LLM Fine-Tuning
Introduction to LLM Fine-Tuning
LLM FineTuning
Low-Rank Adaptation (LoRA)
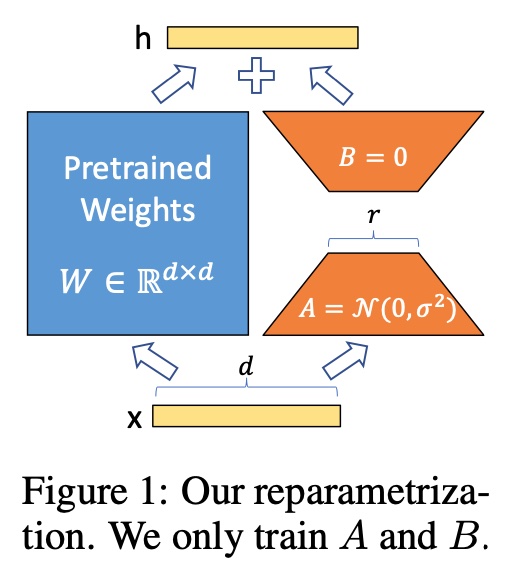
FlashAttention
Paper: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Blog: ELI5: FlashAttention
Few-Shot PEFT
Paper: Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
PEFT (Parameter-Efficient Fine-Tuning)
Paper: Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment
Code: https://github.com/huggingface/peft
QLoRA
Paper: QLoRA: Efficient Finetuning of Quantized LLMs
Code: https://github.com/artidoro/qlora
AWQ
Paper: AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Code: https://github.com/mit-han-lab/llm-awq

FlashAttention-2
Paper: FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Code: https://github.com/kyegomez/FlashAttention20
Soft-prompt Tuning
Paper: Soft-prompt Tuning for Large Language Models to Evaluate Bias
Platypus
Paper: Platypus: Quick, Cheap, and Powerful Refinement of LLMs
Code: https://github.com/arielnlee/Platypus/
LLM Lingua
Paper: LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
**Code: https://github.com/microsoft/LLMLingua
**Kaggle: https://www.kaggle.com/code/rkuo2000/llm-lingua

LongLoRA
Code: https://github.com/dvlab-research/LongLoRA
