Image Segmentation
Image Segmentation includes Image Matting, Semantics Segmentation, Human Part Segmentation, Instance Segmentation, Video Object Segmentation, Panopitc Segmentation.
Paper: Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey

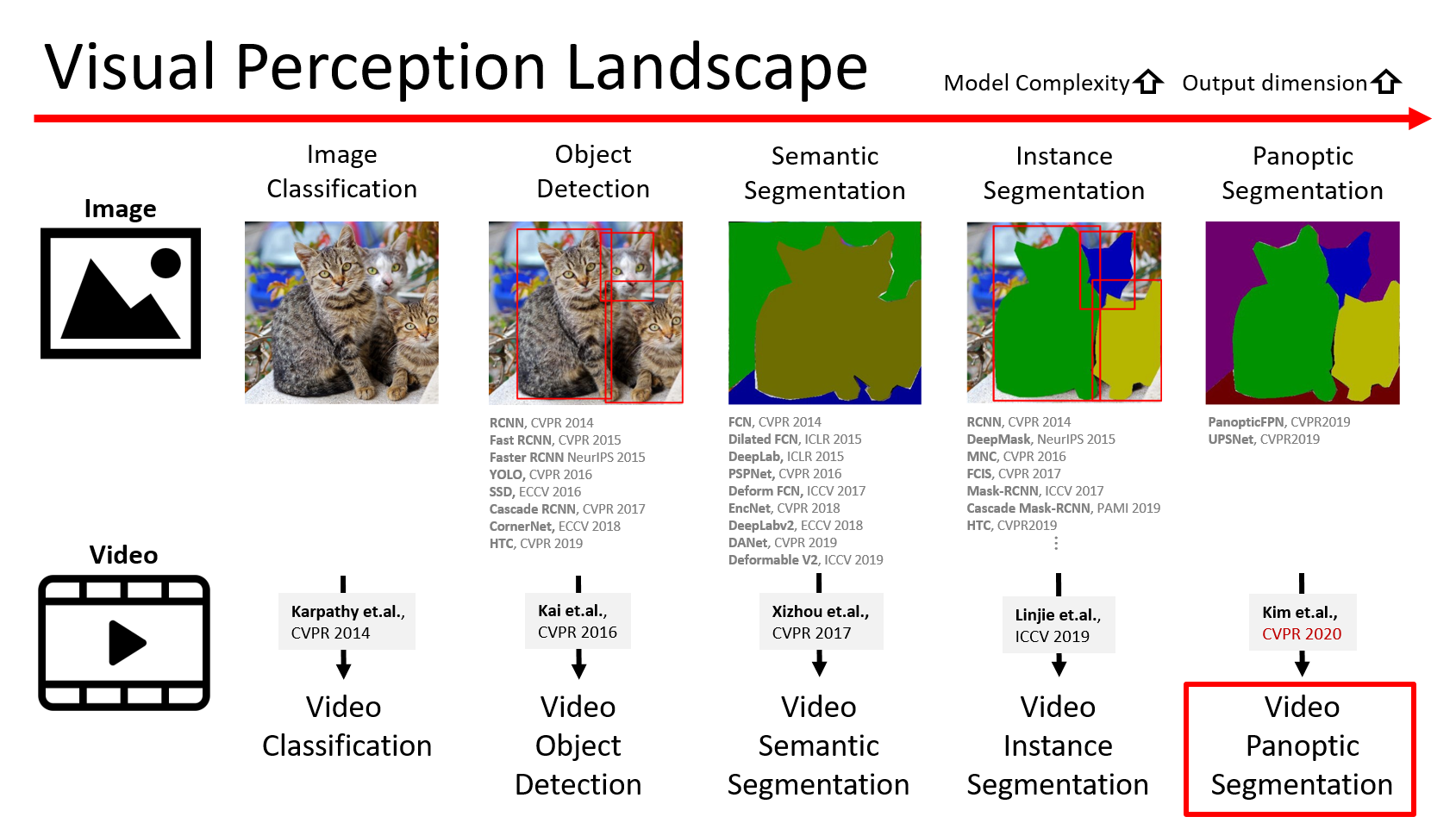
Paper: Image Segmentation Using Deep Learning: A Survey
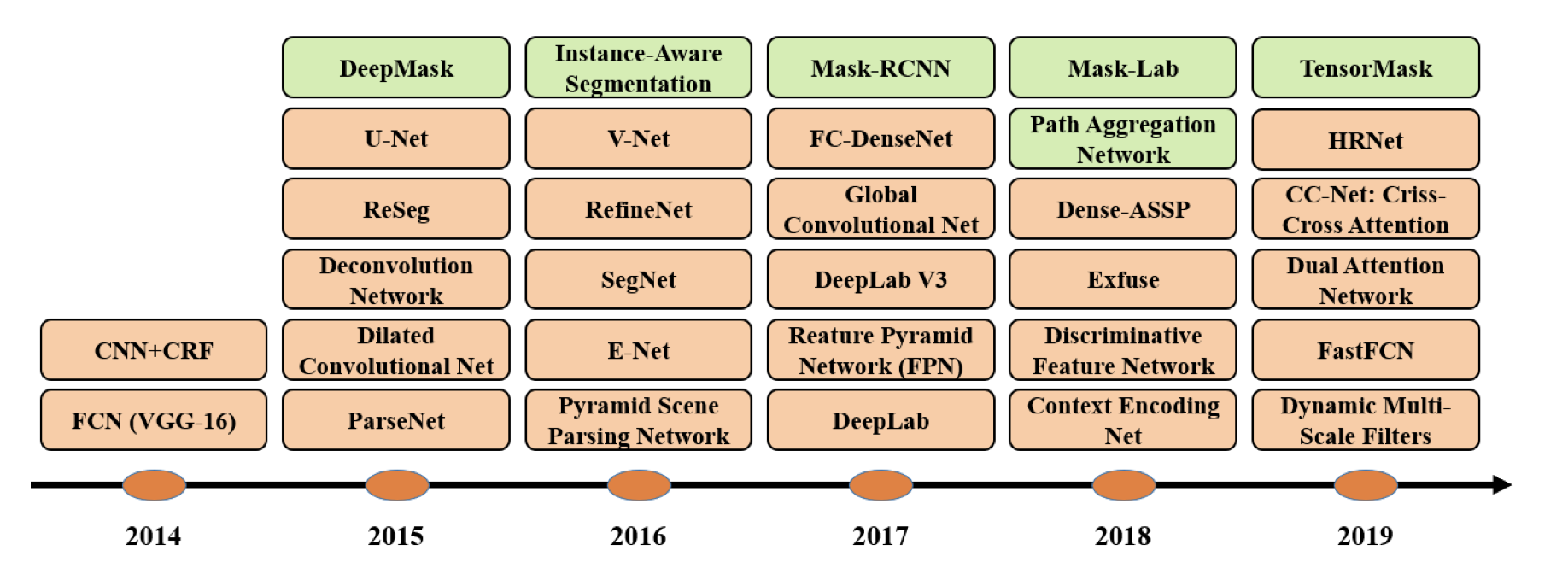
Image Matting
Image Matting is the process of accurately estimating the foreground object in images and videos.

