPS / 3360 CoreMark
- Helium(M-Profile 向量延伸,MVE):新增約 150 條指令,專為高速執行進階 DSP 與機器學習程式碼而設計
- ST Neural-ART Accelerator™:
- 針對高效能、低功耗 AI 演算法最佳化
- 運作時脈 1 GHz,提供 600 GOPS,平均能源效率達 3 TOPS/W
記憶體
- 無 Flash 架構設計
- 4.2 MB 連續式內嵌 RAM
- 高速序列介面支援外部記憶體:以低腳位數、具成本效益的方式,透過 8 或 16 位元介面存取外部記憶體
- 彈性記憶體控制器(PSRAM、SDRAM、NOR、NAND)
進階圖形與多媒體功能
- Chrom-ART Accelerator:2D 圖形加速
- Chrom-GRC:適用於非方形顯示器的圖形資源裁切器
- NeoChrom™ Accelerator:
- 2.5D 圖形加速,支援進階繪圖功能
- 透視校正與材質貼圖
- H.264 編碼器:720p / 1080p @ 30 fps
JPEG 硬體加速器:
- JPEG 壓縮與解壓縮
- 高畫質 Motion JPEG 影片播放
專用影像訊號處理器(ISP):
- 支援 500 萬畫素攝影機 @ 30 fps
- 可由同一攝影機輸入影像產生 3 種不同輸出影像
- 多種攝影機介面:MIPI CSI-2(2 lanes)、16 位元平行介面
- STM32-ISP-IQTune 工具,用於管理 ISP 調校
Infineon PSOC Edge
- Cortex-M55 + Helium DSP @500MHz
- Cortex-M33 @200MHz
- NNLite + Ethos™ U55-128 (4 TOPS)
- SRAM up to 5/6MB
- 2.5D GPU, MIPI-DSI/DBI
- USB, 10/100 Ethernet, CAN, SPI, UART, I2C
- Security: EPC/PSA 2 and 4
Realtek AMB82-MINI

- MCU
- Part Number: RTL8735B
- 32-bit Arm v8M, up to 500MHz
- MEMORY
- 768KB ROM
- 512KB RAM
- 16MB Flash
- Supports MCM embedded DDR2/DDR3L memory up to 128MB
- KEY FEATURES
- Integrated 802.11 a/b/g/n Wi-Fi, 2.4GHz/5GHz
- Bluetooth Low Energy (BLE) 5.1
- Integrated Intelligent Engine (0.4 TOPS)
Nuvoton M55M1
Cortex-M55 + Ethos U55 @220MHz (0.11 TOPS)

Himax WiseEye 2 AI Processor (WE2)

