AI Generated Content
This introduction includes Text-to-Image, Text-to-Video, Text-to-Motion, Text-to-3D, Image-to-3D.
Text-to-Image
News: An A.I.-Generated Picture Won an Art Prize. Artists Aren’t Happy.

Diffusion Models
Paper: High-Resolution Image Synthesis with Latent Diffusion Models
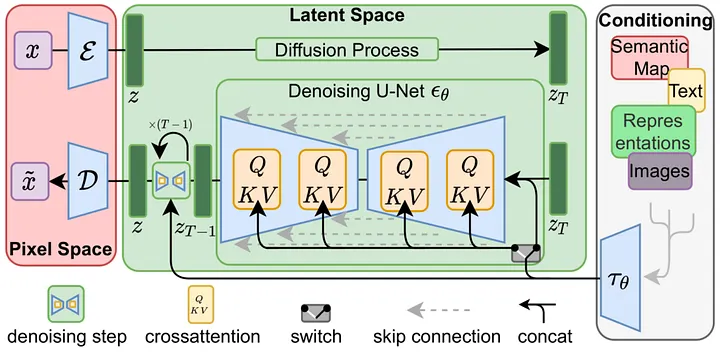
Blog: Introduction to Diffusion Models for Machine Learning
Diffusion Models are a method of creating data that is similar to a set of training data.
They train by destroying the training data through the addition of noise, and then learning to recover the data by reversing this noising process. Given an input image, the Diffusion Model will iteratively corrupt the image with Gaussian noise in a series of timesteps, ultimately leaving pure Gaussian noise, or “TV static”.
 The Diffusion Model will then work backwards, learning how to isolate and remove the noise at each timestep, undoing the destruction process that just occurred.
The Diffusion Model will then work backwards, learning how to isolate and remove the noise at each timestep, undoing the destruction process that just occurred.
Once trained, the model can then be “split in half”, and we can start from randomly sampled Gaussian noise which we use the Diffusion Model to gradually denoise in order to generate an image.

Midjourney
Model Versions
Version 6.1 was released on July 30, 2024 as the new default model. It produces more coherent images with more precise details and textures, and generates images approximately 25% faster than Version 6.


-
Forward Diffusion Process: The diffusion model starts by taking an input image and gradually adding Gaussian noise.
-
Noise Accumulation: The model continues to add more noise to the image. After each addition, randomized image sections are covered in noise until the original image is transformed into a noisy or grain-covered version. More noise will result in a more different generation, while less will produce a more similar generation to the original image.
-
Denoising Process: After adding the desired amount of noise, which Midjourney users can partially control with prompt weighting, the model learns to recover the original image by reversing the noising process.
-
Iterative Refinement: Denoising is performed iteratively, gradually reducing the noise level in the image. At each step, the diffusion model improves the image’s quality and ability to refine over time.
-
Training and Predictive Learning: The steps above repeat for as many images in the training dataset as possible. The model eventually learns to predict the original image from the noisy image.
-
Generating New Data: Once the model is trained, it creates new images by passing random noise samples and generating the colors and shapes from the patterns the model picked up during training. This creates unique images similar to the training data but slightly different, resulting in various possible outputs.
DALL.E, E2, and storyDALL-E
DALL.E
DALL·E is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions, using a dataset of text–image pairs.
Paper: Zero-Shot Text-to-Image Generation
Code: openai/DALL-E
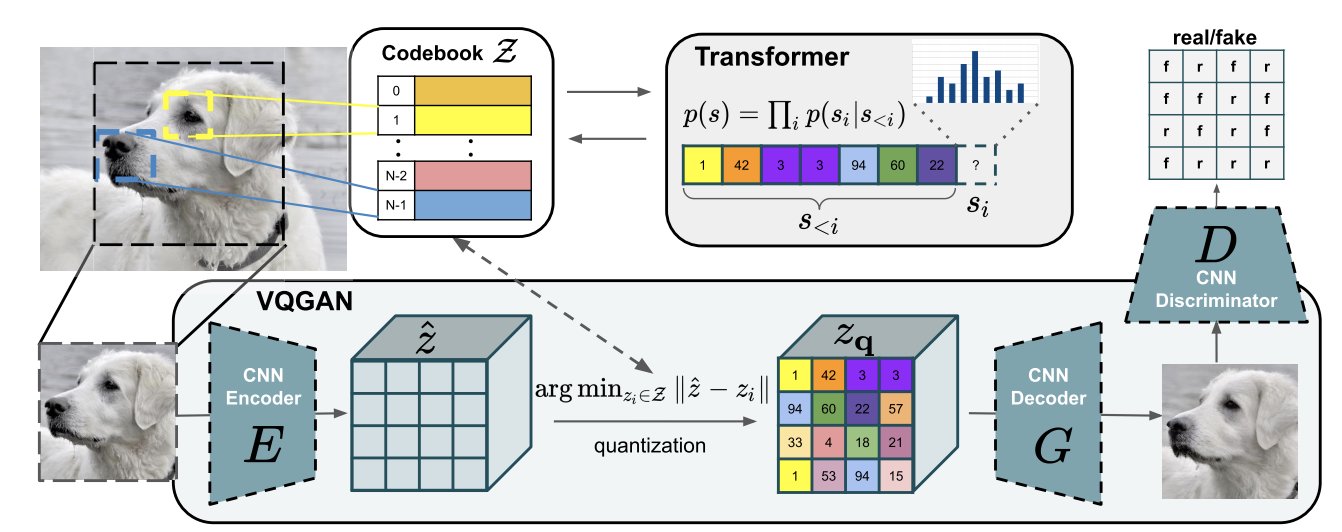
The overview of DALL-E could be illustrated as below. It contains two components: for image, VQGAN (vector quantized GAN) is used to map the 256x256 image to a 32x32 grid of image token and each token has 8192 possible values; then this token is combined with 256 BPE=encoded text token is fed into to train the autoregressive transformer. The text token is set to 256 by maximal.
DALL.E-2
Paper: Hierarchical Text-Conditional Image Generation with CLIP Latents
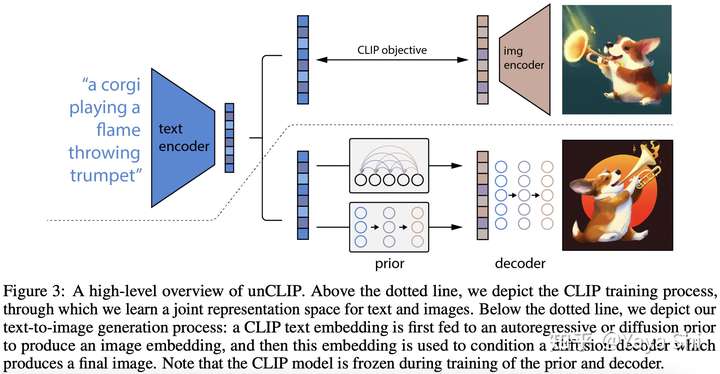
How Does DALL·E 2 Work?
Compared to DALL·E’s 12-billion parameters, DALL·E 2 works on a 3.5-billion parameter model and another 1.5-billion parameter model to enhance the resolution of its images.
DALL·E 2 image generation process

