Object Detection
Introduction to Image Datasets, Object Detection, Object Tracking, and its Applications.
Datasets
COCO Dataset

- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
- 330K images (>200K labeled)
- 1.5 million object instances
- 80 object categories
- 91 stuff categories
- 5 captions per image
- 250,000 people with keypoints
Open Images Dataset
- 15,851,536 boxes on 600 categories
- 2,785,498 instance segmentations on 350 categories
- 3,284,280 relationship annotations on 1,466 relationships
- 66,391,027 point-level annotations on 5,827 classes
- 61,404,966 image-level labels on 20,638 classes
- Extension - 478,000 crowdsourced images with 6,000+ categories
Roboflow
labelme

pip install labelme
labelme pic123.jpg
Labelme2YOLO
pip install labelme2yolo
- Convert JSON files, split training and validation dataset by –val_size
python labelme2yolo.py --json_dir /home/username/labelme_json_dir/ --val_size 0.2
LabelImg
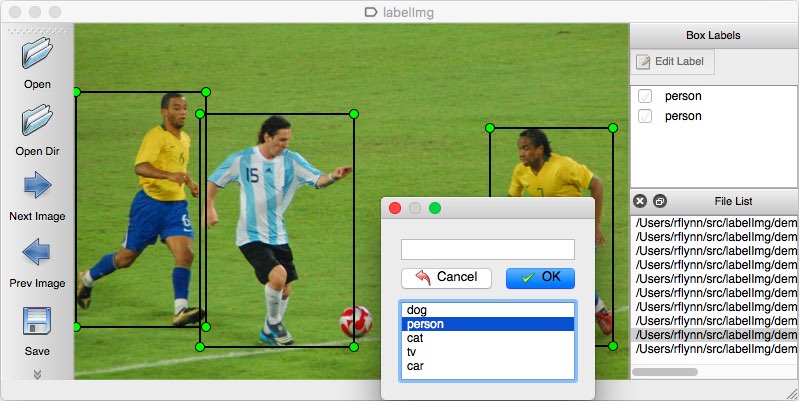
pip install labelImg
labelImg
labelImg [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
VOC .xml convert to YOLO .txt
cd ~/tf/raccoon/annotations
python ~/tf/xml2yolo.py
YOLO Annotation formats (.txt)
class_num x, y, w, h
0 0.5222826086956521 0.5518115942028986 0.025 0.010869565217391304
0 0.5271739130434783 0.5057971014492754 0.013043478260869565 0.004347826086956522
Object Detection
Object Detection Landscape
Blog: The Object Detection Landscape: Accuracy vs Runtime
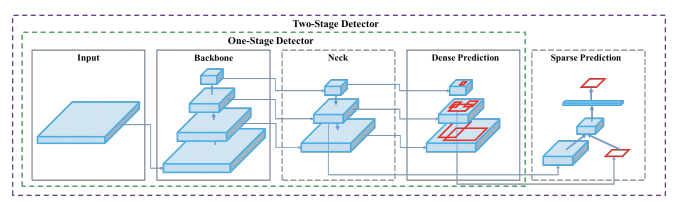
R-CNN, Fast R-CNN, Faster R-CNN
Blog: 目標檢測

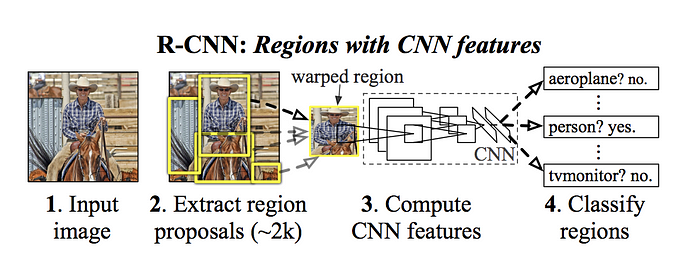
- R-CNN首先使用Selective search提取region proposals(候選框);然後用Deep Net(Conv layers)進行特徵提取;最後對候選框類別分別採用SVM進行類別分類,採用迴歸對bounding box進行調整。其中每一步都是獨立的。
- Fast R-CNN在R-CNN的基礎上,提出了多任務損失(Multi-task Loss), 將分類和bounding box迴歸作爲一個整體任務進行學習;另外,通過ROI Projection可以將Selective Search提取出的ROI區域(即:候選框Region Proposals)映射到原始圖像對應的Feature Map上,減少了計算量和存儲量,極大的提高了訓練速度和測試速度。
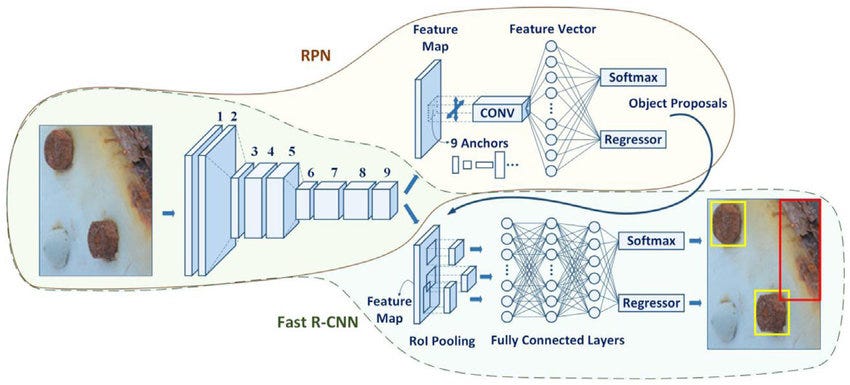
- Faster R-CNN則是在Fast R-CNN的基礎上,提出了RPN網絡用來生成Region Proposals。通過網絡共享將提取候選框與目標檢測結合成一個整體進行訓練,替換了Fast R-CNN中使用Selective Search進行提取候選框的方法,提高了測試過程的速度。
R-CNN
Paper: arxiv.org/abs/1311.2524

