Pose Estimation
Pose Estimation includes Applications, Human Pose Estimation, Head Pose Estimation & VTuber, Hand Pose Estimation , Object Pose Estimation.
Pose Estimation Applications
健身鏡
運動裁判 (Sport Referee)
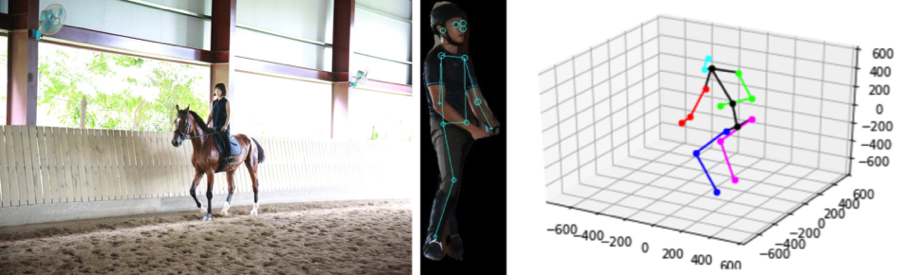
馬術治療
跌倒偵測
 |
 |
產線SOP
- 距離:人臉辨識技術,可辨識距離大約僅兩公尺以內,而人體骨幹技術不受距離限制,15 公尺外遠距離的人體也能精準偵測,進而分析人體外觀、四肢與臉部的特徵,以達到偵測需求。
- 角度:在正臉的情況下,臉部辨識的精準度非常高,目前僅有極少數相貌非常相似的同卵雙胞胎能夠騙過臉部辨識技術;但在非正臉的時候,臉部辨識的精準度就會急遽下降。在很多實際使用的場景,並不能要求每個參與者都靠近鏡頭、花幾秒鐘以正臉掃描辨識,在這種情況下,人體骨幹分析就能充分派上用場,它的精準度甚至比「非正臉的人臉辨識」高出 30% 以上。
Pose-controlled Lights

Human Pose Estimation
Benchmark: https://paperswithcode.com/task/pose-estimation
| Model Name | Paper | Code |
|---|---|---|
| PCT | https://arxiv.org/abs/2303.11638 | https://github.com/gengzigang/pct |
| ViTPose | https://arxiv.org/abs/2204.12484v3 | https://github.com/vitae-transformer/vitpose |
PoseNet
Paper: arxiv.org/abs/1505.07427
Code: rwightman/posenet-pytorch
Kaggle: PoseNet Pytorch
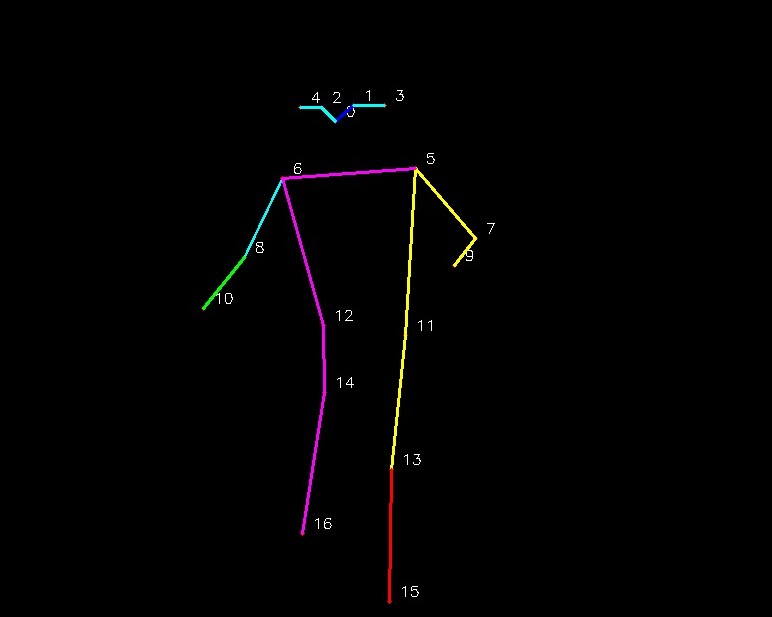

OpenPose
Paper: arxiv.org/abs/1812.08008
Code: CMU-Perceptual-Computing-Lab/openpose
Kaggle: OpenPose Pytorch


DensePose
Paper: arxiv.org/abs/1802.00434
Code: facebookresearch/DensePose
Multi-Person Part Segmentation
Paper: arxiv.org/abs/1907.05193
Code: kevinlin311tw/CDCL-human-part-segmentation