CLIP Training

Diffusion Models
 Diffusion models are transformer-based generative models. They take a piece of data, for example, a photo, and gradually add noise over timesteps, until it is not recognizable. And from that point, they try to reconstruct the image to its original form. In doing so, they learn how to generate images or any other kind of data.
Diffusion models are transformer-based generative models. They take a piece of data, for example, a photo, and gradually add noise over timesteps, until it is not recognizable. And from that point, they try to reconstruct the image to its original form. In doing so, they learn how to generate images or any other kind of data.
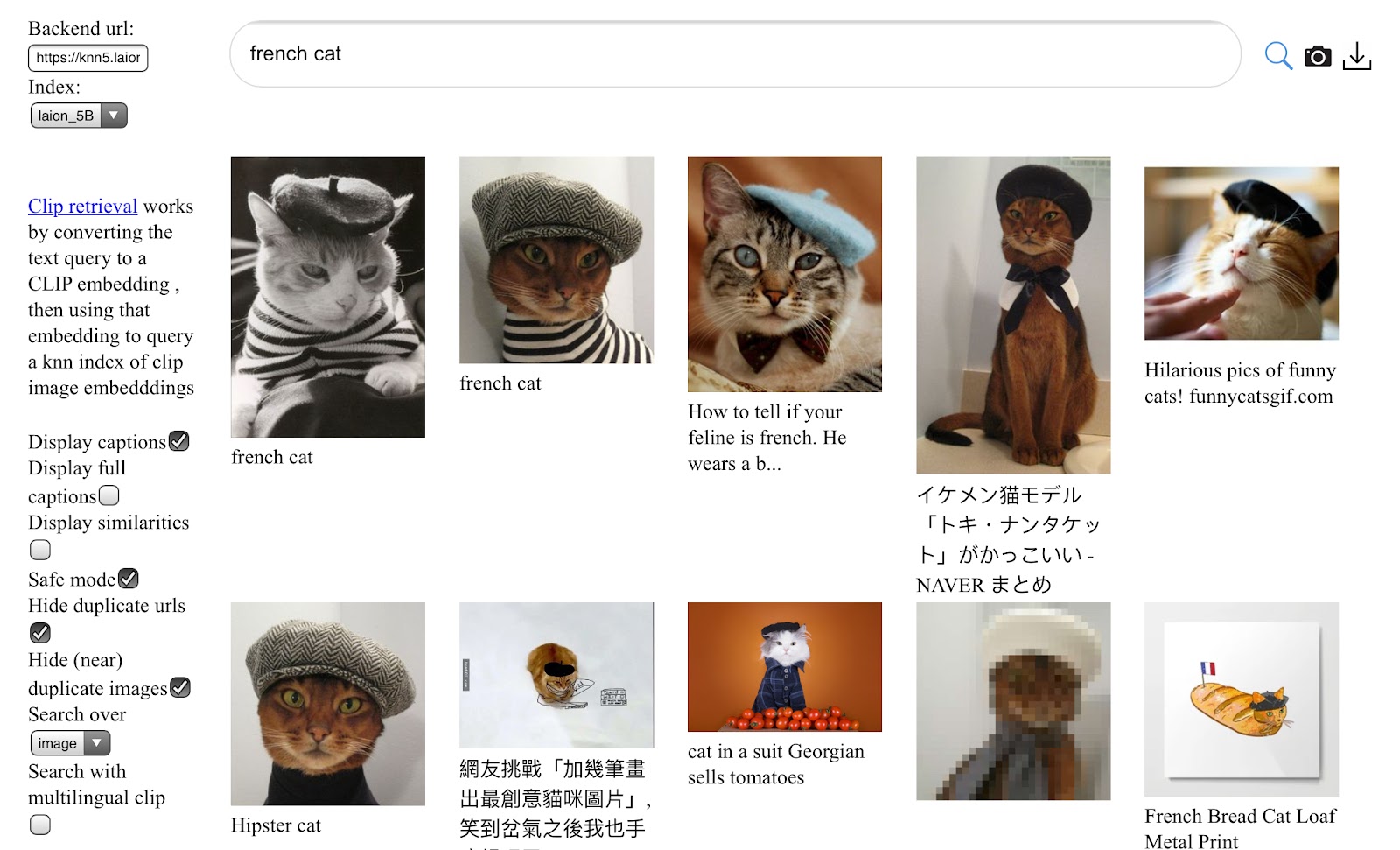
LAION-5B Dataset
5.85 billion CLIP-filtered image-text pairs
Paper: LAION-5B: An open large-scale dataset for training next generation image-text models
DALL.E-3
Paper: Improving Image Generation with Better Captions
Dataset Recaptioning