Fast R-CNN
Paper: arxiv.org/abs/1504.08083
Github: faster-rcnn

Faster R-CNN
Paper: arxiv.org/abs/1506.01497
Github: faster_rcnn, py-faster-rcnn
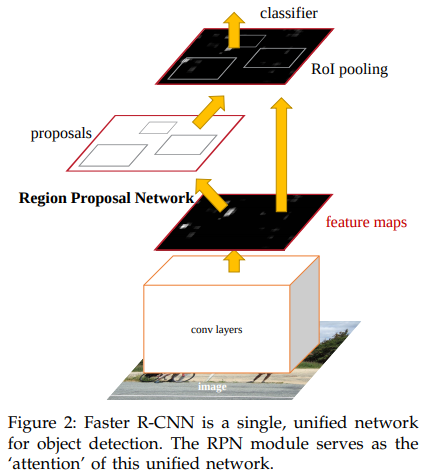
Blog: [物件偵測] S3: Faster R-CNN 簡介
- RPN是一個要提出proposals的小model,而這個小model需要我們先訂出不同尺度、比例的proposal的邊界匡的雛形。而這些雛形就叫做anchor。
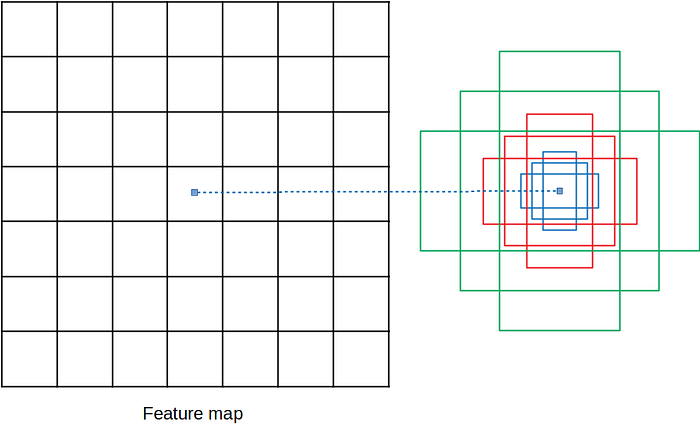
- RPN的上路是負責判斷anchor之中有無包含物體的機率,因此,1×1的卷積深度就是9種anchor,乘上有無2種情況,得18。而下路則是負責判斷anchor的x, y, w, h與ground truth的偏差量(offsets),因此9種anchor,乘上4個偏差量(dx, dy, dw, dh),得卷積深度為36。
Mask R-CNN
Paper: arxiv.org/abs/1703.06870

<img width="50%" height="50%" src="https://miro.medium.com/max/2000/0*-tQsWmjcPhVfwRZ4"
Blog: [物件偵測] S9: Mask R-CNN 簡介
Code: matterport/Mask_RCNN


)
SSD: Single Shot MultiBox Detector
Paper: arxiv.org/abs/1512.02325
Blog: Understanding SSD MultiBox — Real-Time Object Detection In Deep Learning
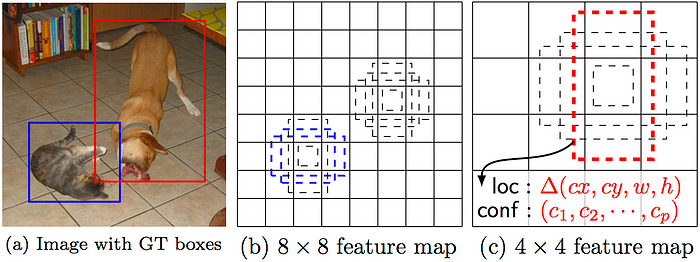 使用神經網絡(VGG-16)提取feature map後進行分類和回歸來檢測目標物體。
使用神經網絡(VGG-16)提取feature map後進行分類和回歸來檢測目標物體。
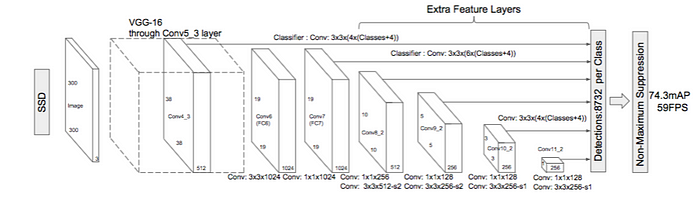
 Code: pierluigiferrari/ssd_keras
Code: pierluigiferrari/ssd_keras
 |
 |
 |
 |
RetinaNet
Paper: Focal Loss for Dense Object Detection
Code: keras-retinanet
Blog: RetinaNet 介紹
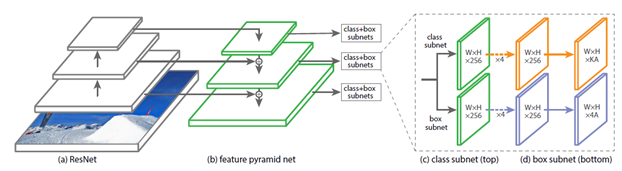 從左到右分別用上了
從左到右分別用上了
- 殘差網路(Residual Network ResNet)
- 特徵金字塔(Feature Pyramid Network FPN)
- 類別子網路(Class Subnet)
- 框子網路(Box Subnet)
- 以及Anchors
CornerNet
Paper: CornerNet: Detecting Objects as Paired Keypoints
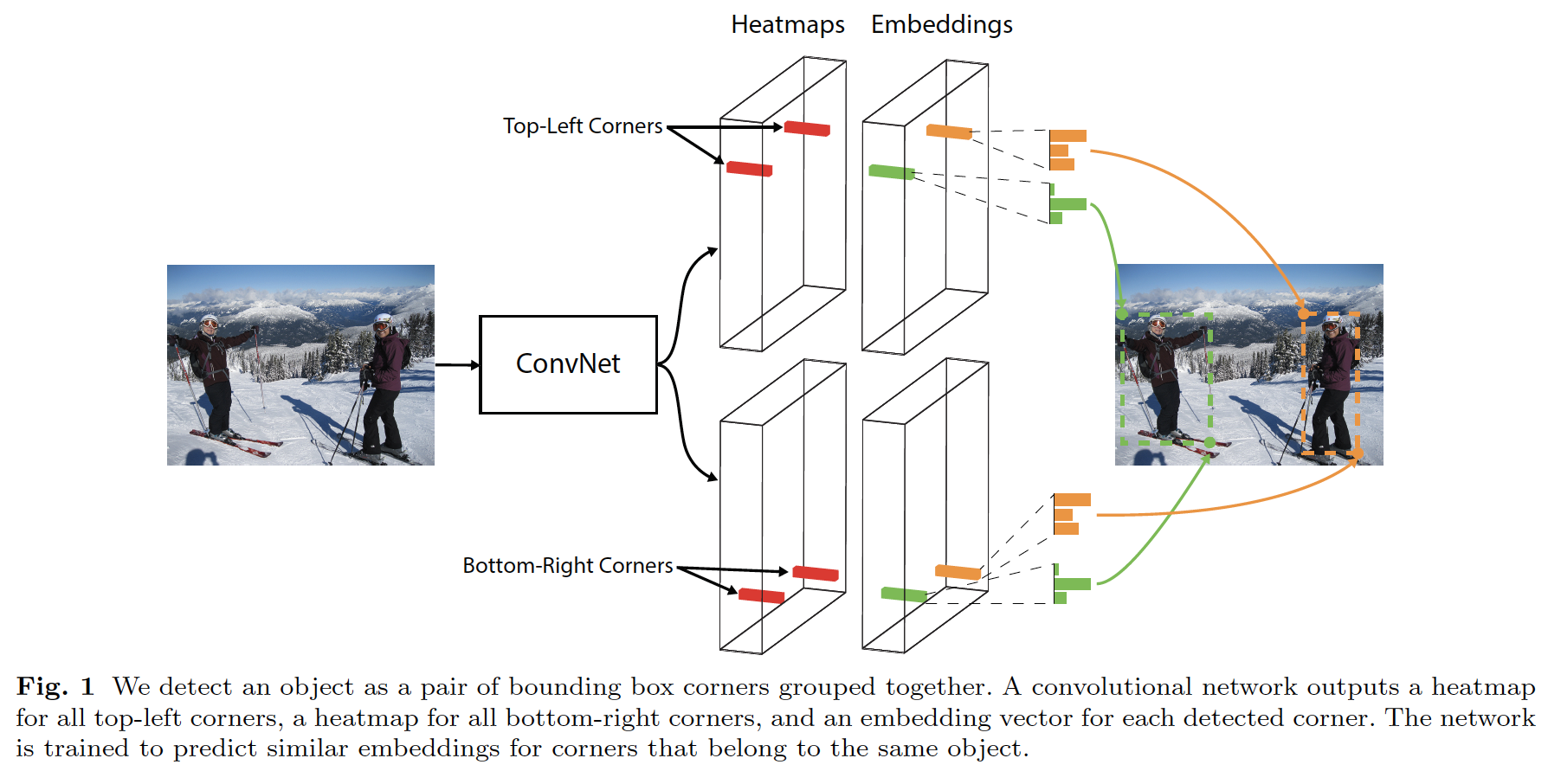 Code: princeton-vl/CornerNet
Code: princeton-vl/CornerNet
CenterNet
Paper: CenterNet: Keypoint Triplets for Object Detection
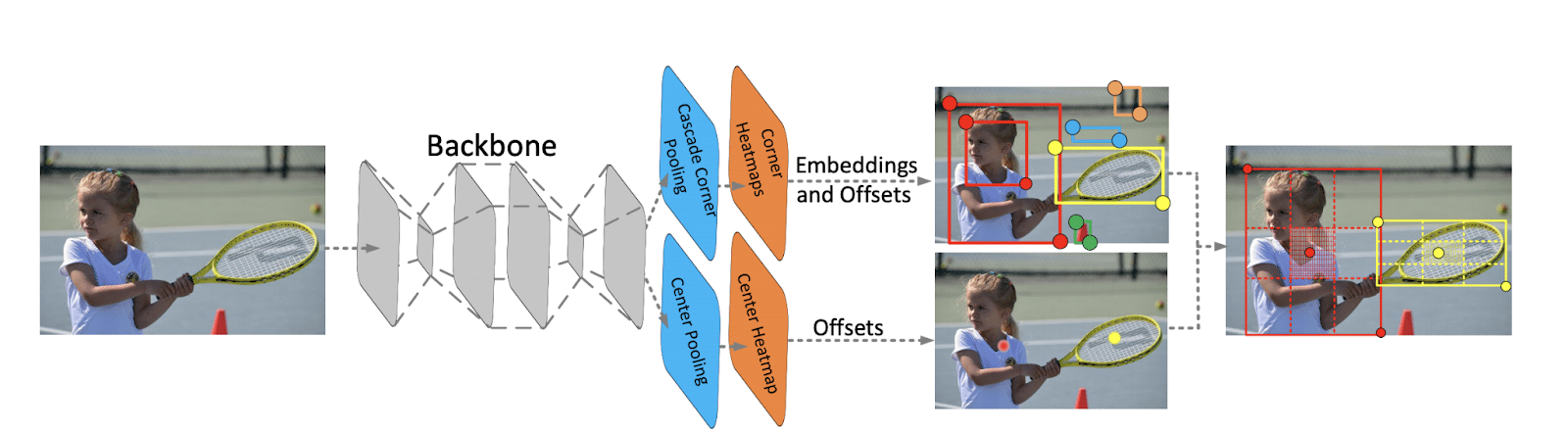 Code: xingyizhou/CenterNet
Code: xingyizhou/CenterNet
EfficientDet
Paper: arxiv.org/abs/1911.09070
 Code: google efficientdet
Code: google efficientdet

