Generative Music
This introduction includes Music Seperationm, Music Generation, etc.
Music Seperation
Spleeter
Paper: Spleeter: A FAST AND STATE-OF-THE ART MUSIC SOURCE
SEPARATION TOOL WITH PRE-TRAINED MODELS
Code: deezer/spleeter
Wave-U-Net
Paper: Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation
Code: f90/Wave-U-Net

Hyper Wave-U-Net
Paper: Improving singing voice separation with the Wave-U-Net using Minimum Hyperspherical Energy
Code: jperezlapillo/hyper-wave-u-net
MHE regularisation:

Demucs
Paper: Music Source Separation in the Waveform Domain
Code: facebookresearch/demucs
Kaggle: https://www.kaggle.com/code/rkuo2000/demucs
RVC vs SoftVC
“Retrieval-based Voice Conversion” 和 “SoftVC VITS Singing Voice Conversion” 是兩種聲音轉換技術的不同變種。以下是它們之間的一些區別:
1.方法原理:
Retrieval-based Voice Conversion:這種方法通常涉及使用大規模的語音資料庫或語音庫,從中檢索與輸入語音相似的聲音樣本,並將輸入語音轉換成與檢索到的聲音樣本相似的聲音。它使用檢索到的聲音作為目標來進行聲音轉換。
