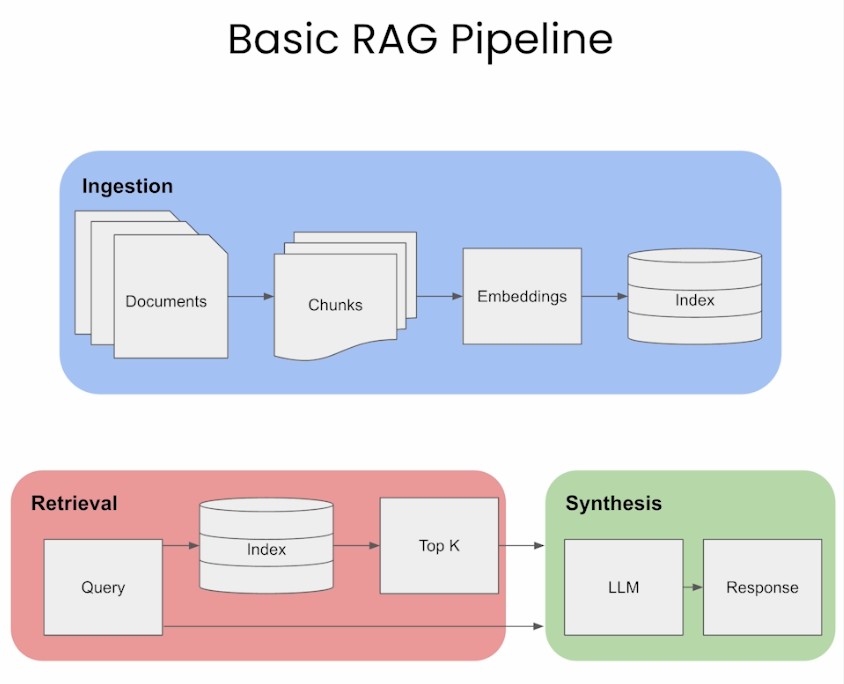
Retrieval-Augmented Generation
Introduction to RAG, LlamaIndex, examples.
RAG (檢索增強生成)

Blog: Building RAG-based LLM Applications for Production
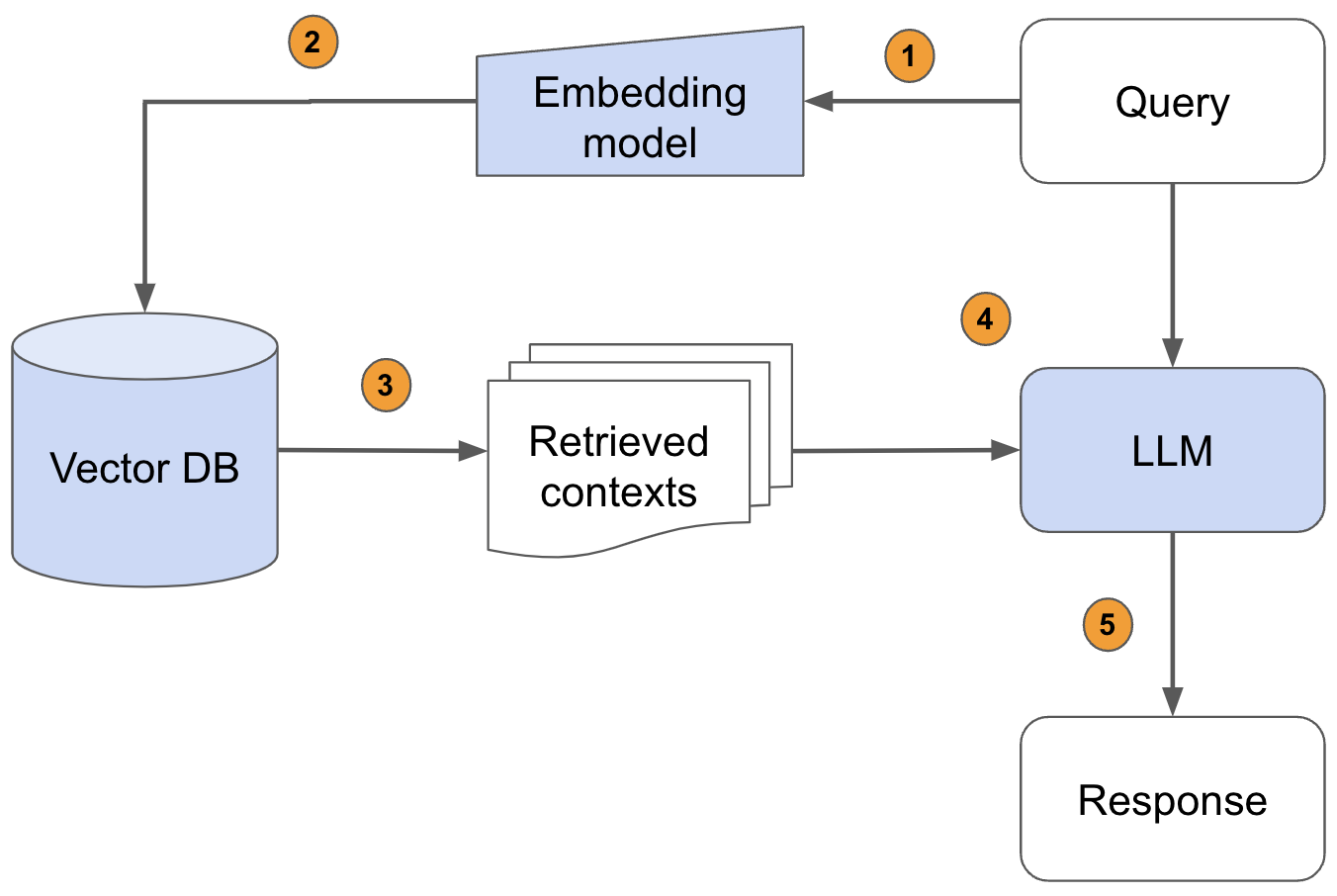
(1)將外部文件做分塊(chunking)再分詞(tokenize)轉成token
(2)利用嵌入模型,將token做嵌入(embeds)運算,轉成向量,儲存至向量資料庫(Vector Database)並索引(Indexes)
(3)用戶提出問題,向量資料庫將問題字串轉成向量(利用前一個步驟的嵌入模型),再透過餘弦(Cosine)相似度或歐氏距離演算法來搜尋資料庫裡的近似資料
(4)將用戶的問題、資料庫查詢結果一起放進Prompt(提示),交由LLM推理出最終答案
以上是基本的RAG流程,利用Langchain或LlamaIndex或Haystack之類的應用程式開發框架,大概用不到一百行的程式碼就能做掉(含LLM的裝載)。
RAG Survey
Paper: Retrieval-Augmented Generation for Large Language Models: A Survey
Paper: Retrieval-Augmented Generation for AI-Generated Content: A Survey
Paper: A Survey on Retrieval-Augmented Text Generation for Large Language Models
Paper: RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing
Paper: A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models
Paper: Evaluation of Retrieval-Augmented Generation: A Survey
Paper: Retrieval-Augmented Generation for Natural Language Processing: A Survey