- Cortex-M55 + Ethos-U55 @400MHz (0.05 TOPS)
- Internal 2MB SRAMs and 512KB TCM
- External 100MHz QSPI Flash, Max 16MB(128Mb)
Agent Harewares comparison
NVIDIA® Jetson Comparison / Module Specification from Jetson Orin Series to Jetson AGX Thor Series
RPi5 vs RPi4
| 項目 | Raspberry Pi 5 | Raspberry Pi 4 Model B | 差異重點 |
|---|---|---|---|
| 🧠 CPU | 四核 2.4 GHz Cortex-A76 | 四核 1.8 GHz Cortex-A72 | 🚀 約 2–3× 效能提升 |
| 🎮 GPU | VideoCore VII @ 1.1 GHz | VideoCore VI @ 800 MHz | 🎨 圖形效能更強 |
| 🧮 RAM | 4GB / 8GB LPDDR4X-4267 | 2GB / 4GB / 8GB LPDDR4-3200 | ⚡ 記憶體頻寬更高 |
| 🖥 顯示輸出 | 雙 micro-HDMI(雙 4Kp60) | 雙 micro-HDMI(單 4Kp60) | 🖥️ 多螢幕能力提升 |
| 📷 相機 / DSI | 2 × 4-lane MIPI | 1 × 2-lane CSI + 1 × DSI | 📸 支援雙鏡頭 |
| 💾 PCIe | 1 × PCIe 2.0 | ❌ 無 | 🚀 可接 NVMe / SSD |
| 🔌 USB | 2× USB3 + 2× USB2 | 2× USB3 + 2× USB2 | ➖ 相同 |
| 🔋 電源 | 5V / 5A USB-C PD | 5V / 3A USB-C | ⚠️ Pi 5 需更高功率 |
| ⭐ 新功能 | 電源按鈕、RTC | 無 | 👍 使用更方便 |
| 🔧 I/O 架構 | RP1 I/O 控制器 | SoC 內建 I/O | 📈 I/O 效能更佳 |
Mac mini-M4 OrinNano-Super vs K230
| Feature | NVIDIA Jetson Orin Nano Super | Kendryte K230 (CanMV / 01Studio) |
|---|---|---|
| 🎯 Primary Focus | High-performance Edge AI / Generative AI | Ultra-low-power Vision / Audio AI |
| 🧠 AI Performance | Up to 67 TOPS (INT8) | ~6 TOPS (INT8) |
| 🏗 Architecture | ARM Cortex-A78AE + Ampere GPU | Dual-core RISC-V (C908 + C908V) |
| 💻 CPU | 1.7GHz 6-core ARM Cortex-A78AE | 1.6 GHz RISC-V + 800 MHz RISC-V |
| 🎮 GPU | 1024-core NVIDIA Ampere GPU | ❌ None (vector processing only) |
| 🧮 RAM | 8 GB LPDDR5 | 512 MB – 1 GB LPDDR3/4 |
| 💾 Storage | M.2 NVMe SSD (PCIe) | microSD Card |
| 🔋 Power Budget | 7W – 25W (configurable) | Very low (battery-friendly) |
| 🧰 Software Stack | JetPack SDK, CUDA, TensorRT | CanMV (MicroPython), RT-Smart |
| 💵 Price | ~$249 USD (Dev Kit) | ~$25 – $55 USD |
Mac M4 Pro vs Jetson Orin 64GB
| Feature | Apple M4 Pro (20-core GPU) | Jetson AGX Orin 64GB |
|---|---|---|
| GPU Architecture | Custom Apple GPU architecture | NVIDIA Ampere architecture |
| GPU Cores | 20 GPU cores (~2,560 shading units est.) | 2,048 CUDA cores + 64 Tensor Cores |
| GPU Clock Speed | Up to ~1.8 GHz | Up to ~1.3 GHz |
| Memory | Unified memory up to 64 GB, 273 GB/s bandwidth | 64 GB LPDDR5, 204.8 GB/s bandwidth |
| AI Performance | Not publicly specified (16-core Neural Engine) | Up to 275 TOPS (INT8) |
| Ray Tracing | Hardware-accelerated ray tracing | Hardware ray-tracing support |
| Manufacturing Process | 3 nm | 8 nm |
| Power Consumption | ~32 W (estimated) | Configurable 15 W – 60 W |
🛸 NVIDIA Jetson Thor vs. 🌌 NVIDIA DGX Blackwell (GB200)
| Feature | NVIDIA Jetson Thor | NVIDIA DGX GB200 (Blackwell) |
|---|---|---|
| Primary Target | Humanoid Robots & Autonomous Machines | LLM Training & Generative AI Inference |
| Architecture | Blackwell GPU + Grace CPU | Blackwell GPU + Grace CPU |
| Form Factor | System-on-Module (Edge) | Full Rack / Data Center Node |
| AI Performance | ~800 TFLOPS (FP8) | Up to 1.4 Exaflops (FP4 in NVL72) |
| Memory Architecture | Unified LPDDR5X (High Bandwidth) | HBM3e (High Bandwidth Memory) |
| Power Consumption | ~100W - 200W (Estimated) | Up to 120kW per Rack |
| Cooling | Air or Passive (Integrated) | Liquid Cooled |
| Key Interface | MIPI, GMSL, Ethernet (Robotics I/O) | 5th Gen NVLink (1.8TB/s per GPU) |
This site was last updated May 28, 2026.