Deep Image Matting
Paper: arxiv.org/abs/1703.03872

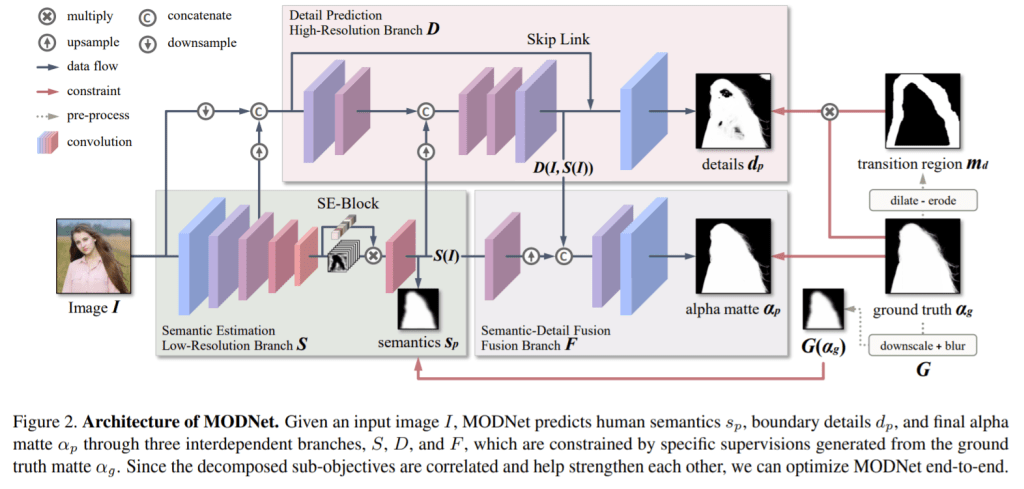
MODNet: Trimap-Free Portrait Matting in Real Time
Paper: arxiv.org/abs/2011.11961
Code: ZHKKKe/MODNet

Kaggle: rkuo2000/modnet-image-matting


PaddleSeg: A High-Efficient Development Toolkit for Image Segmentation
Paper: MODNet: Real-Time Trimap-Free Portrait Matting via Objective Decomposition
Code: PaddlePaddle/PaddleSeg
BiseNetV2 model

Four segmentation areas: semantic segmentation, interactive segmentation, panoptic segmentation and image matting.
 Various applications in autonomous driving, medical segmentation, remote sensing, quality inspection, and other scenarios.
Various applications in autonomous driving, medical segmentation, remote sensing, quality inspection, and other scenarios.