 |
 |
Kaggle: rkuo2000/efficientdet-gwd
YOLO- You Only Look Once
Code: pjreddie/darknet
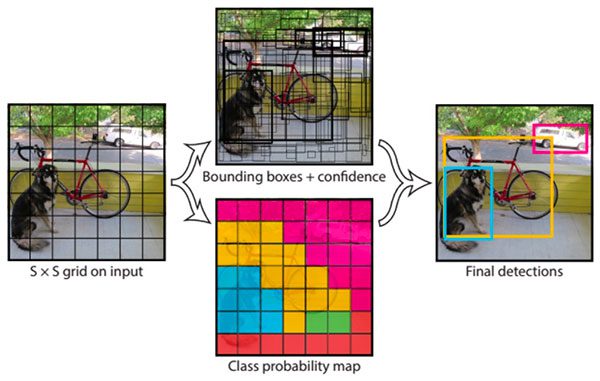
YOLOv1 : mapping bounding box
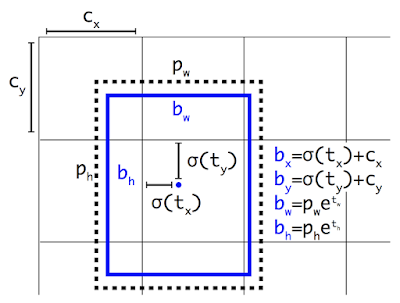
YOLOv2 : anchor box proportional to K-means
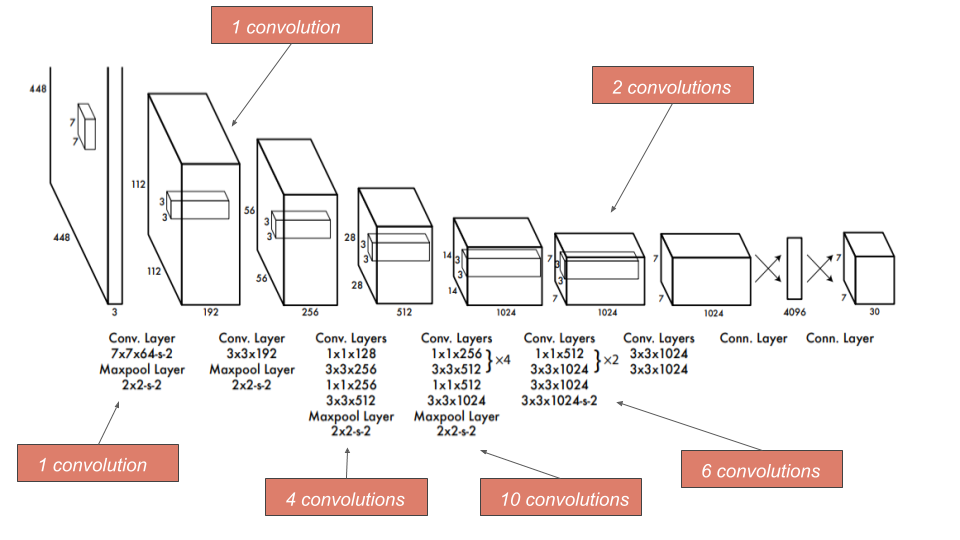
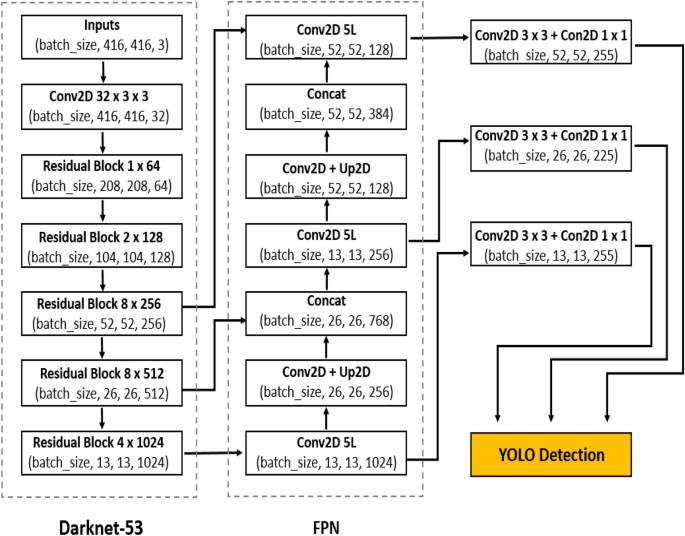
YOLOv3 : Darknet-53 + FPN
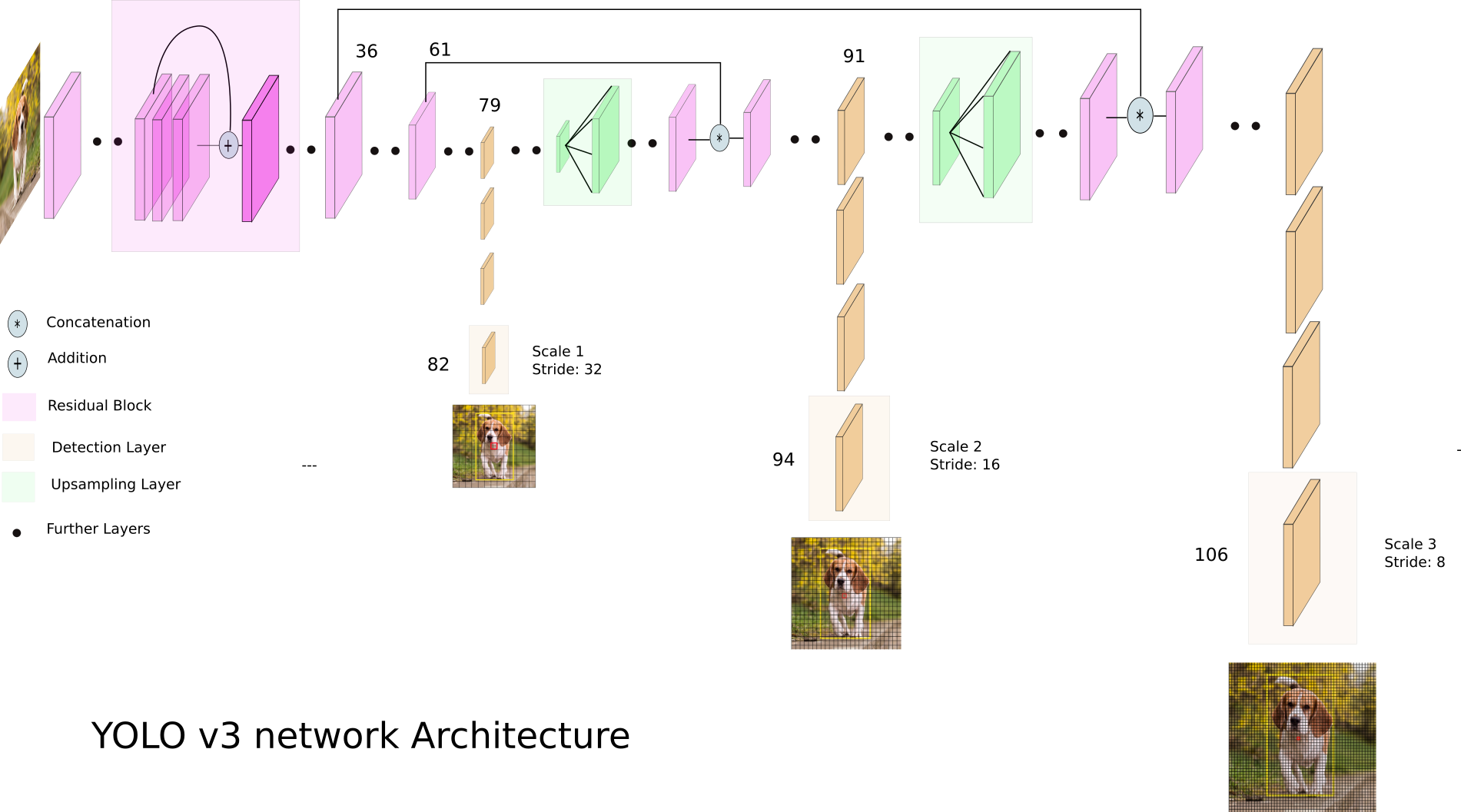
YOLObile
Paper: arxiv.org/abs/2009.05697
Code: nightsnack/YOLObile