[2023.11.19] We release a new version of LongAlpaca models, LongAlpaca-7B-16k, LongAlpaca-7B-16k, and LongAlpaca-7B-16k.

GPTCache
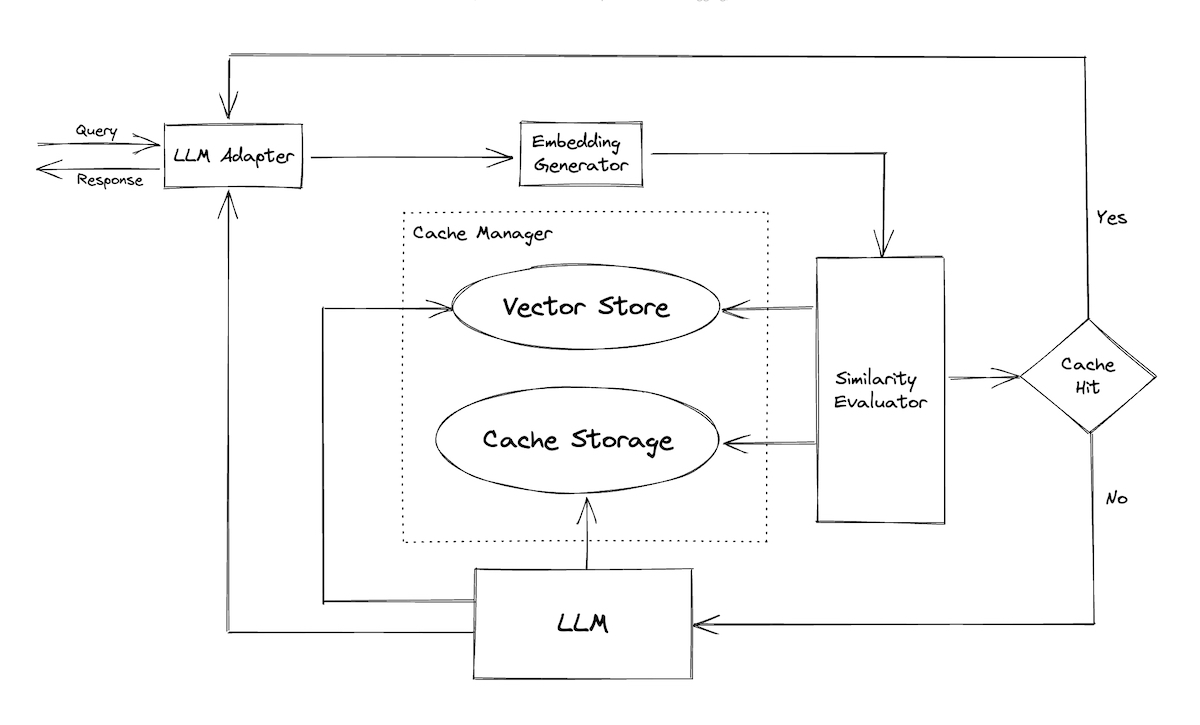
localLLM
Code: https://github.com/ykhli/local-ai-stack
🦙 Inference: Ollama
💻 VectorDB: Supabase pgvector
🧠 LLM Orchestration: Langchain.js
🖼️ App logic: Next.js
🧮 Embeddings generation: Transformer.js and all-MiniLM-L6-v2
AirLLM
Blog: Unbelievable! Run 70B LLM Inference on a Single 4GB GPU with This NEW Technique
Code: https://github.com/lyogavin/Anima/tree/main/air_llm
PowerInfer
Paper: PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
Code: https://github.com/SJTU-IPADS/PowerInfer
Blog: 2080 Ti就能跑70B大模型,上交大新框架让LLM推理增速11倍
https://github.com/SJTU-IPADS/PowerInfer/assets/34213478/fe441a42-5fce-448b-a3e5-ea4abb43ba23
PowerInfer v.s. llama.cpp on a single RTX 4090(24G) running Falcon(ReLU)-40B-FP16 with a 11x speedup!
Both PowerInfer and llama.cpp were running on the same hardware and fully utilized VRAM on RTX 4090.
Eagle
Paper: EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Code: https://github.com/SafeAILab/EAGLE
Kaggle: https://www.kaggle.com/code/rkuo2000/eagle-llm
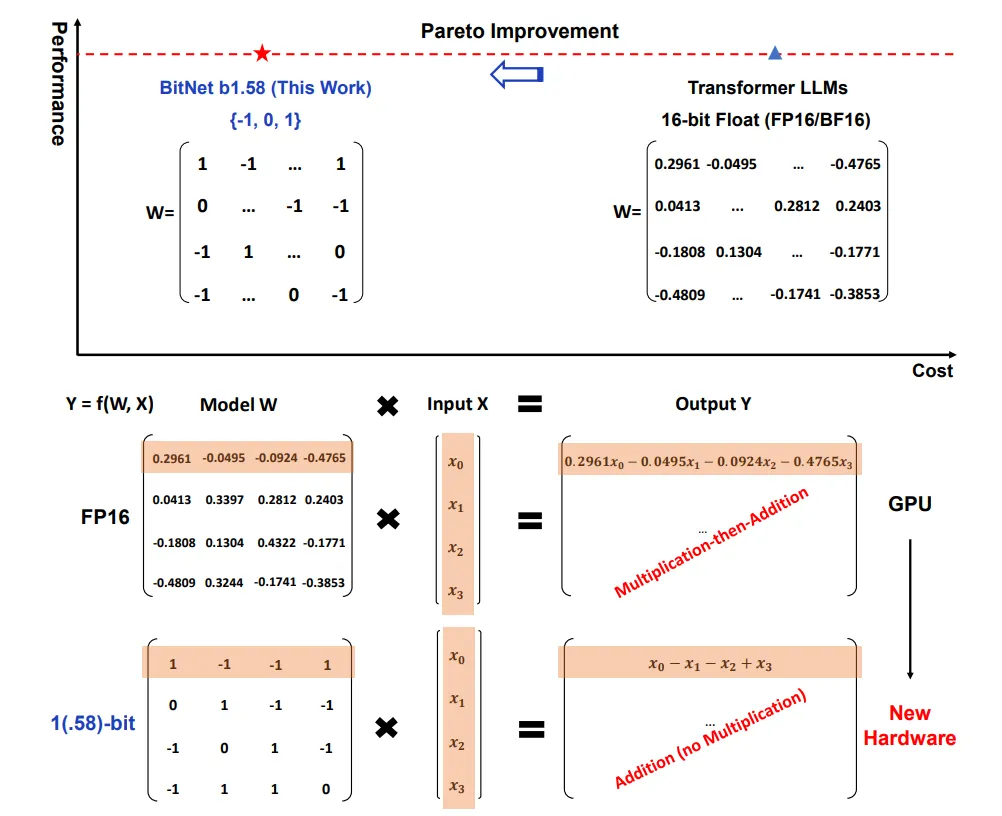
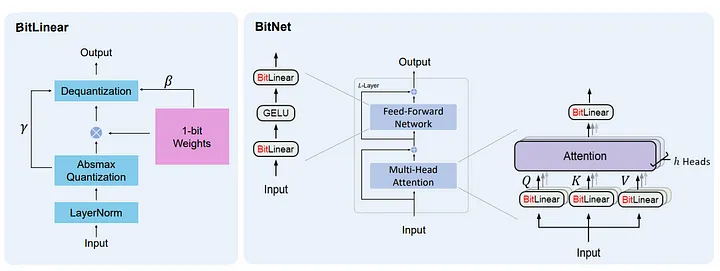
Era of 1-bit LLMs