Semantic Image Matting
Paper: arxiv.org/abs/2104.08201
Code: nowsyn/SIM

 |
 |
Semantic Segmentation (意義分割)
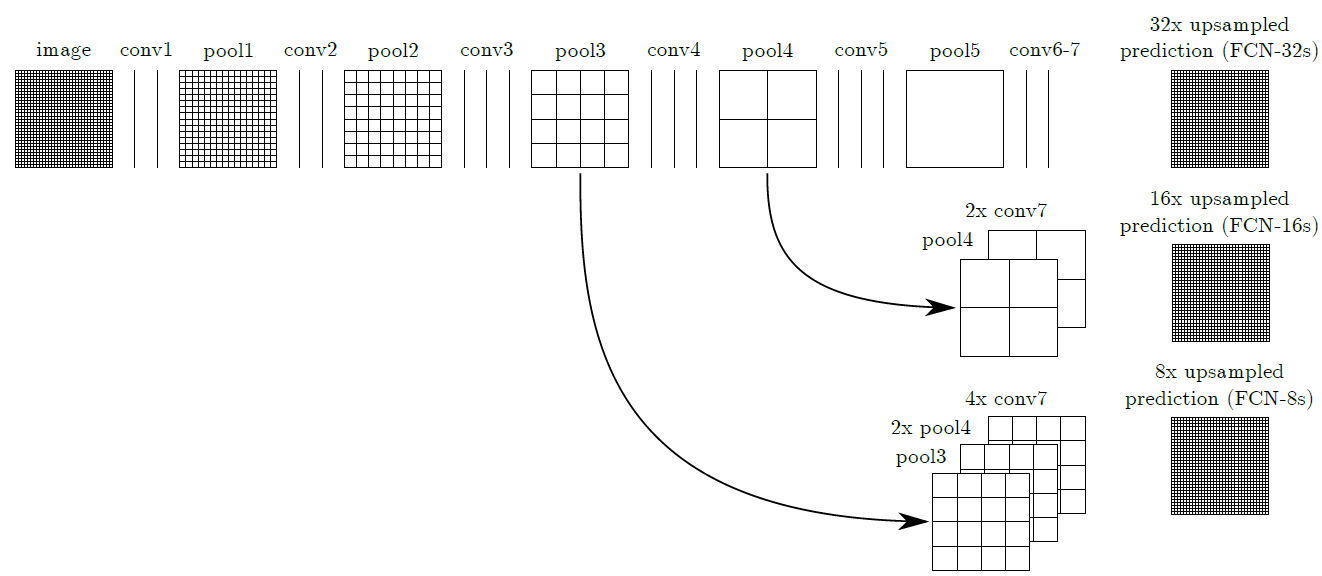
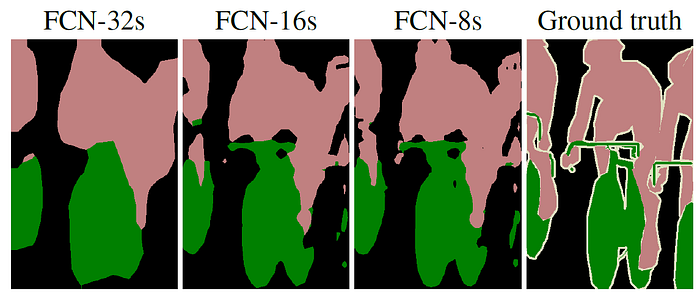
FCN - Fully Convolutional Networks
Paper: Fully Convolutional Networks for Semantic Segmentation
Code: https://github.com/hayoung-kim/tf-semantic-segmentation-FCN-VGG16
Blog: FCN for Semantic Segmentation簡介
FCN Architecture
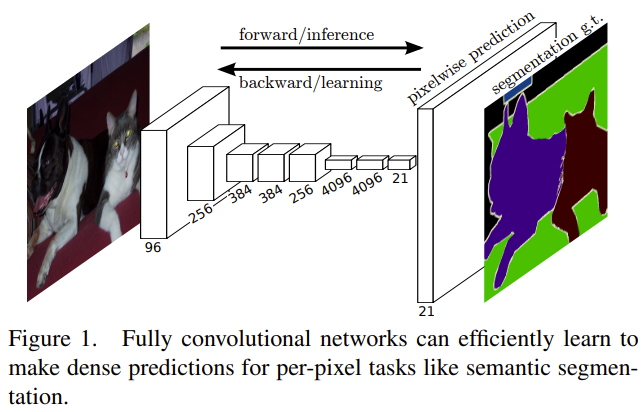 FCN-8 Architecture
FCN-8 Architecture
 Conv & DeConv
Conv & DeConv
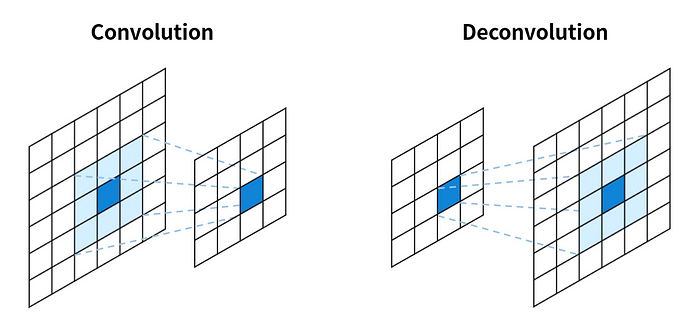
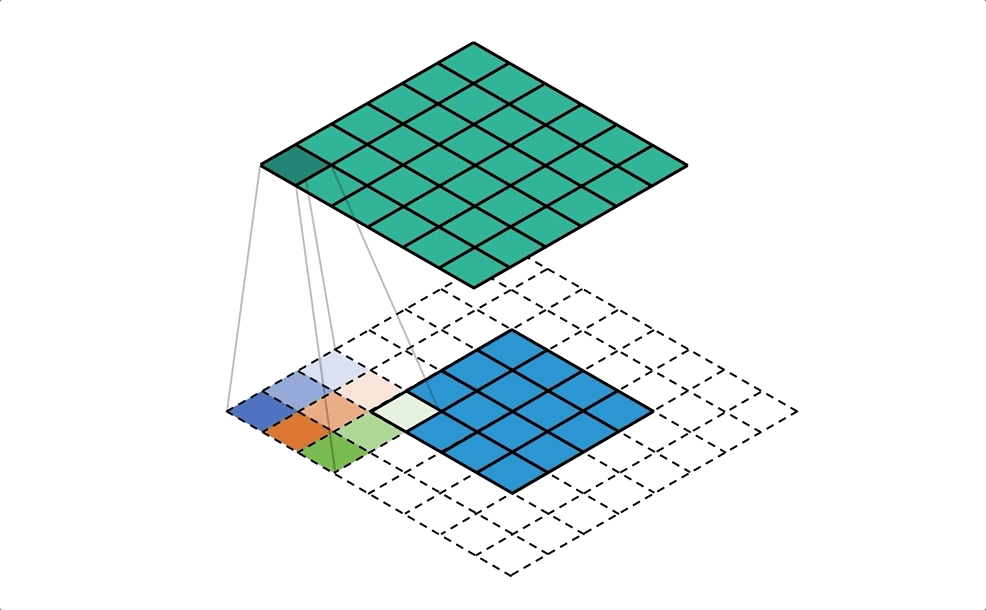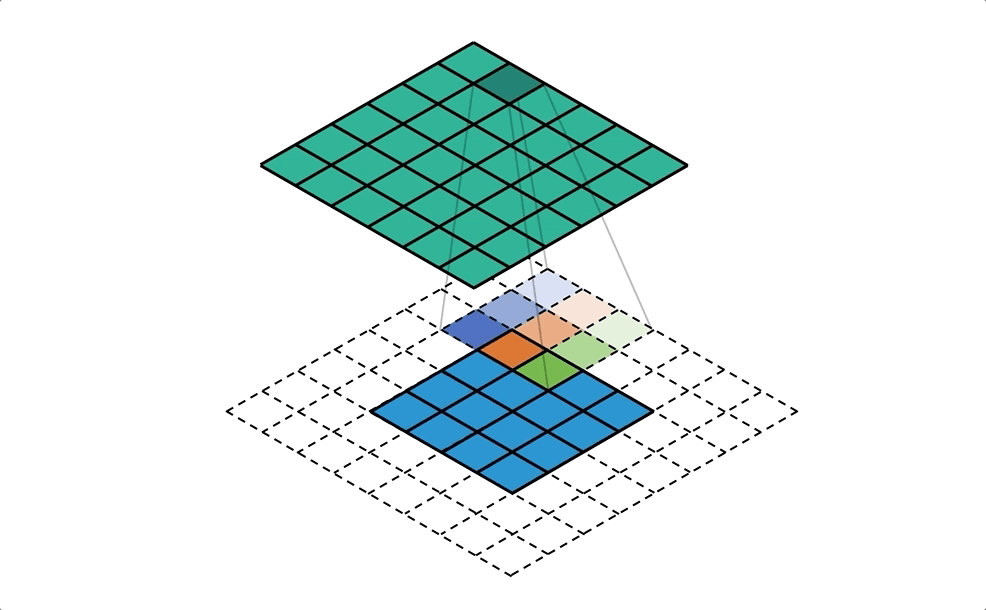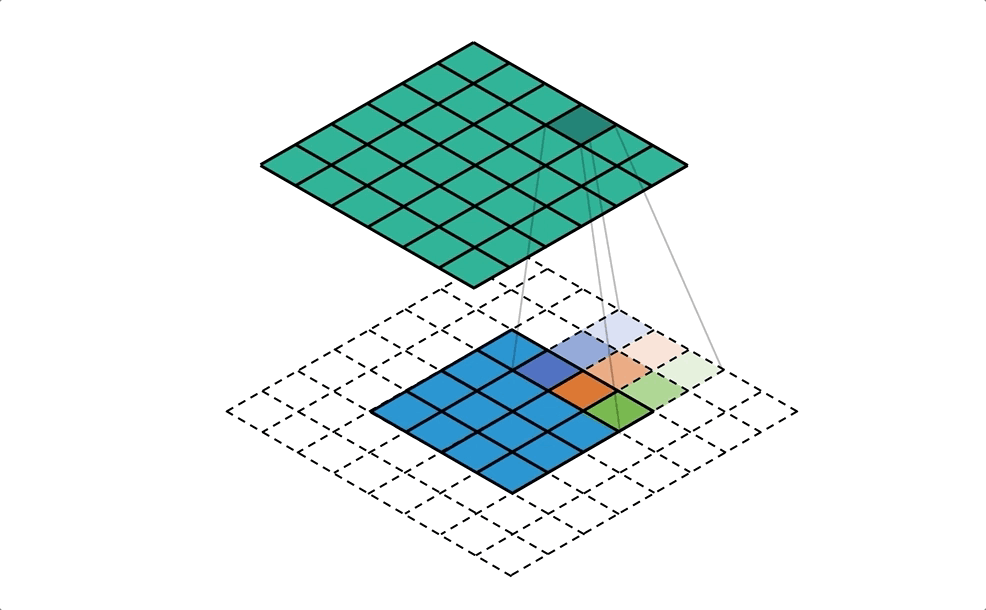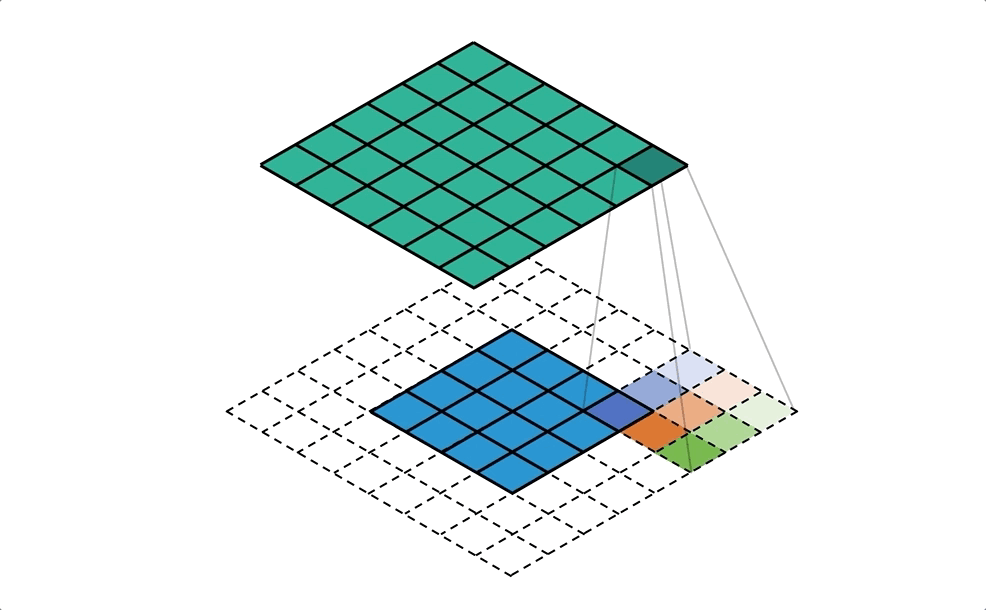

SegNet - A Deep Convolutional Encoder-Decoder Architecture
Paper: arxiv.org/abs/1511.00561
Code: github.com/yassouali/pytorch_segmentation