SoftVC VITS Singing Voice Conversion:這是一種基於神經網路的聲音轉換方法,通常使用變分自動編碼器(Variational Autoencoder,VAE)或其他神經網路架構。專注於歌聲轉換,它的目標是將輸入歌聲樣本轉換成具有不同特徵的歌聲,例如性別、音調等。
2.應用領域:
Retrieval-based Voice Conversion 通常用於語音轉換任務,例如將一個人的語音轉換成另一個人的語音。它也可以用於歌聲轉換,但在歌聲轉換方面通常不如專門設計的方法表現出色。
SoftVC VITS Singing Voice Conversion 主要用於歌聲轉換任務,特別是針對歌手之間的音樂聲音特徵轉換,例如將男性歌手的聲音轉換成女性歌手的聲音,或者改變歌曲的音調和音樂特徵。
3.技術複雜性:
Retrieval-based Voice Conversion 的實現通常較為簡單,因為它主要依賴於聲音樣本的檢索和聲音特徵的映射。
SoftVC VITS Singing Voice Conversion 更複雜,因為它需要訓練深度神經網路模型,可能需要大量的數據和計算資源。
Retrieval-based Voice Conversion
Blog: RVC-WebUI開源專案教學
Code: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
GPT-SoVITS
Blog: GPT-SoVITS 用 AI 快速複製你的聲音,搭配 Colab 免費入門
Code: https://github.com/RVC-Boss/GPT-SoVITS/
Kaggle: https://www.kaggle.com/code/rkuo2000/so-vits-svc-5-0
Music Generation
OpenAI Jukebox