Paper: Graph Retrieval-Augmented Generation: A Survey
Paper: RAG and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely
Paper: A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions
A Guide on 12 Tuning Strategies for Production-Ready RAG Applications
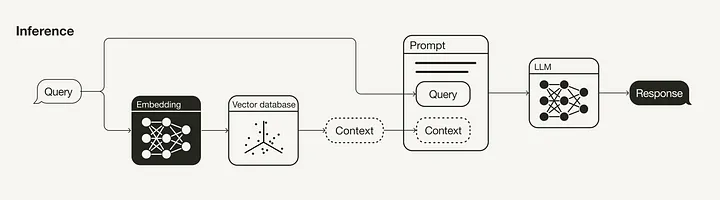
NLP • Retrieval Augmented Generation
BGE (BAAI General Embedding)
Code: https://github.com/FlagOpen/FlagEmbedding
EAGLE-LLM
3X faster for LLM
Blog: EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation
Code: https://github.com/SafeAILab/EAGLE
Kaggle: https://www.kaggle.com/code/rkuo2000/eagle-llm

PurpleLlama CyberSecEval
Paper: PurpleLlama CyberSecEval: A Secure Coding Benchmark for Language Models
Code: CybersecurityBenchmarks
meta-llama/LlamaGuard-7b
| Our Test Set (Prompt) | OpenAI Mod | ToxicChat | Our Test Set (Response) | |
|---|---|---|---|---|
| Llama-Guard | 0.945 | 0.847 | 0.626 | 0.953 |
| OpenAI API | 0.764 | 0.856 | 0.588 | 0.769 |