Paper: The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Blog: No more Floating Points, The Era of 1.58-bit Large Language Models
GaLore
Paper: GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Code: https://github.com/jiaweizzhao/galore
To train a 7B model with a single GPU such as NVIDIA RTX 4090, all you need to do is to specify –optimizer=galore_adamw8bit_per_layer, which enables GaLoreAdamW8bit with per-layer weight updates. With activation checkpointing, you can maintain a batch size of 16 tested on NVIDIA RTX 4090.
LlamaFactory
Paper: LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Code: https://github.com/hiyouga/LLaMA-Factory
PEFT for Vision Model
Paper: Parameter-Efficient Fine-Tuning for Pre-Trained Vision Models: A Survey


ReFT
representation fine-tuning (ReFT) library, a Powerful, Parameter-Efficient, and Interpretable fine-tuning method
Paper: ReFT: Representation Finetuning for Language Models
Code: https://github.com/stanfordnlp/pyreft
ORPO
model: kaist-ai/mistral-orpo-beta
Paper: ORPO: Monolithic Preference Optimization without Reference Model
Code: https://github.com/xfactlab/orpo
Blog: Fine-tune Llama 3 with ORPO
FlagEmbedding
model: namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA
Paper: Extending Llama-3’s Context Ten-Fold Overnight