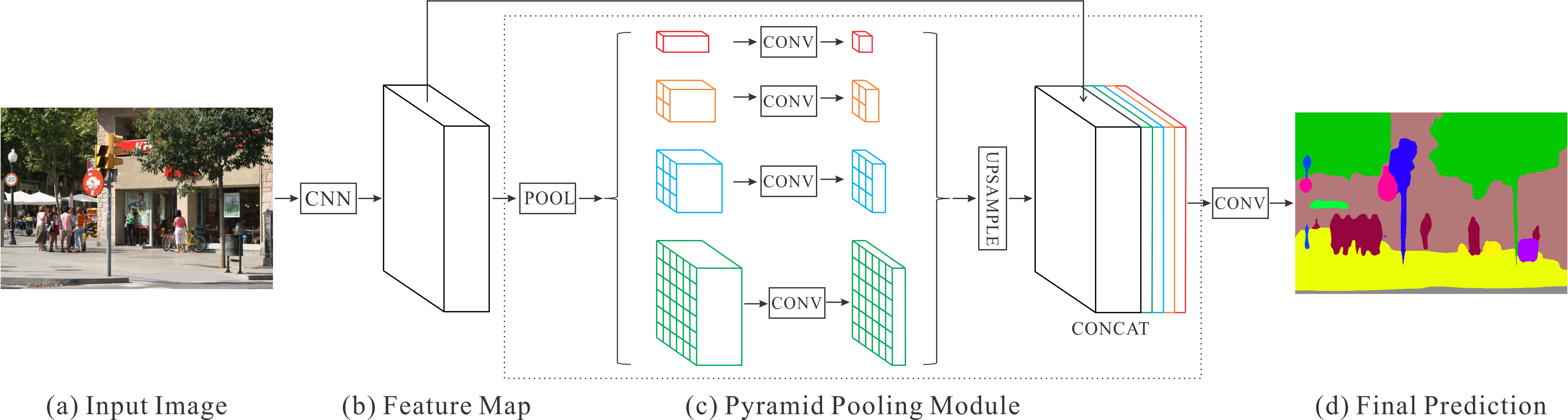
PSPNet - Pyramid Scene Parsing Network
Paper: arxiv.org/abs/1612.01105
Code: github.com/hszhao/semseg (PSPNet, PSANet in PyTorch)
Kaggle: https://www.kaggle.com/code/rkuo2000/image-segmentation-keras


DeepLab V3+
Paper: arxiv.org/abs/1802.02611
Code: github.com/bonlime/keras-deeplab-v3-plus
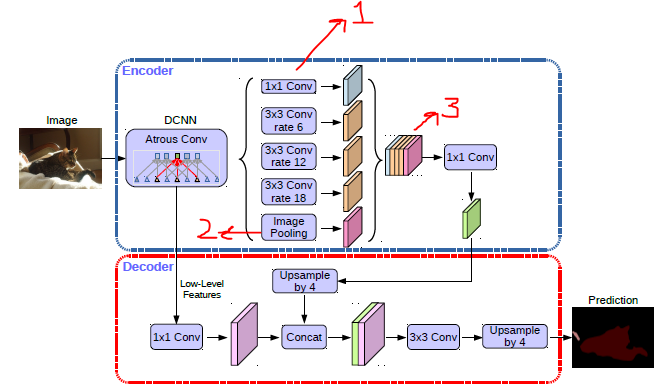
Kaggle: rkuo2000/deeplabv3-plus

Semantic Segmentation on MIT ADE20K
Code: github.com/CSAILVision/semantic-segmentation-pytorch
Dataset: MIT ADE20K, Models: PSPNet, UPerNet, HRNet


Kaggle: https://www.kaggle.com/code/rkuo2000/semantic-segmentation

Semantic Segmentation on PyTorch
Code: Tramac/awesome-semantic-segmentation-pytorch
Datasets: Pascal VOC, CityScapes, ADE20K, MSCOCO
Models:
- FCN
- ENet
- PSPNet
- ICNet
- DeepLabv3
- DeepLabv3+
- DenseASPP
- EncNet
- BiSeNet
- PSANet
- DANet
- OCNet
- CGNet
- ESPNetv2
- DUNet(DUpsampling)
- FastFCN(JPU)
- LEDNet
- Fast-SCNN
- LightSeg
- DFANet
USNet
Paper: Fast Road Segmentation via Uncertainty-aware Symmetric Network
Code: https://github.com/morancyc/USNet


Segment Anything (by Meta)
Paper: https://arxiv.org/abs/2304.02643
The Segment Anything Model (SAM) produces high quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image. It has been trained on a dataset of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.
Code: https://github.com/facebookresearch/segment-anything


Kaggle: https://www.kaggle.com/code/rkuo2000/segment-anything

Segment Everything Everywhere All at Once (by Microsoft)
Paper: https://arxiv.org/abs/2304.06718
Code: UX-Decoder/Segment-Everything-Everywhere-All-At-Once

Kaggle: https://www.kaggle.com/code/rkuo2000/fastsam

Fast Segment Anything
Paper: https://arxiv.org/abs/2306.12156
Code: CASIA-IVA-Lab/FastSAM
Kaggle: https://www.kaggle.com/code/rkuo2000/fastsam

SAM 2: Segment Anything in Images and Videos
Blog: Introducing SAM 2: The next generation of Meta Segment Anything Model for videos and images
Paper: SAM 2: Segment Anything in Images and Videos
Code: https://github.com/facebookresearch/segment-anything-2
 Kaggle: https://www.kaggle.com/code/rkuo2000/segment-anything-2
Kaggle: https://www.kaggle.com/code/rkuo2000/segment-anything-2
U-Net
U-Net
Paper: arxiv.org/abs/1505.04597
Code: U-Net Keras

3D U-Net
Paper: arxiv.org/abs/1606.06650

Brain Tumor Segmentation
Dataset: Brain Tumor Segmentation(BraTS2020)
Code: https://www.kaggle.com/polomarco/brats20-3dunet-3dautoencoder
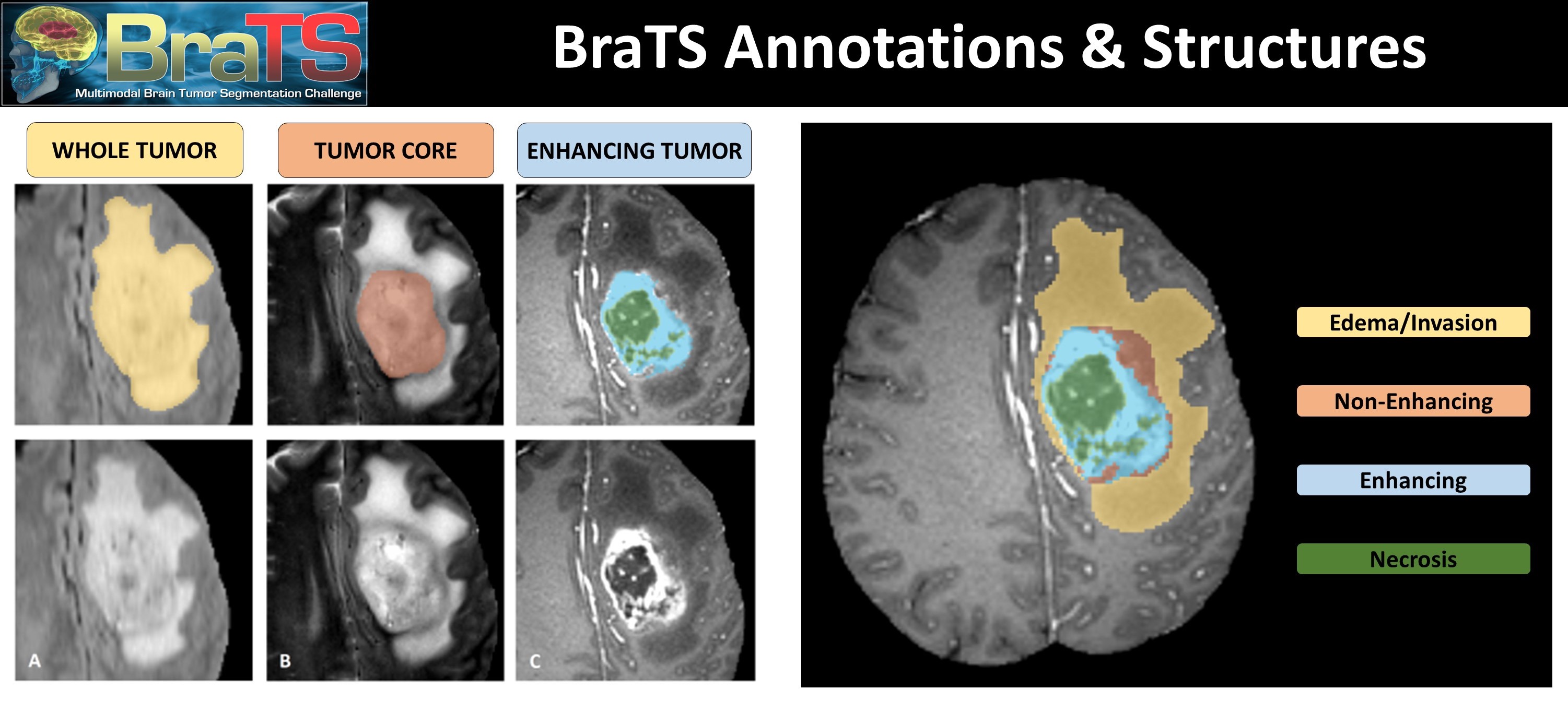
3D MRI BraTS using AutoEncoder
Paper: 3D MRI brain tumor segmentation using autoencoder regularization