YOLOv4
Paper: YOLOv4: Optimal Speed and Accuracy of Object Detection
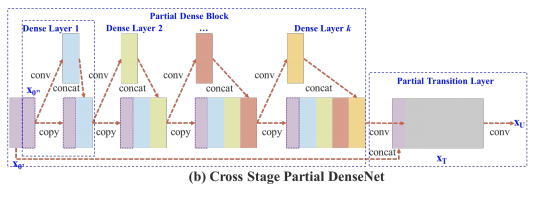
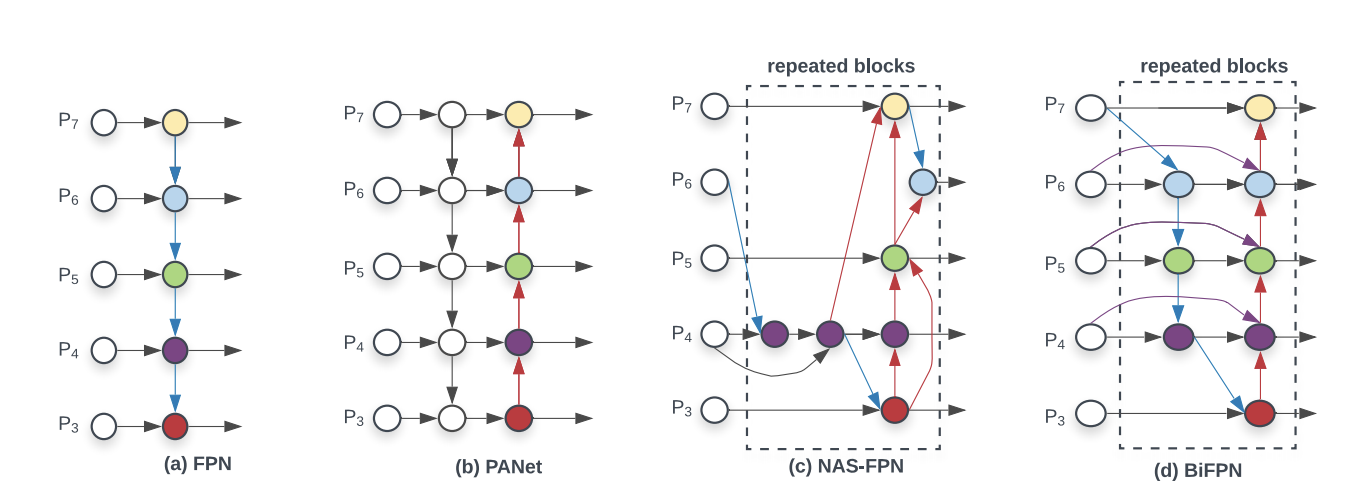
- YOLOv4 = YOLOv3 + CSPDarknet53 + SPP + PAN + BoF + BoS
- CSP
- PANet
Code: AlexeyAB/darknet
Code: WongKinYiu/PyTorch_YOLOv4
YOLOv5