Stability.ai
Code: Stable Diffusion


Imagen
Paper: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Blog: How Imagen Actually Works

SDXL
Paper: SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Code: Generative Models by Stability AI


Huggingface: stable-diffusion-xl-base-1.0
 SDXL consists of an ensemble of experts pipeline for latent diffusion: In a first step, the base model is used to generate (noisy) latents, which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps. Note that the base model can be used as a standalone module.
SDXL consists of an ensemble of experts pipeline for latent diffusion: In a first step, the base model is used to generate (noisy) latents, which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps. Note that the base model can be used as a standalone module.
Kaggle: https://www.kaggle.com/code/rkuo2000/sdxl-base-1-0
Transfusion
Paper: Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Code: https://github.com/lucidrains/transfusion-pytorch
![]()
FLUX1.1 pro
- Superior Speed and Efficiency: Faster generation times and reduced latency, enabling more efficient workflows. FLUX1.1 [pro] is three times faster than the currently available FLUX.1 [pro].
- Improved Performance: FLUX1.1 [pro] has been introduced and tested under the codename “blueberry” into the Artificial Analysis image arena (https://artificialanalysis.ai/text-to-image), a popular benchmark for text-to-image models. It surpasses all other models on the leaderboard, achieving the highest overall Elo score.



ComfyGen
Paper: ComfyGen: Prompt-Adaptive Workflows for Text-to-Image Generation
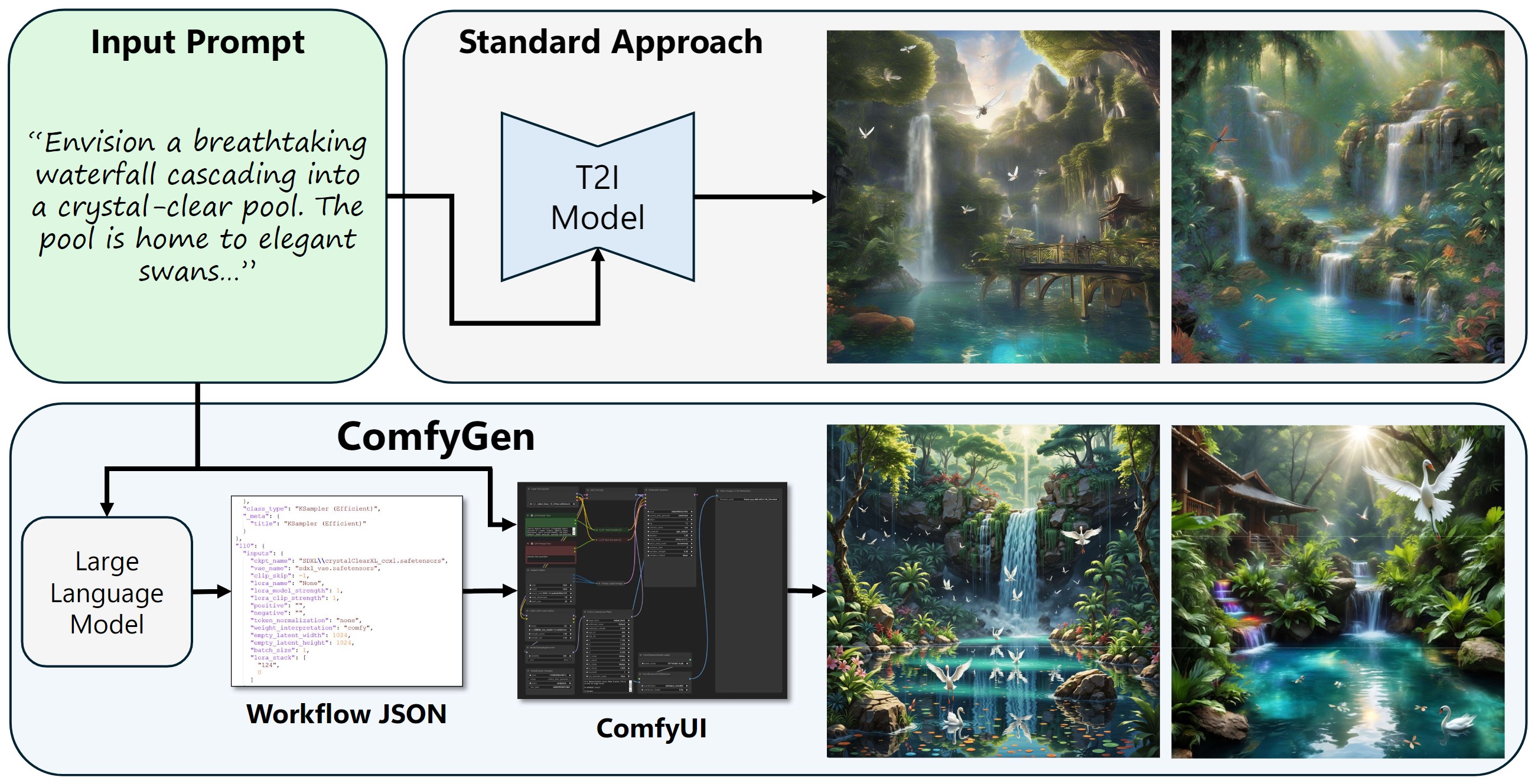