BraTS with 3D U-Net

HarDNet-MSEG: 高效且準確之類神經網路應用於大腸息肉分割
Paper: HarDNet-MSEG: A Simple Encoder-Decoder Polyp Segmentation Neural Network that Achieves over 0.9 Mean Dice and 86 FPS
Code: james128333/HarDNet-MSEG



PraNet
Paper: PraNet: Parallel Reverse Attention Network for Polyp Segmentation
 Code: DengPingFan/PraNet
Code: DengPingFan/PraNet

TGANet
Paper: TGANet: Text-guided attention for improved polyp segmentation
 Code: nikhilroxtomar/TGANet
Code: nikhilroxtomar/TGANet

Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
Paper: https://arxiv.org/abs/2304.12620
Code: WuJunde/Medical-SAM-Adapter

SwinMM
SwinMM: Masked Multi-view with Swin Transformers for 3D Medical Image Segmentation
Paper: https://arxiv.org/abs/2307.12591
Code:UCSC-VLAA/SwinMM

Few Shot Medical Image Segmentation with Cross Attention Transformer
Paper: https://arxiv.org/abs/2303.13867


Human Part Segmentation
https://paperswithcode.com/task/human-part-segmentation
Look Into Person Challenge 2020 [LIP]
- LIP is the largest single person human parsing dataset with 50000+ images. This dataset focus more on the complicated real scenarios. LIP has 20 labels, including ‘Background’, ‘Hat’, ‘Hair’, ‘Glove’, ‘Sunglasses’, ‘Upper-clothes’, ‘Dress’, ‘Coat’, ‘Socks’, ‘Pants’, ‘Jumpsuits’, ‘Scarf’, ‘Skirt’, ‘Face’, ‘Left-arm’, ‘Right-arm’, ‘Left-leg’, ‘Right-leg’, ‘Left-shoe’, ‘Right-shoe’.
HumanParsing-Dataset [ATR] (passwd:kjgk)
Paper: Human Parsing with Contextualized Convolutional Neural Network
- ATR is a large single person human parsing dataset with 17000+ images. This dataset focus more on fashion AI. ATR has 18 labels, including ‘Background’, ‘Hat’, ‘Hair’, ‘Sunglasses’, ‘Upper-clothes’, ‘Skirt’, ‘Pants’, ‘Dress’, ‘Belt’, ‘Left-shoe’, ‘Right-shoe’, ‘Face’, ‘Left-leg’, ‘Right-leg’, ‘Left-arm’, ‘Right-arm’, ‘Bag’, ‘Scarf’.
PASCAL-Part Dataset [PASCAL]

- Pascal Person Part is a tiny single person human parsing dataset with 3000+ images. This dataset focus more on body parts segmentation. Pascal Person Part has 7 labels, including ‘Background’, ‘Head’, ‘Torso’, ‘Upper Arms’, ‘Lower Arms’, ‘Upper Legs’, ‘Lower Legs’.
Self Correction Human Parsing
Blog: HumanPartSegmentation : A Machine Learning Model for Segmenting Human Parts
Paper: arxiv.org/abs/1910.09777
Code: PeikeLi/Self-Correction-Human-Parsing
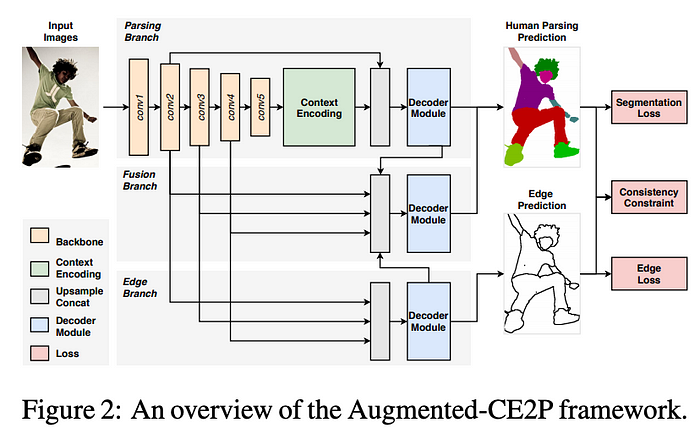

Kagge: https://www.kaggle.com/code/rkuo2000/human-part-segmentation/
 |
 |
Cross-Domain Complementary Learning Using Pose for Multi-Person Part Segmentation
Paper: arxiv.org/abs/1907.05193
Code: kevinlin311tw/CDCL-human-part-segmentation

Instance Segmentation (實例分割)
A Survey on Instance Segmentation
Paper: arxiv.org/abs/2007.00047