| Perspective API | 0.728 | 0.787 | 0.532 | 0.699 |
Frameworks
LlamaIndex
Code: https://github.com/run-llama/llama_index
Docs:
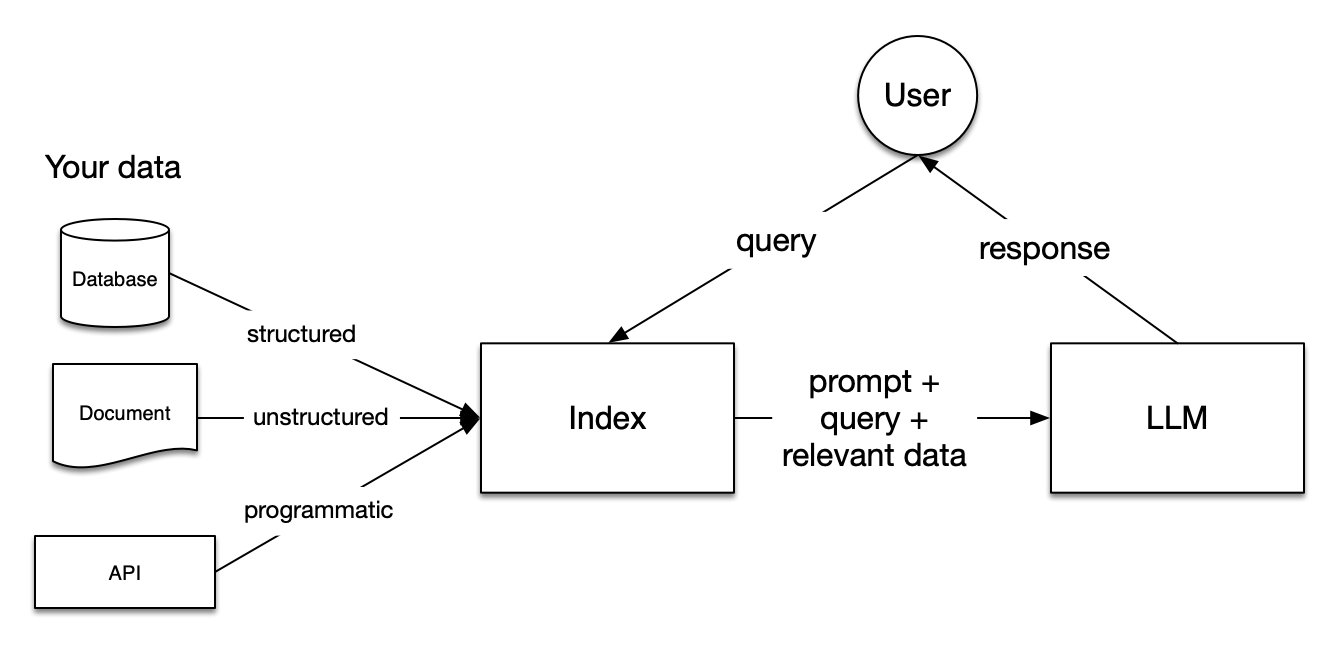
LangChain
- langchain-core: Base abstractions and LangChain Expression Language.
- Integration packages (e.g. langchain-openai, langchain-anthropic, etc.): Important integrations have been split into lightweight packages that are co-maintained by the LangChain team and the integration developers.
- langchain: Chains, agents, and retrieval strategies that make up an application’s cognitive architecture.
- langchain-community: Third-party integrations that are community maintained.
- LangGraph: Build robust and stateful multi-actor applications with LLMs by modeling steps as edges and nodes in a graph. Integrates smoothly with LangChain, but can be used without it. To learn more about LangGraph, check out our first LangChain Academy course, Introduction to LangGraph, available here.
- LangGraph Platform: Deploy LLM applications built with LangGraph to production.