Code: ultralytics/yolov5/
< img src="https://user-images.githubusercontent.com/26833433/127574988-6a558aa1-d268-44b9-bf6b-62d4c605cc72.jpg">
< img src="https://user-images.githubusercontent.com/26833433/136901921-abcfcd9d-f978-4942-9b97-0e3f202907df.png">
Scaled-YOLOv4
Paper: arxiv.org/abs/2011.08036
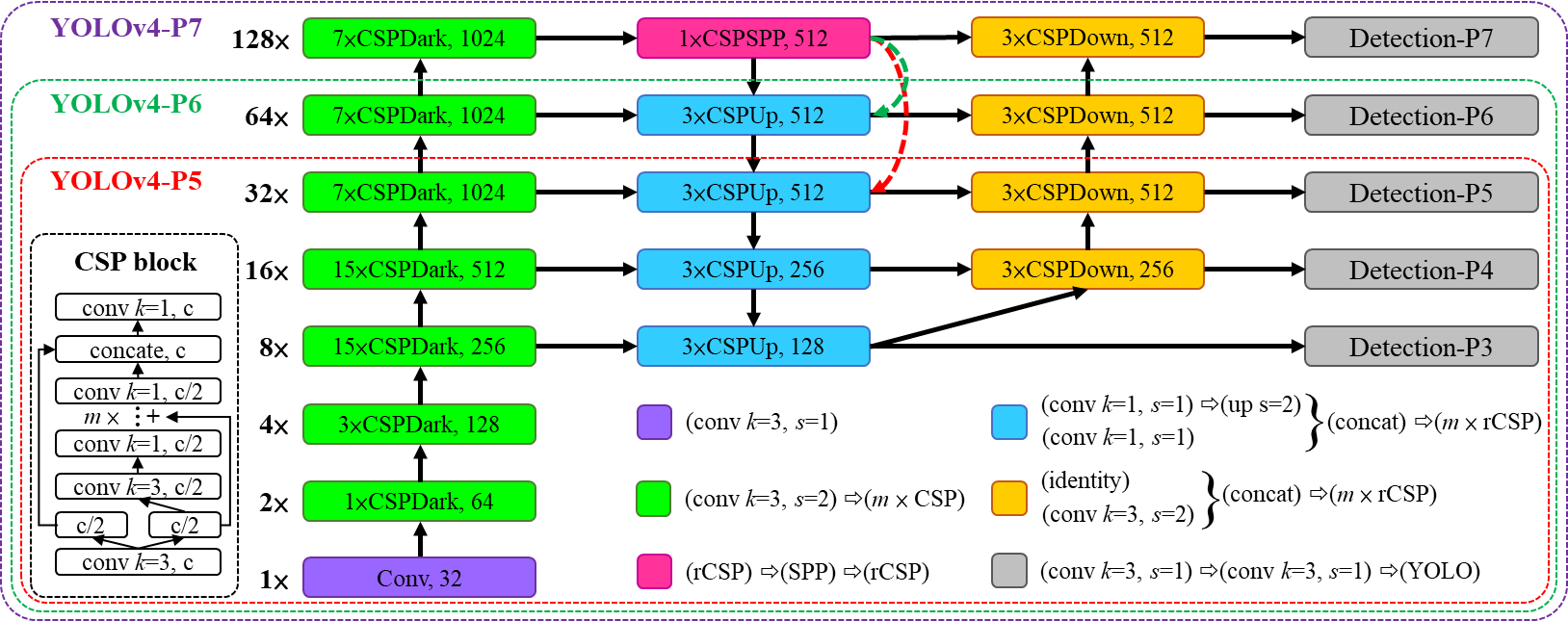 Code: WongKinYiu/ScaledYOLOv4
Code: WongKinYiu/ScaledYOLOv4
YOLOR : You Only Learn One Representation
Paper: arxiv.org/abs/2105.04206
 Code: WongKinYiu/yolor
Code: WongKinYiu/yolor