SD 3.5
model: stabilityai/stable-diffusion-3-medium
blog: ComfyUI Now Supports Stable Diffusion 3.5!

Krita
安裝與 ComfyUI 工作流匯入(建築景觀與室內設計應用)
FLUX.1[dev]模型在Krita完美整合
Text-to-Video
Turn-A-Video
Paper: Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Code: https://github.com/showlab/Tune-A-Video
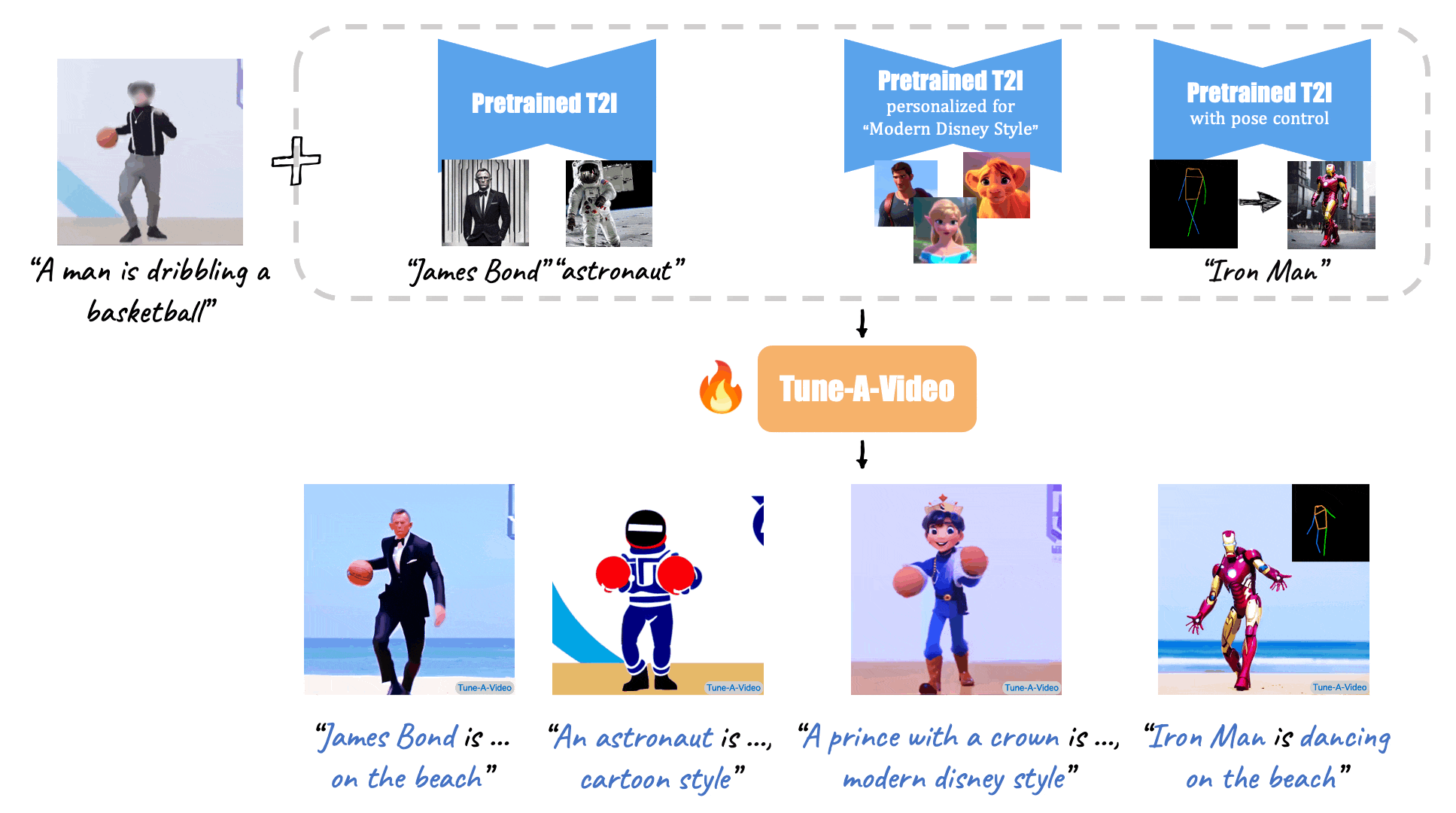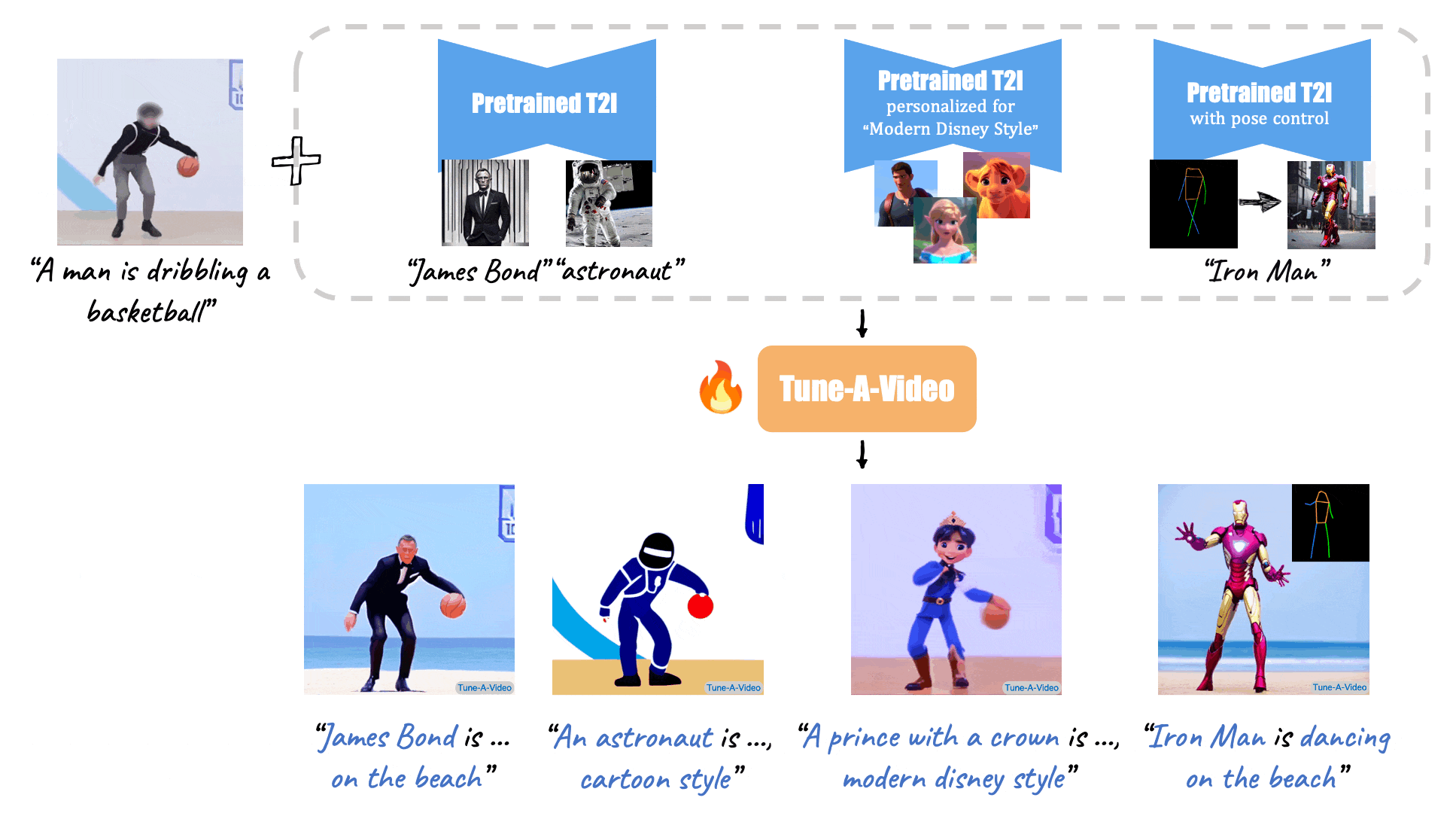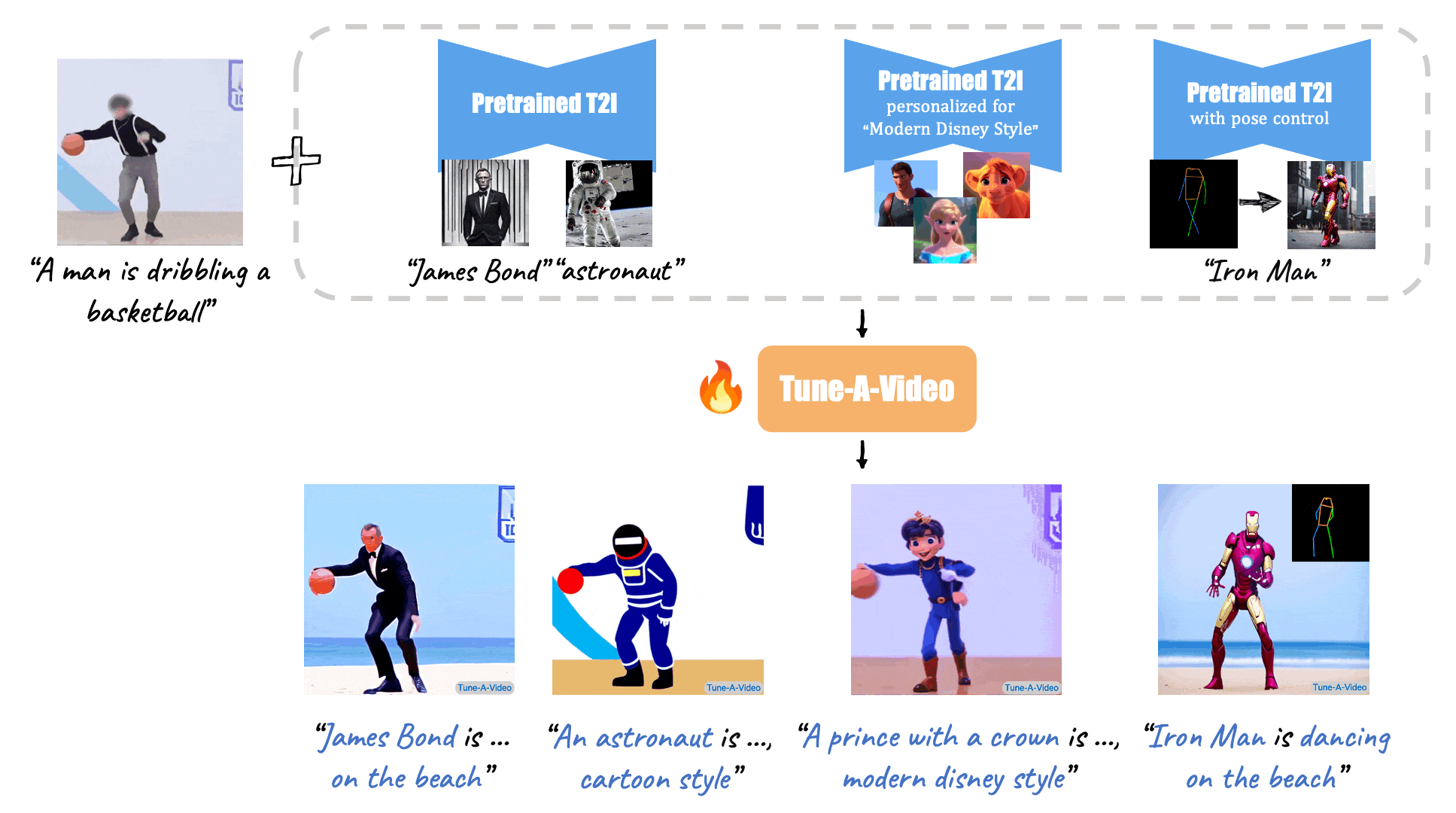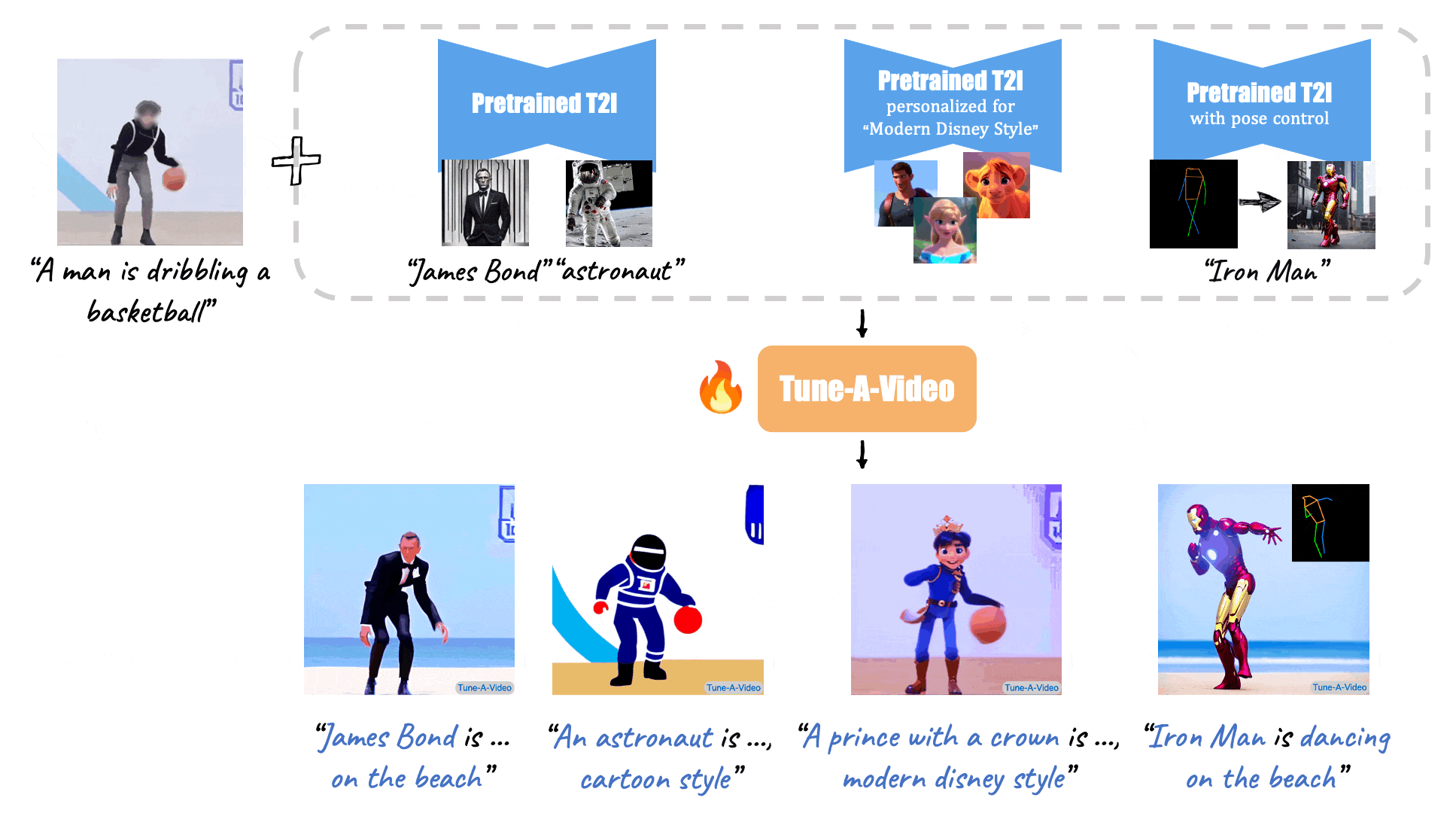
Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.
Open-VCLIP
Paper: Open-VCLIP: Transforming CLIP to an Open-vocabulary Video Model via Interpolated Weight Optimization
Paper: Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Code: https://github.com/wengzejia1/Open-VCLIP/