- LangSmith: A developer platform that lets you debug, test, evaluate, and monitor LLM applications.
Kaggle: https://www.kaggle.com/code/rkuo2000/rag-with-langchain
Contextual Retrieval RAG
Blog: Introducing Contextual Retrieval
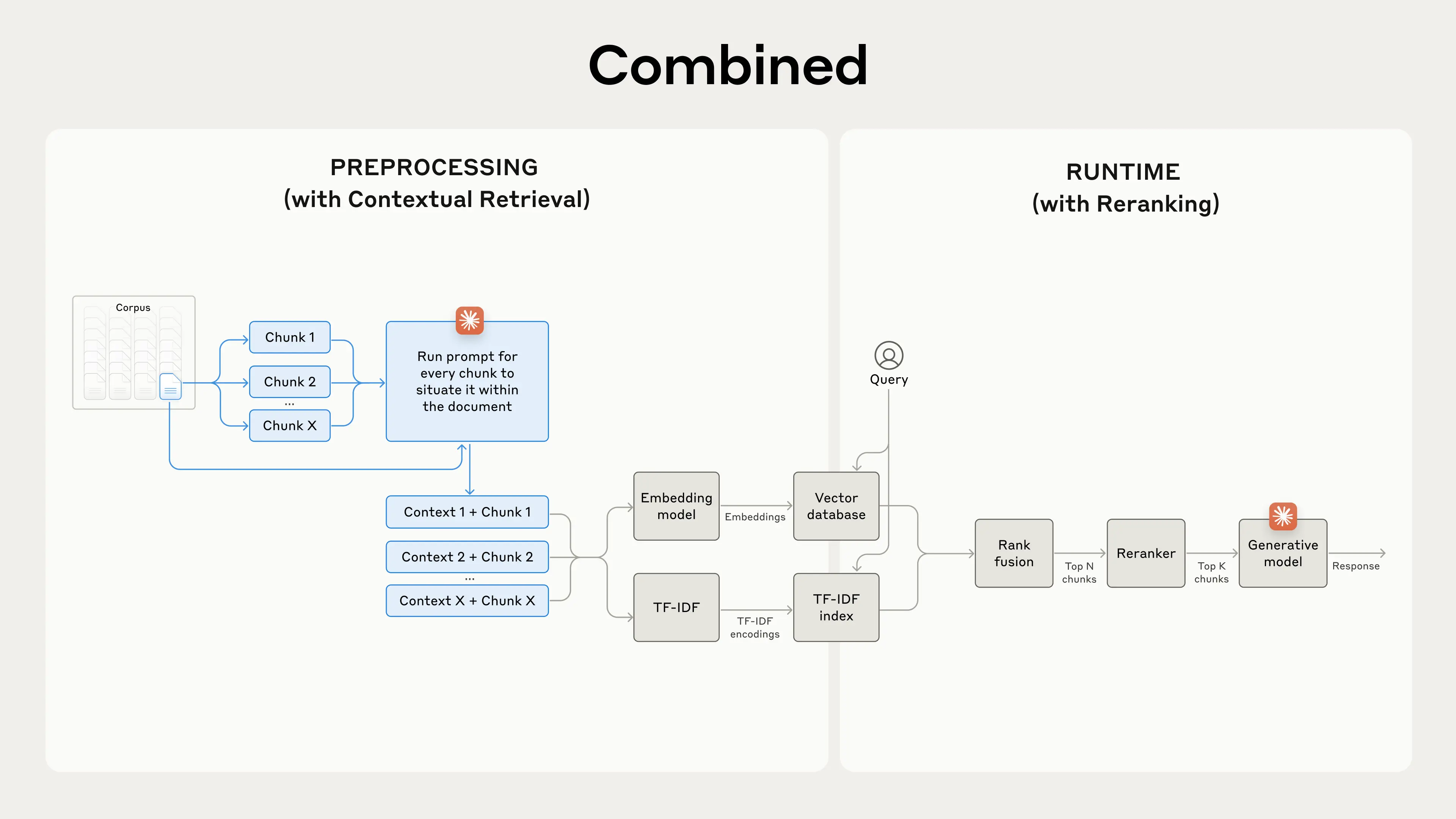 Blog: Implementing Contextual Retrieval in RAG pipeline
Blog: Implementing Contextual Retrieval in RAG pipeline
Corrective RAG
Paper: Corrective Retrieval Augmented Generation
Blog: CRAG: 檢索增強生成的糾錯機制 - 提升大型語言模型問答精確度
Code: https://github.com/HuskyInSalt/CRAG
GRAG
Paper: GRAG: Graph Retrieval-Augmented Generation
Code: https://github.com/microsoft/graphrag
Blog: Knowledge Graph + RAG | Microsoft GraphRAG 實作與視覺化教學
HippoRAG
Paper: HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
Code: https://github.com/OSU-NLP-Group/HippoRAG

TAG (Table-Augmented Generation)
Paper: Text2SQL is Not Enough: Unifying AI and Databases with TAG
Blog: Goodbye, Text2SQL: Why Table-Augmented Generation (TAG) is the Future of AI-Driven Data Queries!