Mask-RCNN
Paper: arxiv.org/abs/1703.06870
Blog: 理解Mask R-CNN的工作原理

TensorMask - A Foundation for Dense Object Segmentation
Paper: arxiv.org/abs/1903.12174
Code: TensorMask in Detectron2
PointRend
Paper: PointRend: Image Segmentation as Rendering
Blog: Facebook PointRend: Rendering Image Segmentation
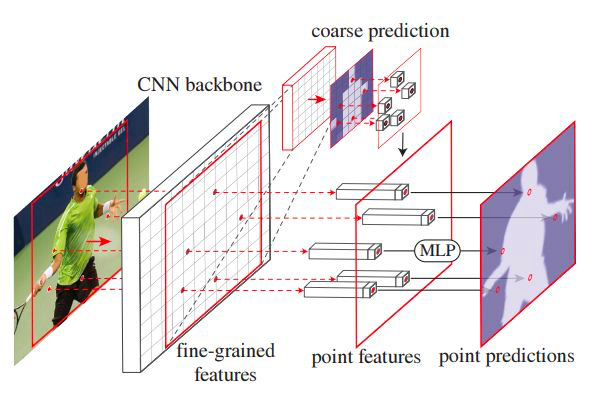
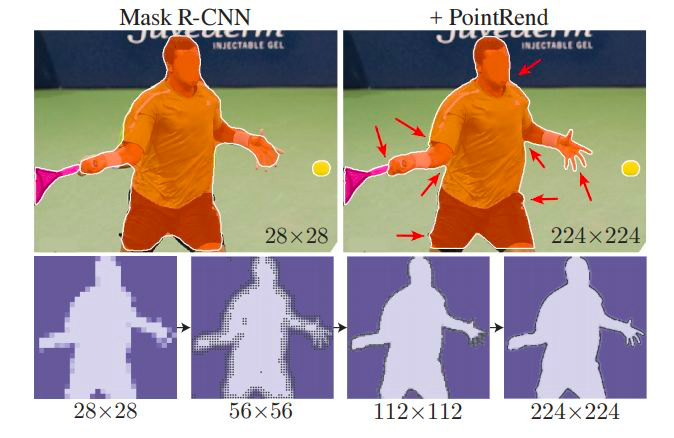
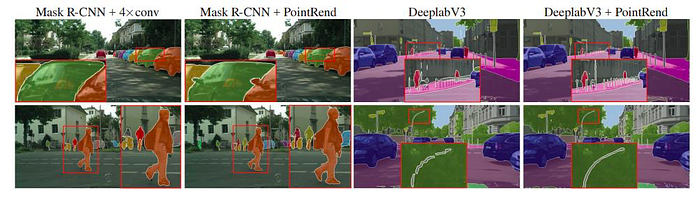 Code: Detectron2 PointRend
Code: Detectron2 PointRend
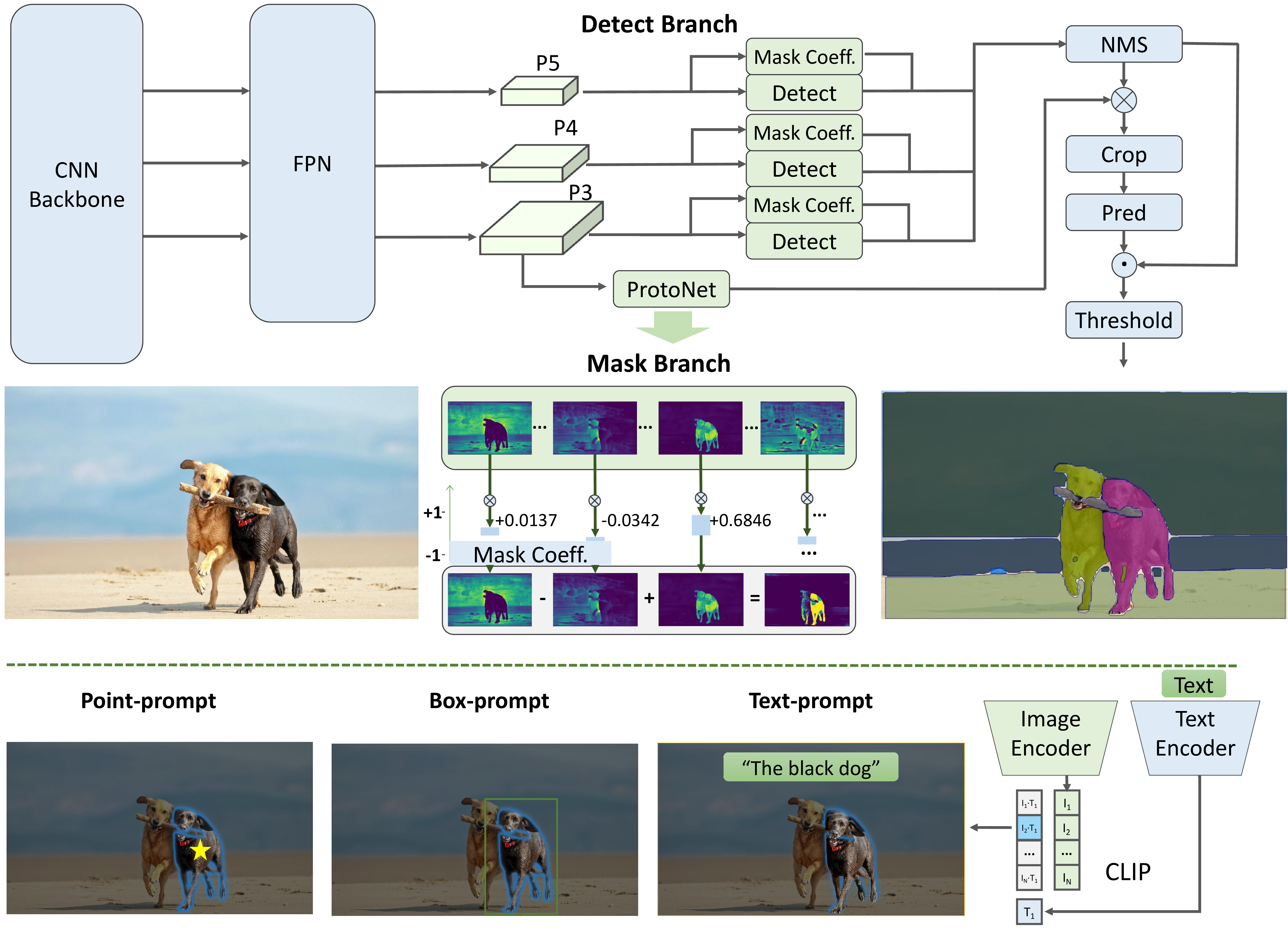
YOLACT - Real-Time Instance Segmentation
Paper: arxiv.org/abs/1904.02689
YOLACT++: Better Real-time Instance Segmentation
Code: https://github.com/dbolya/yolact
https://www.kaggle.com/rkuo2000/yolact
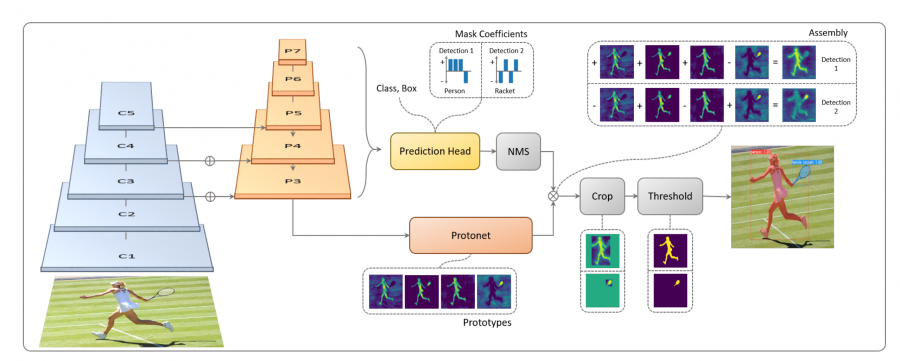
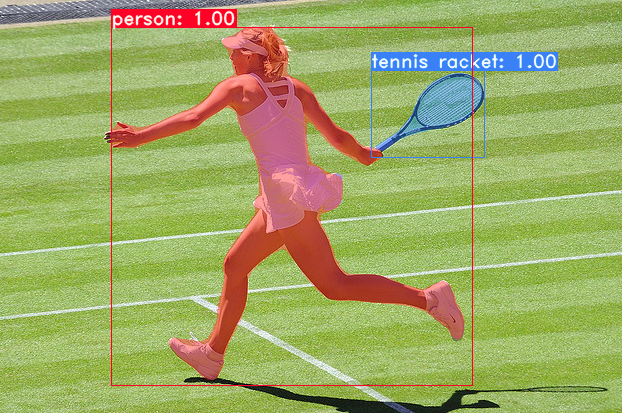