Code: https://github.com/FlagOpen/FlagEmbedding
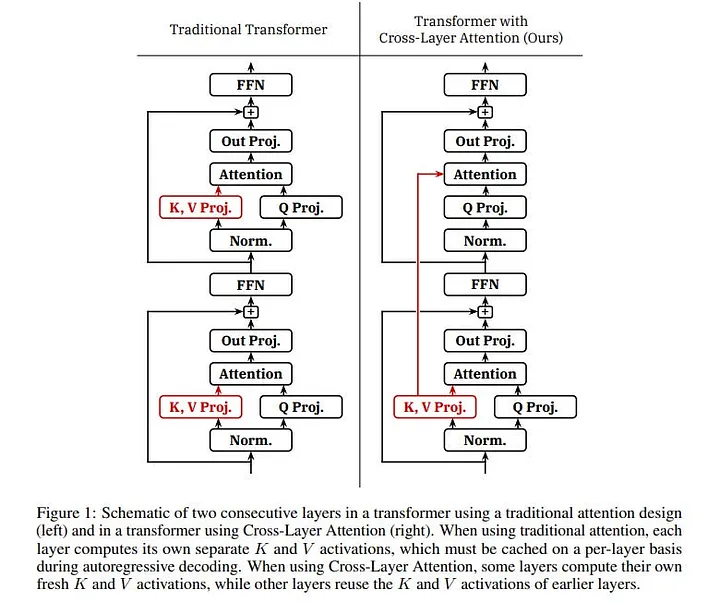
Memory-Efficient Inference: Smaller KV Cache with Cross-Layer Attention
Paper: Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
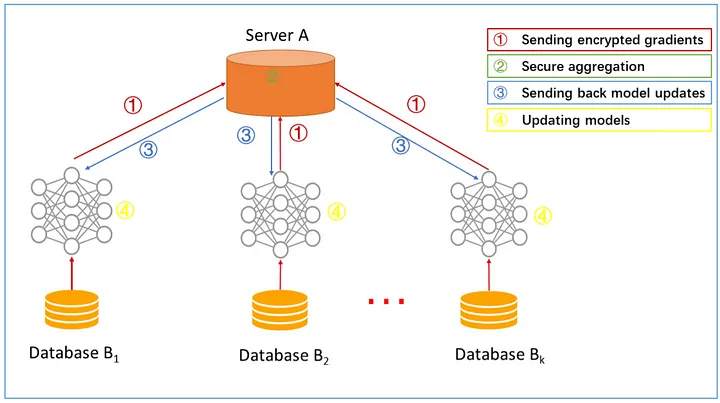
Federated Learning
Blog: 聯盟式學習 (Federated Learning)
Paper: Federated Machine Learning: Concept and Applications
Architecture for a horizontal federated learning system
 Architecture for a vertical federated learning system
Architecture for a vertical federated learning system
FATE-LLM
FATE-LLM is a framework to support federated learning for large language models(LLMs) and small language models(SLMs).
Code: https://github.com/FederatedAI/FATE-LLM

OpenFedLLM
Paper: OpenFedLLM: Training Large Language Models on Decentralized Private Data via Federated Learning
Code: https://github.com/rui-ye/openfedllm

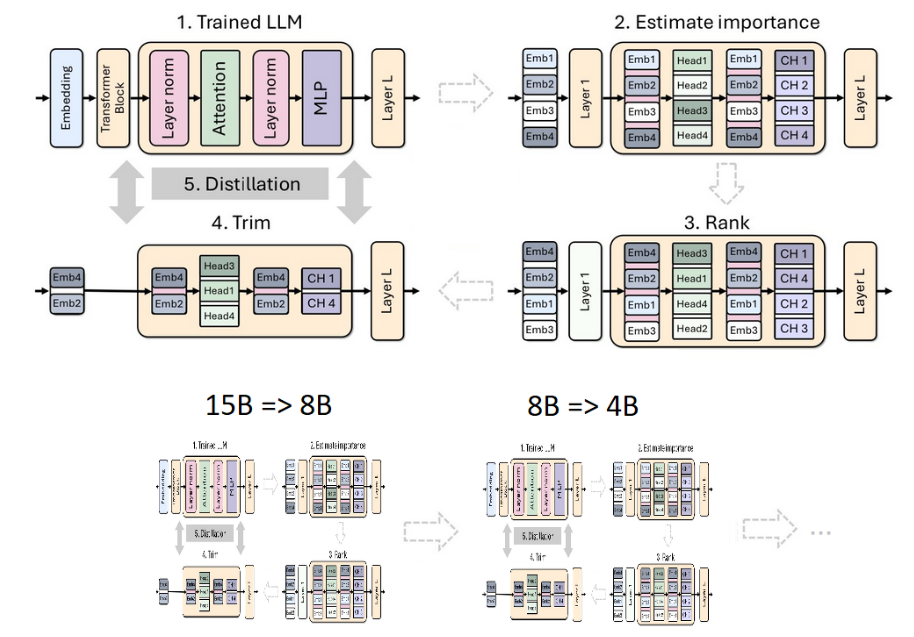
Prune and Distill Llama-3.1 8B
Blog: How to Prune and Distill Llama-3.1 8B to an NVIDIA Llama-3.1-Minitron 4B Model
FlashAttention-3
Paper: FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Blog: https://tridao.me/blog/2024/flash3/
The Ultimate Guide to Fine-Tuning LLMs
Paper: The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs
This site was last updated October 02, 2025.