Code: https://github.com/TAG-Research/TAG-Bench

VisRAG
Paper: VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
Code: https://github.com/openbmb/visrag

RAG-FiT
Code: https://github.com/IntelLabs/RAG-FiT
RAG-FiT is a library designed to improve LLMs ability to use external information by fine-tuning models on specially created RAG-augmented datasets.
應用實例:
- 醫學問答機器人:自動查最新論文回答
- 法律顧問AI:即時檢索法條庫
- 新聞生成器:抓時事數據寫報導
- 論文助手:整理相關研究生成文獻回顧
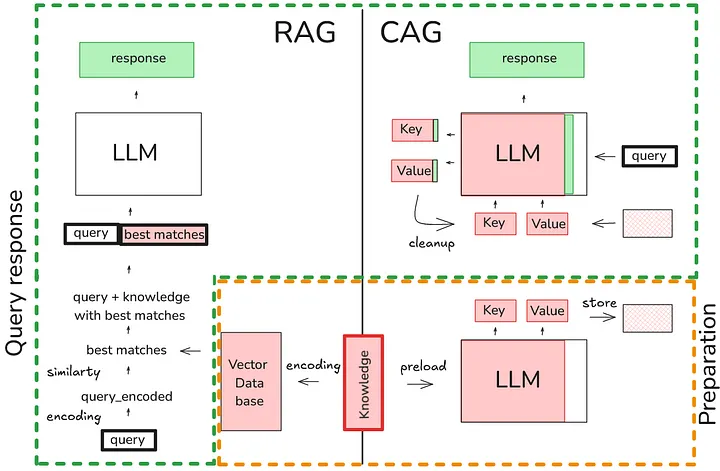
CAG (Cache-Augmented Generation)
Paper: Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
Blog: Cache-Augmented Generation: A Faster, Simpler Alternative to RAG for AI
Code: https://github.com/hhhuang/CAG
Blog: Cache-Augmented Generation (CAG) from Scratch
DeepRAG
Paper: DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
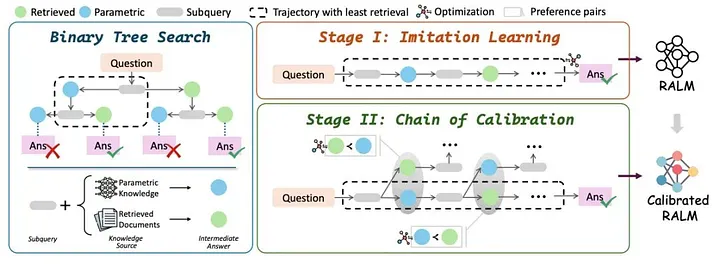
DeepRAG Construct Instruction:
Instruction: You are a helpful Retrieve-Augmented
Generation (RAG) model. Your task is to answer
questions by logically decomposing them into clear
sub-questions and iteratively addressing each one.
Use "Follow up:" to introduce each sub-question and
"Intermediate answer:" to provide answers.
For each sub-question, decide whether you can provide a direct answer or if additional information is
required. If additional information is needed, state,
"Let’s search the question in Wikipedia." and then use
the retrieved information to respond comprehensively.
If a direct answer is possible, provide it immediately
without searching.
This site was last updated October 02, 2025.