Kaggle: https://www.kaggle.com/code/rkuo2000/yolact

INSTA YOLO
Paper: arxiv.org/abs/2102.06777
YOLOv8 Segment

Blog: Train YOLOv8 Instance Segmentation on Your Data

Blog: How to Train YOLOv8 Instance Segmentation on a Custom Dataset

Kaggle: https://www.kaggle.com/code/rkuo2000/yolov8-segment

3D Classification & Segmentation
ModelNet - 3D CAD models for objects
PointNet
Paper: PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
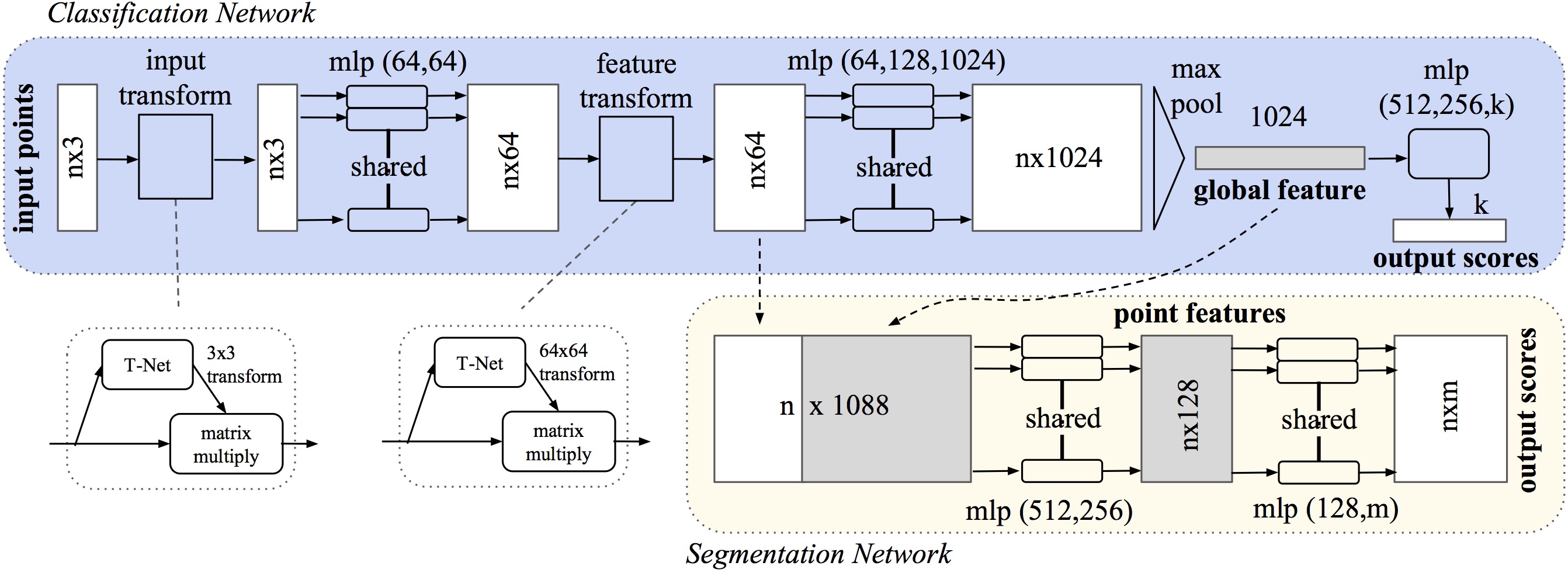 Code: charlesq34/pointnet
Code: charlesq34/pointnet
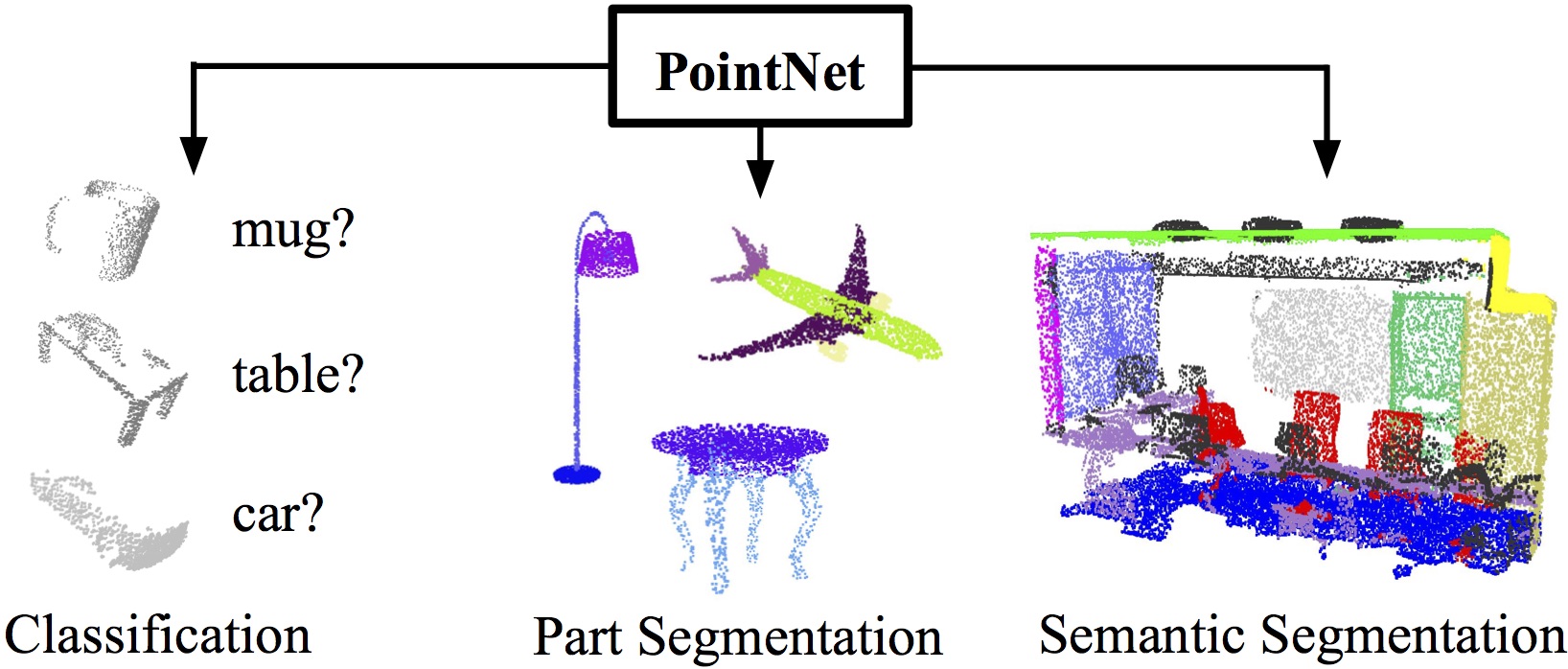
PointNet++
Paper: PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 Code: charlesq34/pointnet2
Code: charlesq34/pointnet2
PCPNet
 Paper: PCPNET: Learning Local Shape Properties from Raw Point Clouds
Paper: PCPNET: Learning Local Shape Properties from Raw Point Clouds

Code: paulguerrero/pcpnet
python eval_pcpnet.py –indir “path/to/dataset” –dataset “dataset.txt” –models “/path/to/model/model_name”
PointCleanNet
Paper: PointCleanNet: Learning to Denoise and Remove Outliers from Dense Point Clouds

 Code: mrakotosaon/pointcleannet
Code: mrakotosaon/pointcleannet
Meta-SeL
Paper: Meta-SeL: 3D-model ShapeNet Core Classification using Meta-Semantic Learning
 Code: faridghm/Meta-SeL
Code: faridghm/Meta-SeL
Dataset: ShapeNetCore
- It covers 55 common object categories with about 51,300 unique 3D models.
- The 12 object categories of PASCAL 3D+

Video Object Datasets (影像物件資料集)
DAVIS - Densely Annotated VIdeo Segmentation

DAVIS 2017
!wget https://data.vision.ee.ethz.ch/csergi/share/davis/DAVIS-2017-trainval-480p.zip
!unzip -q DAVIS-2017-trainval-480p.zip
YTVOS - YouTube Video Object Segmentation

- 4000+ high-resolution YouTube videos
- 90+ semantic categories
- 7800+ unique objects
- 190k+ high-quality manual annotations
- 340+ minutes duration
- train.zip
- train_all_frames.zip
- valid.zip
- valid_all_frames.zip
- test.zip
- test_all_frames.zip
YTVIS - YouTube Video Instance Segmentation
2021 version
3,859 high-resolution YouTube videos, 2,985 training videos, 421 validation videos and 453 test videos.
An improved 40-category label set
8,171 unique video instances
232k high-quality manual annotations
UVO - Unidentified Video Objects
Paper: Unidentified Video Objects: A Benchmark for Dense, Open-World Segmentation
Website: Unidentified Video Objects

Anomaly Video Datasets
Paper: A survey of video datasets for anomaly detection in automated surveillance