YOLO-Pose
Paper: YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
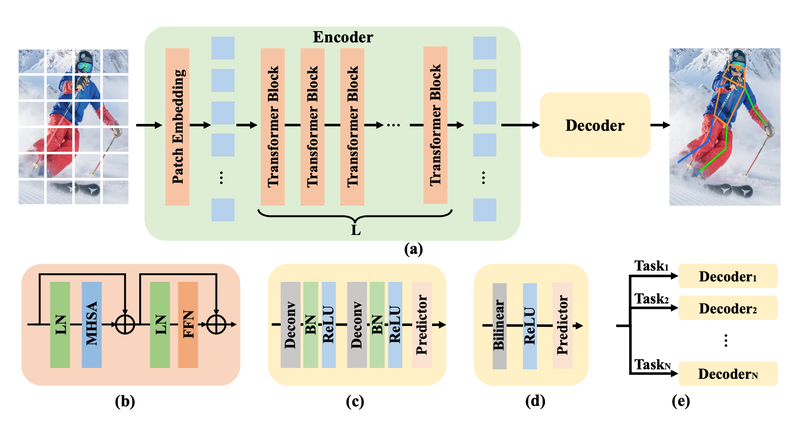
ViTPose
Paper: ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
Paper: ViTPose+: Vision Transformer Foundation Model for Generic Body Pose Estimation
Paper: ViTPose++: Vision Transformer for Generic Body Pose Estimation
Code: https://github.com/ViTAE-Transformer/ViTPose

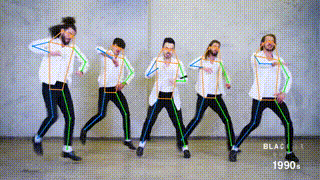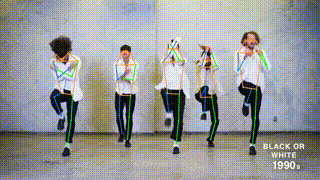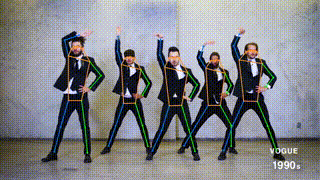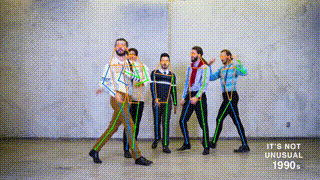
ED-Pose
Paper: Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation
Code: https://github.com/IDEA-Research/ED-Pose
 |
 |
OSX-UBody
Paper: One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer
Code: https://github.com/IDEA-Research/OSX

Human Pose as Compositional Tokens
Paper: https://arxiv.org/abs/2303.11638
Code: https://github.com/gengzigang/pct


DWPose
Paper: Effective Whole-body Pose Estimation with Two-stages Distillation
Code: https://github.com/IDEA-Research/DWPose

Group Pose
Paper: Group Pose: A Simple Baseline for End-to-End Multi-person Pose Estimation
Code: https://github.com/Michel-liu/GroupPose