Blog: Jukebox
model modified from VQ-VAE-2
Paper: Jukebox: A Generative Model for Music
Colab: Interacting with Jukebox
DeepSinger
Blog: Microsoft’s AI generates voices that sing in Chinese and English
Paper: DeepSinger: Singing Voice Synthesis with Data Mined From the Web
Demo: DeepSinger: Singing Voice Synthesis with Data Mined From the Web
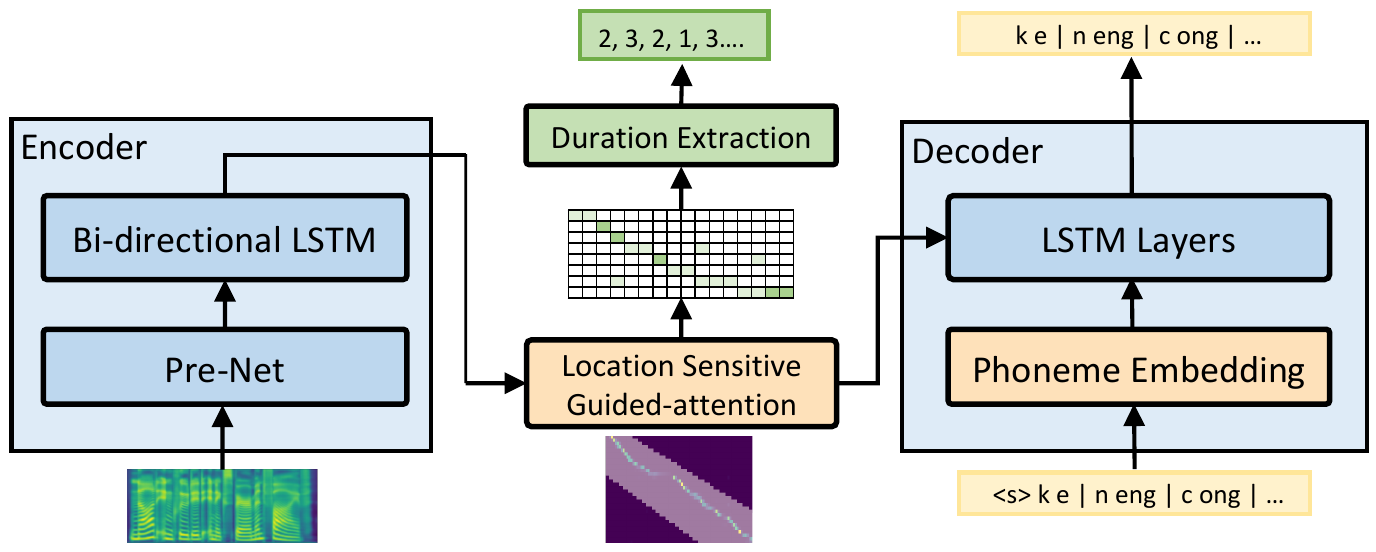
The alignment model based on the architecture of automatic speech recognition
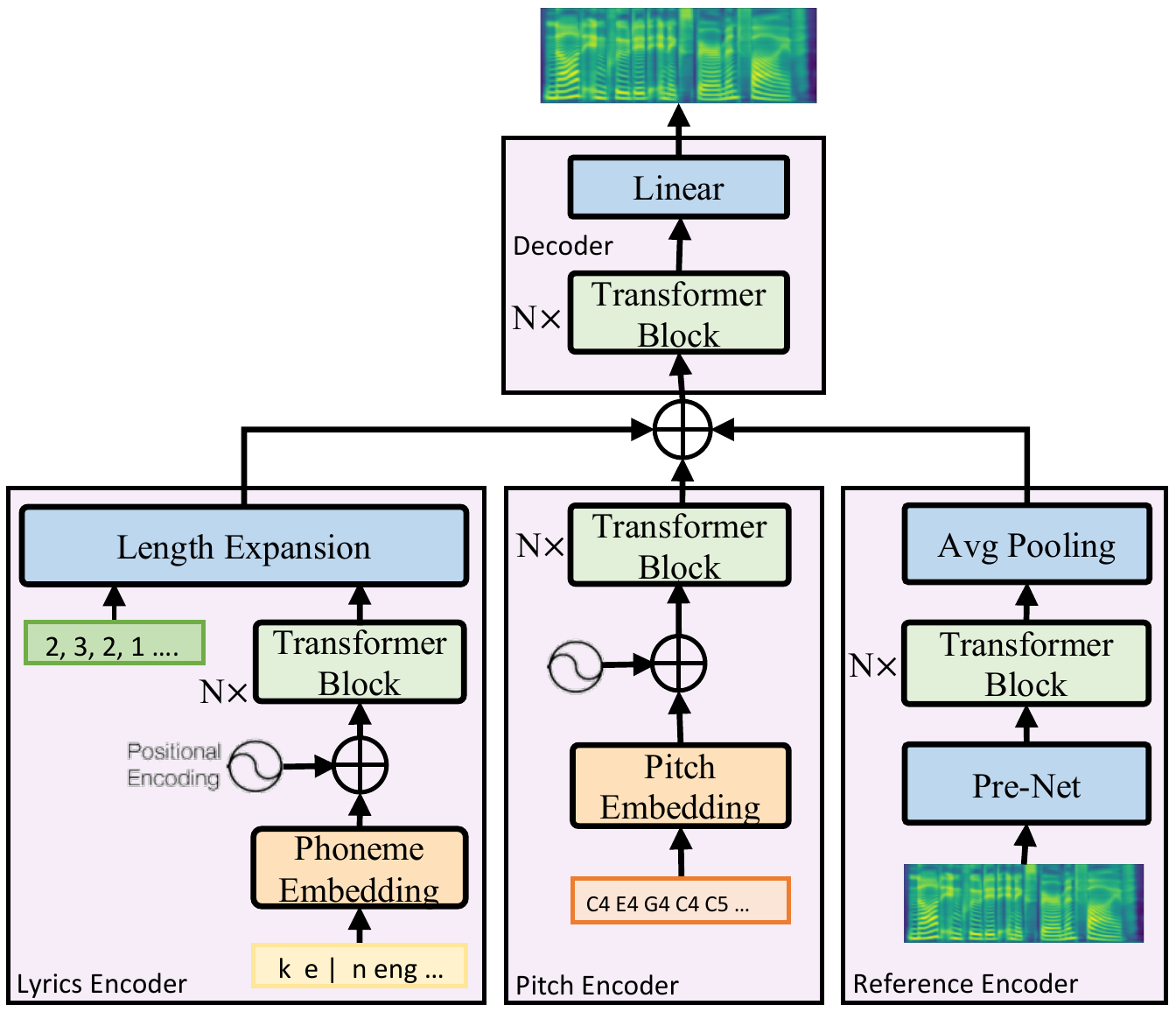
The architecture of the singing model
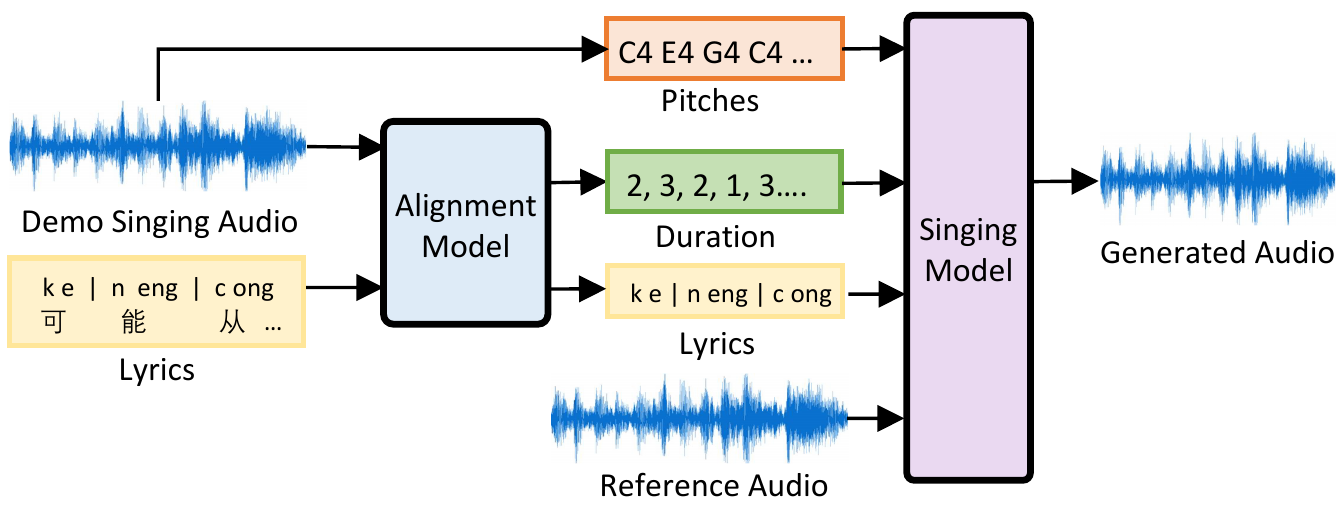
The inference process of singing voice synthesis
MusicGen
Paper: Simple and Controllable Music Generation
Code: https://github.com/facebookresearch/audiocraft
Tiny Audio Diffusion
Code: https://github.com/crlandsc/tiny-audio-diffusion
This site was last updated June 01, 2025.