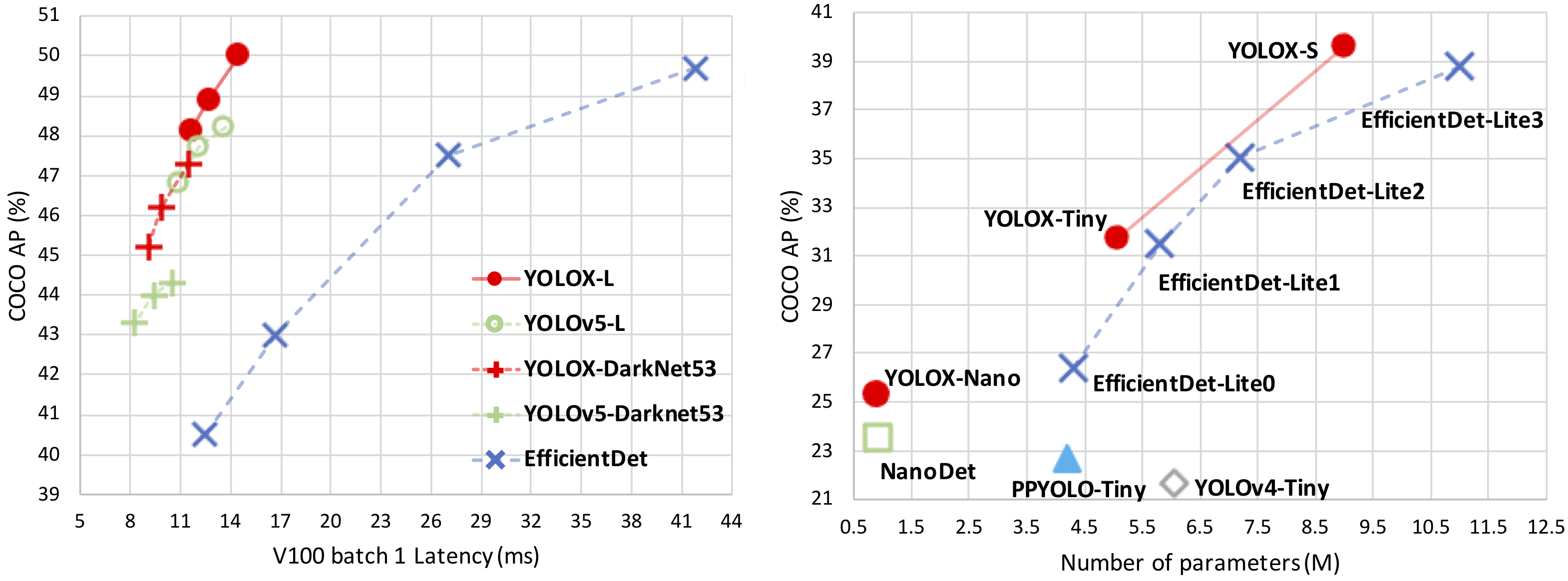
YOLOX
Paper: arxiv.org/abs/2107.08430
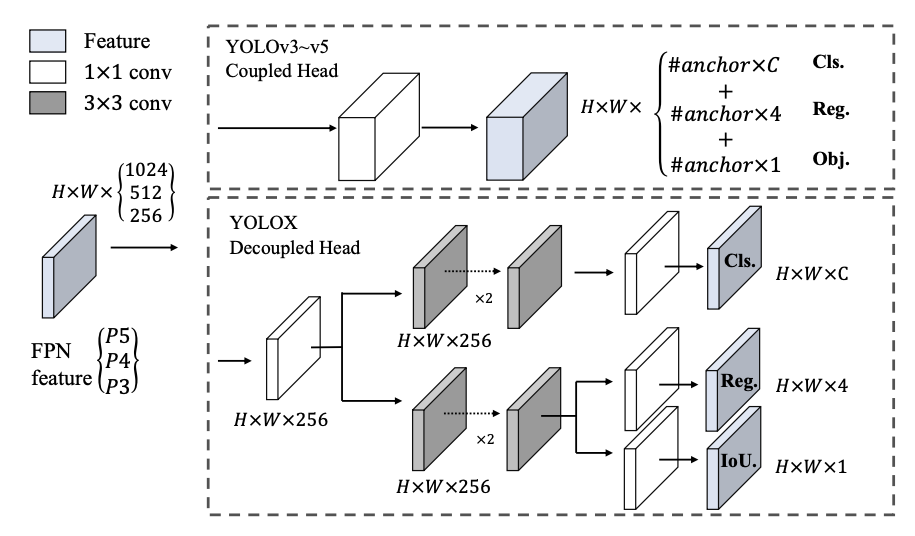 Code: Megvii-BaseDetection/YOLOX
Code: Megvii-BaseDetection/YOLOX

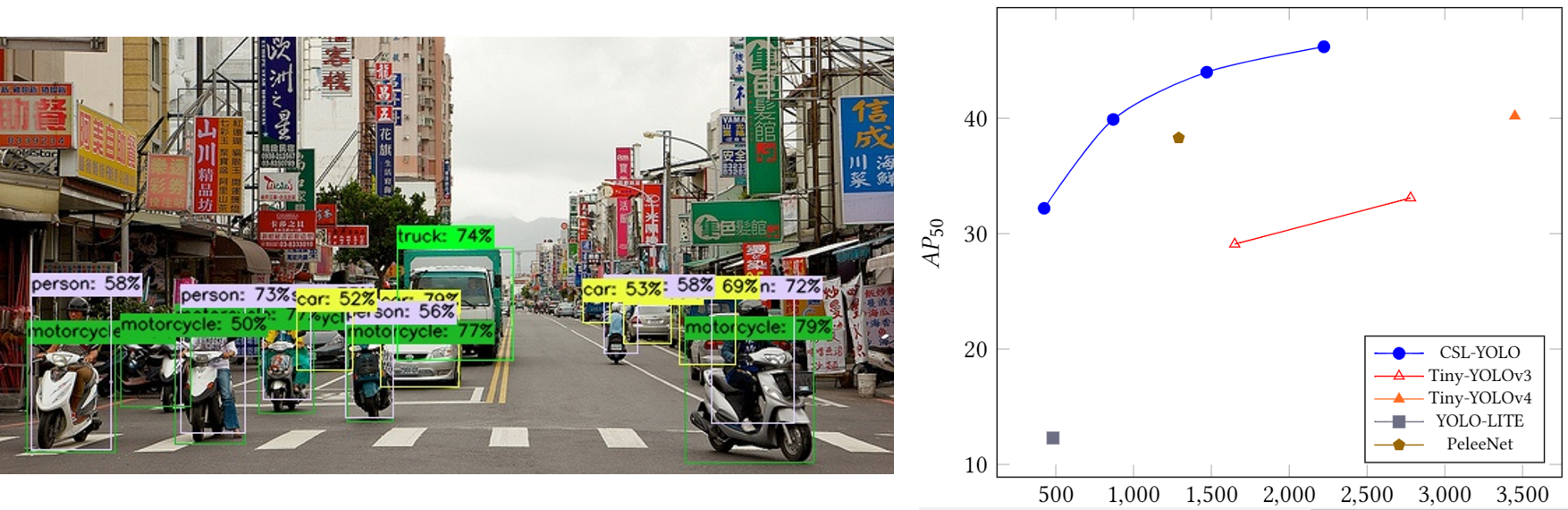
CSL-YOLO
Paper: arxiv.org/abs/2107.04829
Code: D0352276/CSL-YOLO
PP-YOLOE
Paper: PP-YOLOE: An evolved version of YOLO
 Code: PaddleDetection
Code: PaddleDetection
 Kaggle: rkuo2000/pp-yoloe
Kaggle: rkuo2000/pp-yoloe

YOLOv6
Blog: YOLOv6:又快又准的目标检测框架开源啦
Code: meituan/YOLOv6


YOLOv7
Paper: YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
- Extended efficient layer aggregation networks