YOLOv8 Pose
Kaggle: https://www.kaggle.com/rkuo2000/yolov8-pose
MMPose
Algorithms
Code: https://github.com/open-mmlab/mmpose
- support two new datasets: UBody, 300W-LP
- support for four new algorithms: MotionBERT, DWPose, EDPose, Uniformer
3D Human Pose Estimation
Benchmark: https://paperswithcode.com/task/3d-human-pose-estimation
MotionBERT
Paper: MotionBERT: A Unified Perspective on Learning Human Motion Representations
Code: https://github.com/Walter0807/MotionBERT
BCP+VHA R152 384x384
Paper: Representation learning of vertex heatmaps for 3D human mesh reconstruction from multi-view images
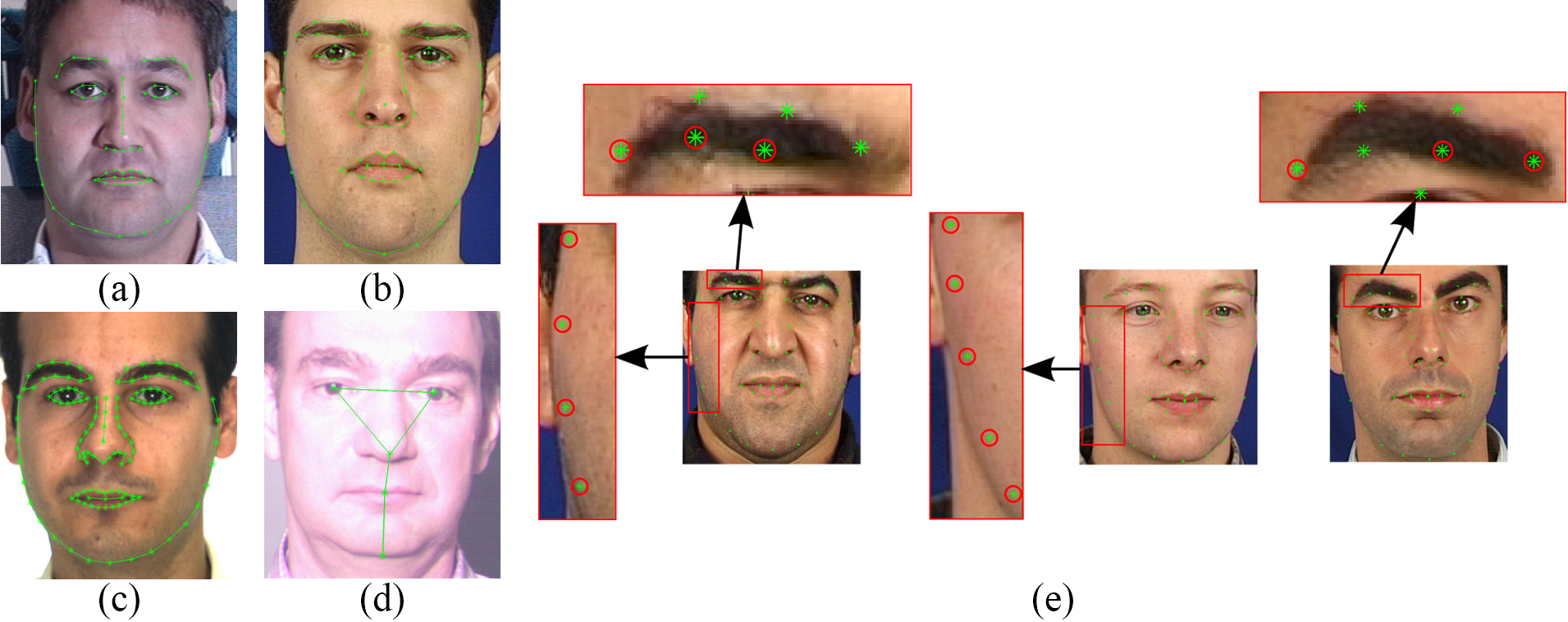
Face Datasets
300-W: 300 Faces In-the-Wild

300W-LPA: 300W-LPA Database

LFPW: Labeled Face Parts in the Wild (LFPW) Dataset

HELEN: Helen dataset

AFW: Annotated Faces in the Wild
AFW (Annotated Faces in the Wild) is a face detection dataset that contains 205 images with 468 faces. Each face image is labeled with at most 6 landmarks with visibility labels, as well as a bounding box.

IBUG: https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/
Head Pose Estimation
Code: yinguobing/head-pose-estimation
Kaggle: https://www.kaggle.com/rkuo2000/head-pose-estimation
 |
 |
HopeNet
Paper: Fine-Grained Head Pose Estimation Without Keypoints
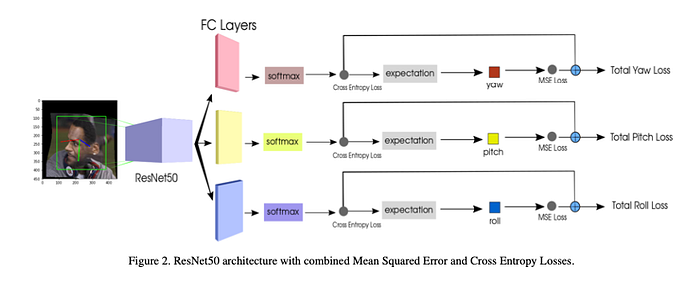
Code: Hopenet
Code: https://github.com/natanielruiz/deep-head-pose

Blog: HOPE-Net : A Machine Learning Model for Estimating Face Orientation
VTuber
Vtuber總數突破16000人,增速不緩一年增加3000人 依據日本數據調查分析公司 User Local 的報告,在該社最新的 User Local VTuber 排行榜上,有紀錄的 Vtuber 正式突破了 16,000 人。
1位 Gawr Gura(がうるぐら サメちゃん) Gawr Gura Ch. hololive-EN
VTuber-Unity = Head-Pose-Estimation + Face-Alignment + GazeTracking
VRoid Studio
VTuber_Unity