Video Object Segmentation (影像物件分割)
FlowNet 2.0
Paper: arxiv.org/abs/1612.01925
Code: NVIDIA/flownet2-pytorch
Optical Flow Based Object Movement Tracking
Paper: Optical Flow Based Object Movement Tracking
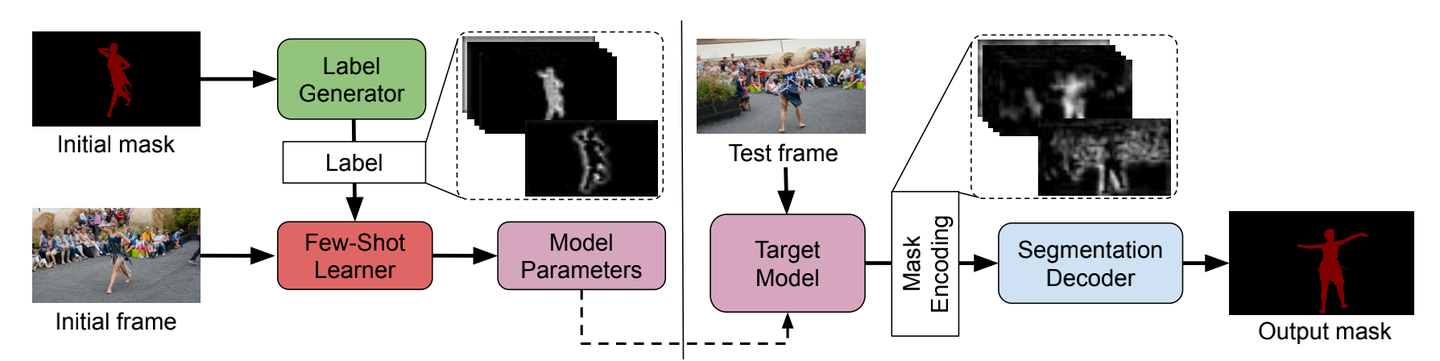
Learning What to Learn for VOS
Paper: arxiv.org/abs/2003.11540
Blog: Learning What to Learn for Video Object Seg
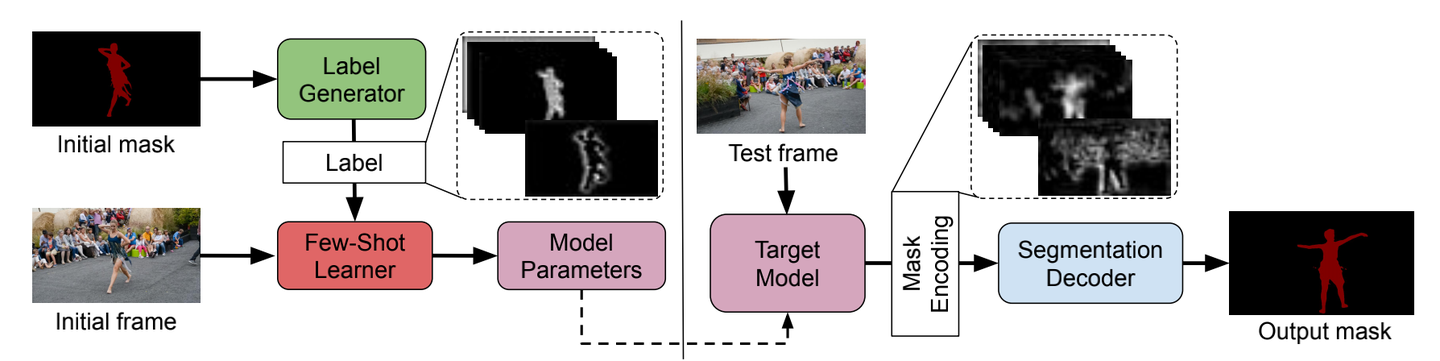
FRTM-VOS
Paper: arxiv.org/abs/2003.00908
Code: andr345/frtm-vos
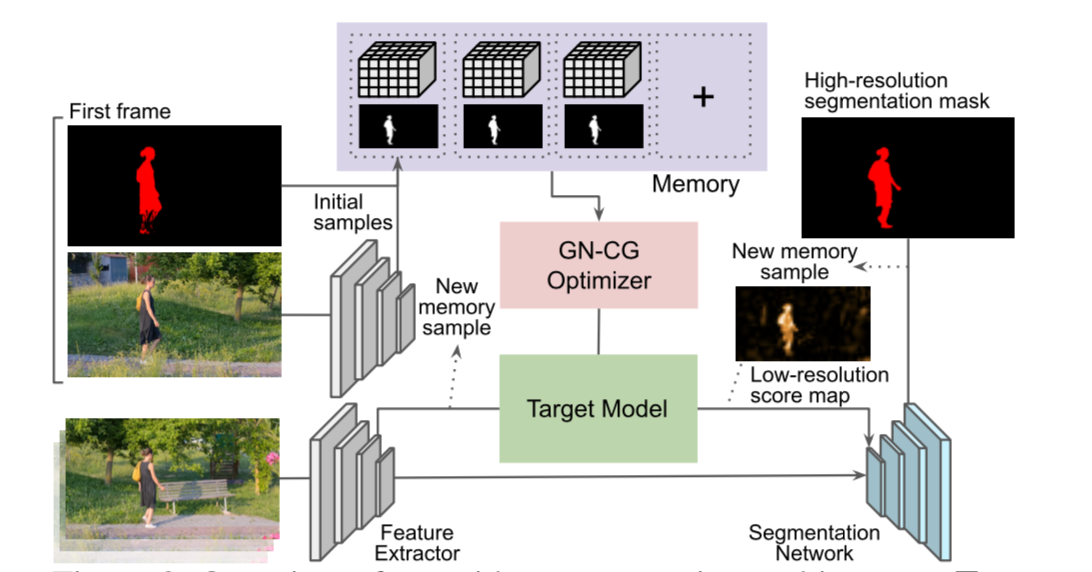
State-Aware Tracker for Real-Time VOS
Paper: arxiv.org/abs/2003.00482
Code: MegviiDetection/video_analyst
 |
 |
Optical Flow
Motion Estimation with Optical Flow
Blog: Introduction to Motion Estimation with Optical Flow

Moving Object Tracking Based on Sparse Optical Flow
Paper: Moving Object Tracking Based on Sparse Optical Flow with Moving Window and Target Estimator
![]() Code: Tracking Motion without Neural Networks: Optical Flow
Code: Tracking Motion without Neural Networks: Optical Flow
LiteFlowNet3
Paper: arxiv.org/abs/2007.09319
Code: twhui/LiteFlowNet3

Cost Volume Modulation (CM)

Flow Field Deformation (FD)

Semantic Segmentation Datasets for Autonomous Driving
自動駕駛用意義分割資料集
CamVid Dataset

KITTI Dataset
CityScapes

Cityscapes Image Pairs
Semantic Segmentation for Improving Automated Driving
Mapillary Vitas Dataset
- 25,000 high-resolution images
- 124 semantic object categories
- 100 instance-specifically annotated categories
- Global reach, covering 6 continents
- Variety of weather, season, time of day, camera, and viewpoint

nuScenes
Optical Flow Based Motion Detection for Autonomous Driving
Paper: Optical Flow Based Motion Detection for Autonomous Driving
Dataset: nuScenes
nuScenes devkit
Code: kamanphoebe/MotionDetection
- Optical flow algorithms: FastFlowNet, Raft
- Model: ResNet18**
Panoptic Segmentation (全景分割)
Blog: 全景分割(Panoptic Segmentation)

nuScenes panoptic challenge

YOLOP
Paper: arxiv.org/abs/2108.11250
Code: hustvl/YOLOP

Kaggle: https://www.kaggle.com/code/rkuo2000/yolop

VPSNet for Video Panoptic Segmentation
Paper: arxiv.org/abs/2006.11339
Code: mcahny/vps

Panoptic-PolarNet: Proposal-free LiDAR Point Cloud Panoptic Segmentation
Paper: https://arxiv.org/abs/2103.14962
Code: edwardzhou130/Panoptic-PolarNet

Panoptic-PHNet: Towards Real-Time and High-Precision LiDAR Panoptic Segmentation via Clustering Pseudo Heatmap
Paper: https://arxiv.org/abs/2205.07002

LidarMultiNet
Paper: LidarMultiNet: Towards a Unified Multi-Task Network for LiDAR Perception


This site was last updated September 17, 2025.