- Model scaling for concatenation-based models

- Planned re-parameterized convolution

- Coarse for auxiliary and fine for lead head label assigner

Code: WongKinYiu/yolov7

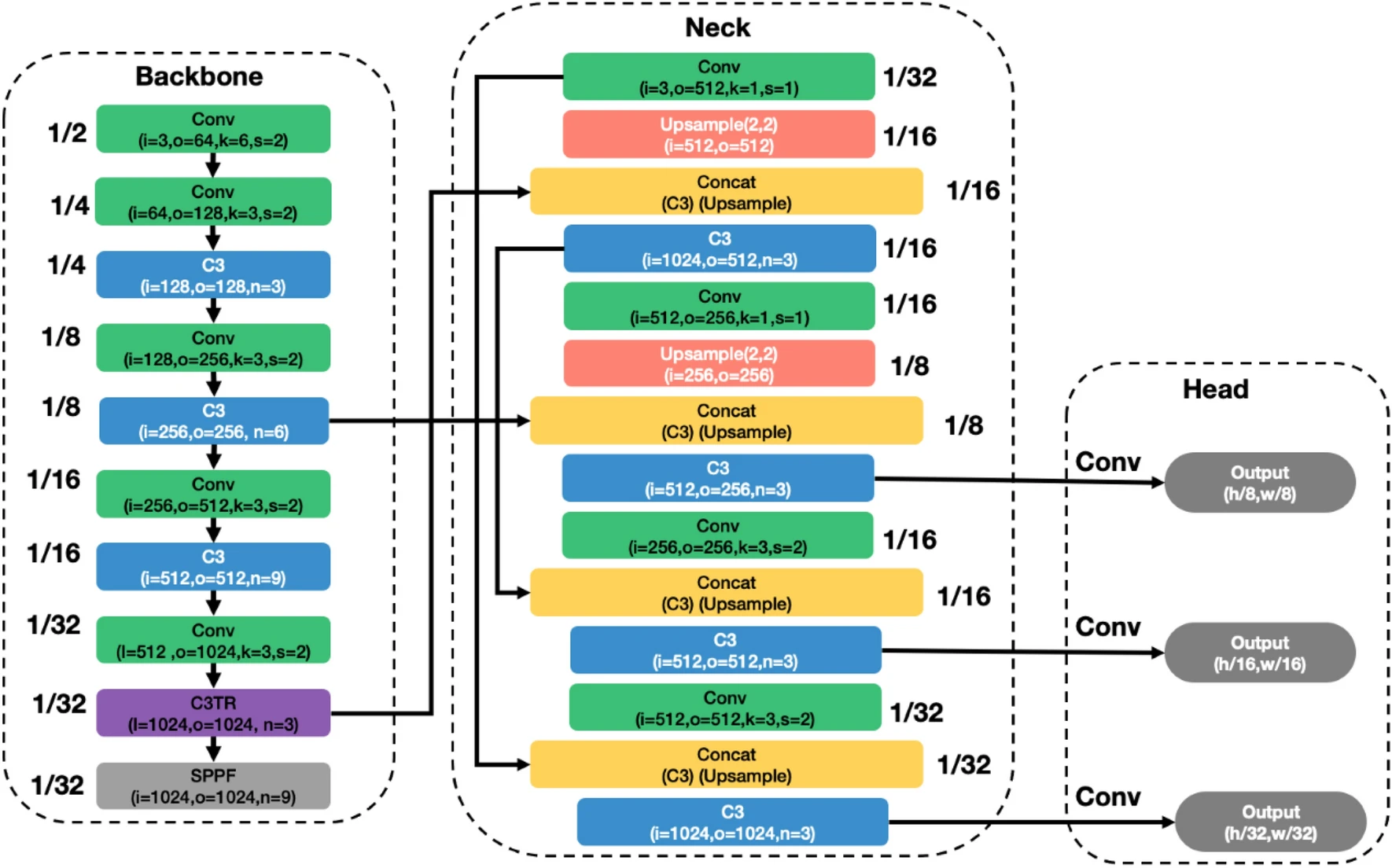
YOLOv8
Ultralytics YOLOv8 is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility. YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection and tracking, instance segmentation, image classification and pose estimation tasks.
Blog: Dive into YOLOv8
Paper: Real-Time Flying Object Detection with YOLOv8

Code: https://github.com/ultralytics/ultralytics
Kaggle:
- https://www.kaggle.com/code/rkuo2000/yolov8
- https://www.kaggle.com/code/rkuo2000/yolov8-pothole-detection
UAV-YOLOv8
YOLOv8 Aerial Sheep Detection and Counting
Code: https://github.com/monemati/YOLOv8-Sheep-Detection-Counting

YOLOv8 Drone Surveillance
Code: https://github.com/ni9/Object-Detection-From-Drone-For-Surveillance

YOLOv9
Paper: YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Blog: YOLOv9: Advancing the YOLO Legacy
 Programmable Gradient Information (PGI)
Programmable Gradient Information (PGI)
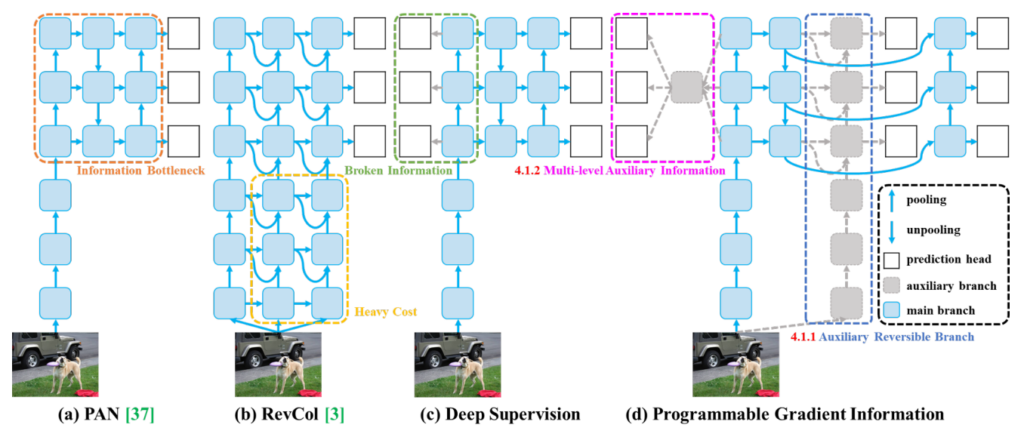 GELAN architecture
GELAN architecture
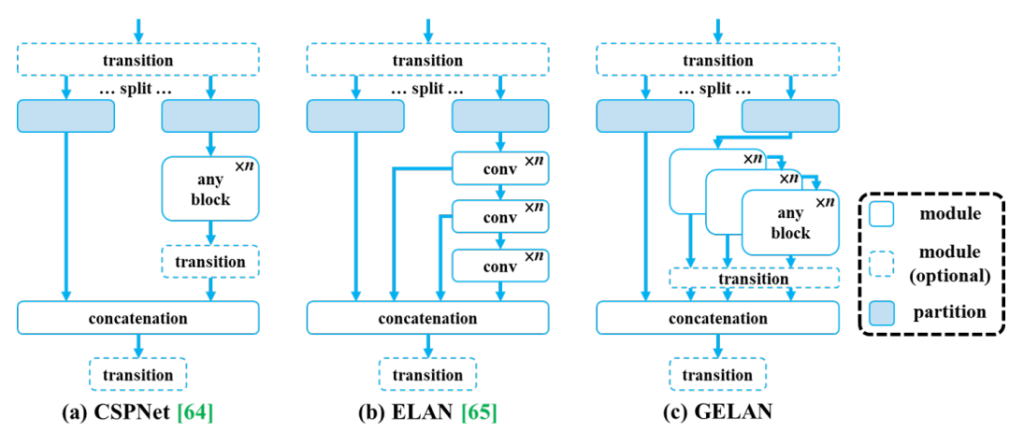
Code: https://github.com/WongKinYiu/yolov9