DyST
Paper: DyST: Towards Dynamic Neural Scene Representations on Real-World Videos
Text-to-Motion
TMR
Paper: TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis
Code: https://github.com/Mathux/TMR
Text-to-Motion Retrieval
Paper: Text-to-Motion Retrieval: Towards Joint Understanding of Human Motion Data and Natural Language
Code: https://github.com/mesnico/text-to-motion-retrieval
A person walks in a counterclockwise circle

A person is kneeling down on all four legs and begins to crawl

MotionDirector
Paper: MotionDirector: Motion Customization of Text-to-Video Diffusion Models
GPT4Motion
Paper: GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning
Motion Editing
Paper: Iterative Motion Editing with Natural Language
Awesome Video Diffusion Models
StyleCrafter
Paper: StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
Code: https://github.com/GongyeLiu/StyleCrafter

Stable Diffusion Video
Paper: Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Code: https://github.com/nateraw/stable-diffusion-videos

AnimateDiff
Paper: AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Paper: SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models
Code: https://github.com/guoyww/AnimateDiff

Animate Anyone
Paper: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
Outfit Anyone
Code: https://github.com/HumanAIGC/OutfitAnyone
SignLLM
Paper: SignLLM: Sign Languages Production Large Language Models
Code: https://github.com/SignLLM/Prompt2Sign
Text-to-3D
Shap-E
Paper: Shap-E: Generating Conditional 3D Implicit Functions
Code: https://github.com/openai/shap-e
Kaggle: https://www.kaggle.com/rkuo2000/shap-e
MVdiffusion
Paper: MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
Code: https://github.com/Tangshitao/MVDiffusion

MVDream
Paper: MVDream: Multi-view Diffusion for 3D Generation
Code: https://github.com/bytedance/MVDream
Kaggle: https://www.kaggle.com/rkuo2000/mvdream