OpenVtuber

Hand Pose Estimation
Hand3D
Paper: arxiv.org/abs/1705.01389
Code: lmb-freiburg/hand3d

InterHand2.6M
Paper: https://arxiv.org/abs/2008.09309
Code: https://github.com/facebookresearch/InterHand2.6M
Dataset: Re:InterHand Dataset

InterWild
Paper: Bringing Inputs to Shared Domains for 3D Interacting Hands Recovery in the Wild
Code: https://github.com/facebookresearch/InterWild/tree/main#test

 |
 |
 |
 |
 |
 |
RenderIH
Paper: RenderIH: A Large-scale Synthetic Dataset for 3D Interacting Hand Pose Estimation
Code: https://github.com/adwardlee/RenderIH
TransHand - transformer-based pose estimation network
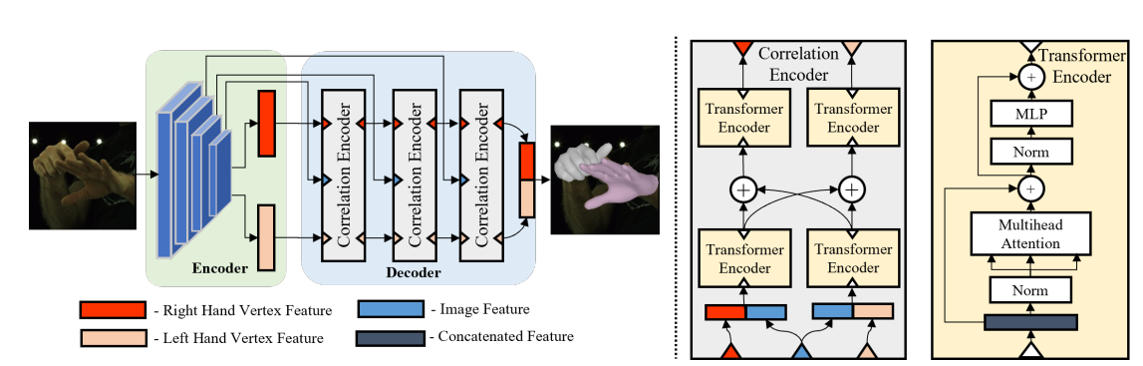
Exercises of Pose Estimation
PoseNet
Kaggle: https://www.kaggle.com/rkuo2000/posenet-pytorch
Kaggle: https://www.kaggle.com/rkuo2000/posenet-human-pose

OpenPose
Kaggle: https://github.com/rkuo2000/openpose-pytorch


MMPose
Kaggle:https://www.kaggle.com/rkuo2000/mmpose
2D Human Pose

2D Human Whole-Body

2D Hand Pose

2D Face Keypoints

3D Human Pose

2D Pose Tracking

2D Animal Pose

3D Hand Pose

WebCam Effect

Basketball Referee
Code: AI Basketball Referee
該AI主要追蹤兩個東西:球的運動軌跡和人的步數, using YOLOv8 Pose
Head Pose Estimation
Kaggle: https://kaggle.com/rkuo2000/head-pose-estimation
VTuber-Unity
Head-Pose-Estimation + Face-Alignment + GazeTracking
Build-up Steps:
- Create a character: VRoid Studio
- Synchronize the face: VTuber_Unity
- Take video: OBS Studio
- Post-processing:
- Auto-subtitle: Autosub
- Auto-subtitle in live stream: Unity_live_caption
- Encode the subtitle into video: 小丸工具箱
- Upload: YouTube
- [Optional] Install CUDA & CuDNN to enable GPU acceleration
- To Run
$git clone https://github.com/kwea123/VTuber_Unity
$python demo.py --debug --cpu
OpenVtuber
Build-up Steps:
- Repro Github
$git clone https://github.com/1996scarlet/OpenVtuber
$cd OpenVtuber
$pip3 install –r requirements.txt - Install node.js for Windows
- run Socket-IO Server
$cd NodeServer
$npm install express socket.io
$node. index.js - Open a browser at http://127.0.0.1:6789/kizuna
- PythonClient with Webcam
$cd ../PythonClient
$python3 vtuber_link_start.py
This site was last updated June 01, 2025.