3D-GPT
Paper: 3D-GPT: Procedural 3D Modeling with Large Language Models
Advances in 3D Generation : A Survey
Paper: Advances in 3D Generation: A Survey
AssetGen
Paper: [Meta 3D AssetGen: Text-to-Mesh Generation with High-Quality Geometry, Texture, and PBR Materials]
(https://scontent-tpe1-1.xx.fbcdn.net/v/t39.2365-6/449707112_509645168082163_2193712134508658234_n.pdf?_nc_cat=111&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=5bSbn3KaluAQ7kNvgFbjbd7&_nc_ht=scontent-tpe1-1.xx&oh=00_AYBM_JROjIFPbm8vwphinNrr4x1bUEFOeLV5iYsR6l_0rA&oe=668B3191)
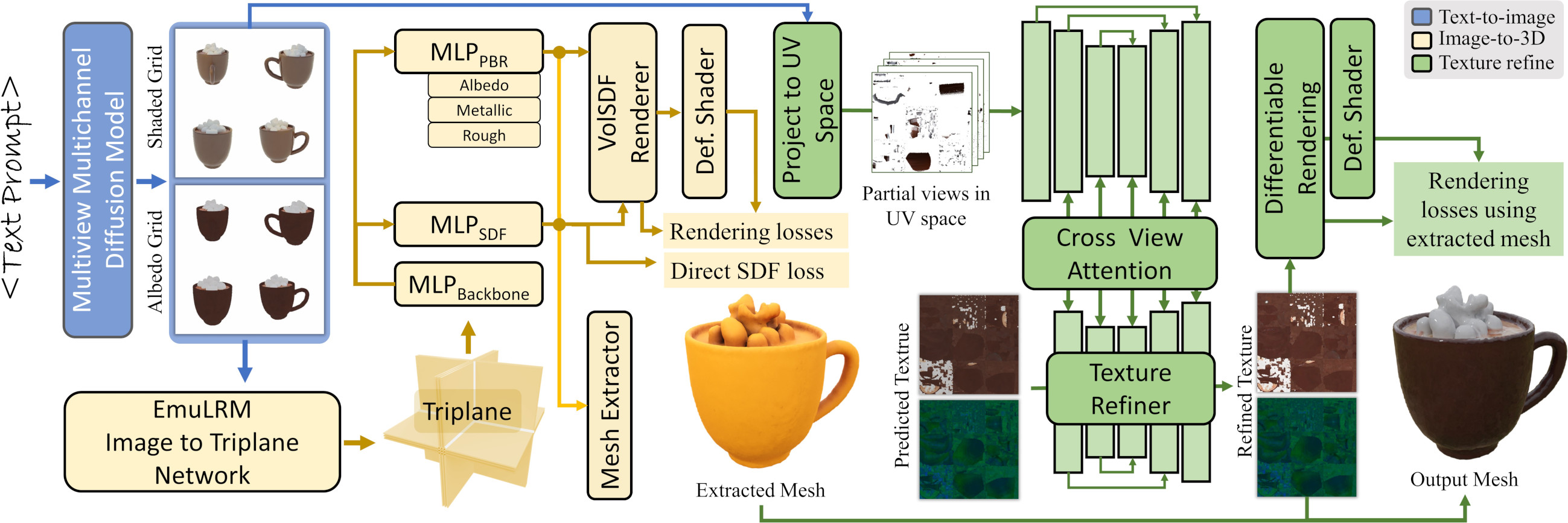 Paper: Meta 3D Gen
Paper: Meta 3D Gen
AI-Render
Stable Diffusion in Blender
Code: https://github.com/benrugg/AI-Render
Image-to-3D
Zero123++
Blog: Stable Zero123
Paper: Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Code: https://github.com/SUDO-AI-3D/zero123plus
Kaggle: https://www.kaggle.com/code/rkuo2000/zero123plus
Kaggle: https://www.kaggle.com/code/rkuo2000/zero123-controlnet
TripoSR
Blog: Introducing TripoSR: Fast 3D Object Generation from Single Images
Paper: LRM: Large Reconstruction Model for Single Image to 3D
Github: https://github.com/VAST-AI-Research/TripoSR
python run.py examples/chair.png --output-dir output/
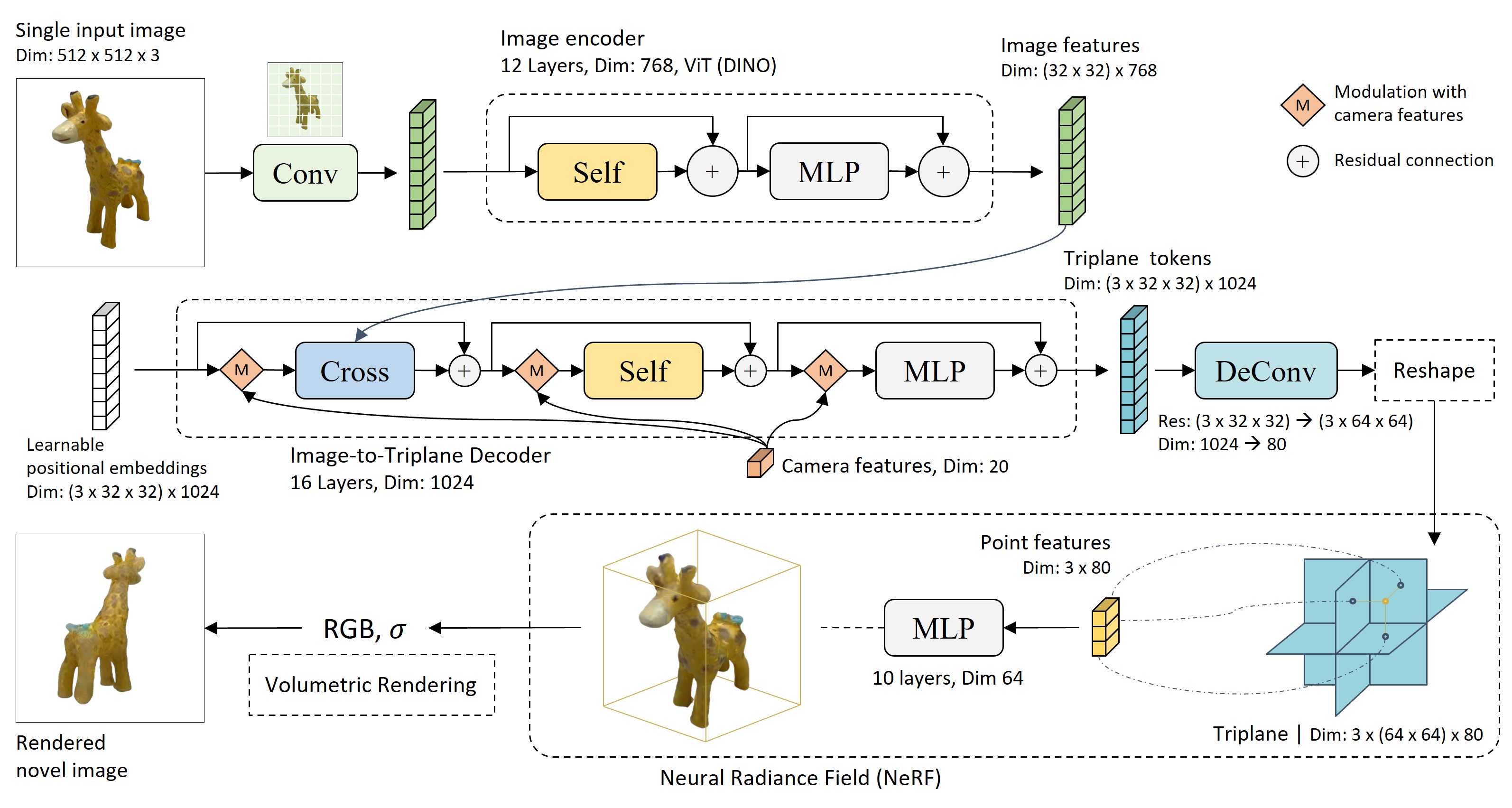
Depth Pro
Paper: Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Code: https://github.com/apple/ml-depth-pro

This site was last updated September 12, 2025.