YOLOv10
Paper: YOLOv10: Real-Time End-to-End Object Detection
Code: https://github.com/THU-MIG/yolov10
YOLOv1 ~ YOLOv10
Paper: YOLOv1 to YOLOv10: The fastest and most accurate real-time object detection systems
YOLOv11
Github: https://github.com/ultralytics/ultralytics

YOLOv12
Paper: YOLOv12: Attention-Centric Real-Time Object Detectors
Code: https://github.com/sunsmarterjie/yolov12

Trash Detection
Localize and Classify Wastes on the Streets
Paper: arxiv.org/abs/1710.11374
Model: GoogLeNet

Street Litter Detection
Code: isaychris/litter-detection-tensorflow
TACO: Trash Annotations in Context
Paper: arxiv.org/abs/2003.06875
Code: pedropro/TACO
Model: Mask R-CNN

Marine Litter Detection
Paper: arxiv.org/abs/1804.01079
Dataset: Deep-sea Debris Database

Marine Debris Detection
Ref. Detect Marine Debris from Aerial Imagery
Code: yhoztak/object_detection
Model: RetinaNet


UDD dataset
Paper: A New Dataset, Poisson GAN and AquaNet for Underwater Object Grabbing
Dataset: UDD_Official
Concretely, UDD consists of 3 categories (seacucumber, seaurchin, and scallop) with 2,227 images



Detecting Underwater Objects (DUO)
Paper: A Dataset And Benchmark Of Underwater Object Detection For Robot Picking
Dataset: DUO

Other Applications
T-CNN : Tubelets with CNN
Paper: arxiv.org/abs/1604.02532
Blog: 人工智慧在太空的應用
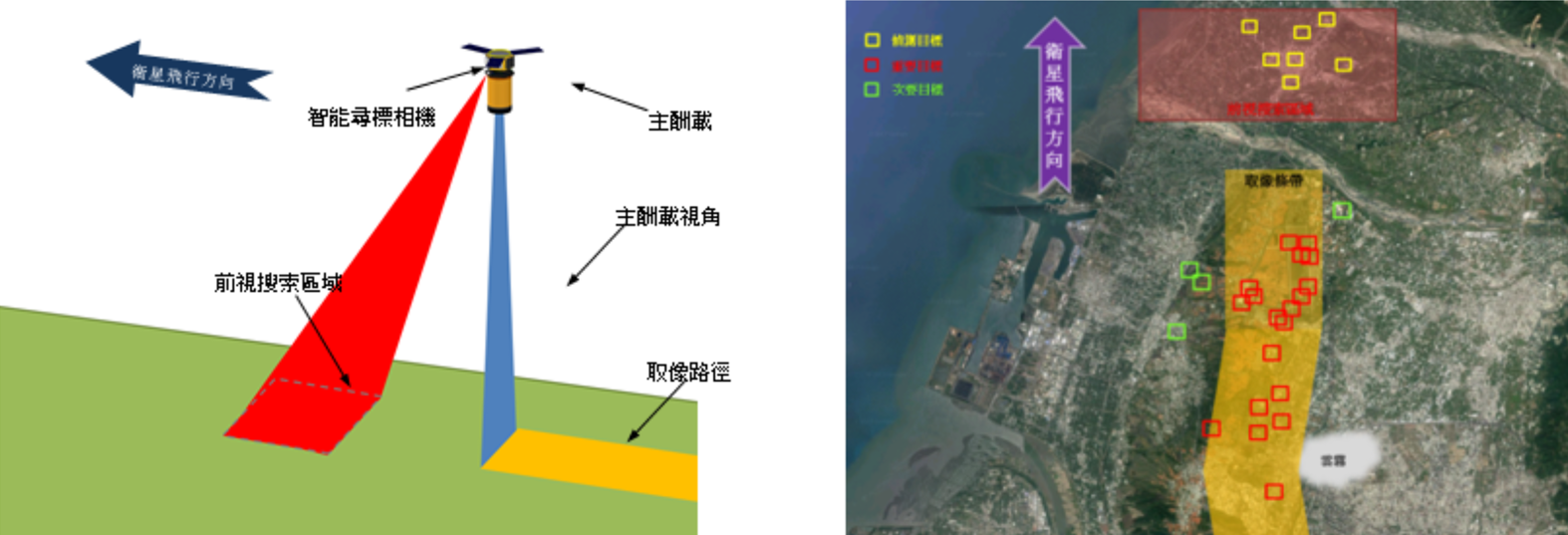

Swimming Pool Detection
Dataset: Aerial images of swimming pools
Kaggle: Evaluation Efficientdet - Swimming Pool Detection

Identify Military Vehicles in Satellite Imagery
Blog: Identify Military Vehicles in Satellite Imagery with TensorFlow
Dataset: Moving and Stationary Target Acquisition and Recognition (MSTAR) Dataset
 Code: Target Recognition in Sythentic Aperture Radar Imagery Using Deep Learning
Code: Target Recognition in Sythentic Aperture Radar Imagery Using Deep Learning
script.ipynb
YOLOv5 Detect
detect image / video
YOLOv5 Elephant
train YOLOv5 for detecting elephant (dataset from OpenImage V6)
 |
 |
BCCD Dataset
3 classes: RBC (Red Blood Cell), WBC (White Blood Cell), Platelets (血小板)
Kaggle: https://www.kaggle.com/datasets/surajiiitm/bccd-dataset

Face Mask Dataset
Kaggle: https://kaggle.com/rkuo2000/yolov5-facemask

Traffic Analysis
Kaggle: https://kaggle.com/rkuo2000/yolov5-traffic-analysis

Global Wheat Detection
Kaggle: https://www.kaggle.com/rkuo2000/yolov5-global-wheat-detection

Mask R-CNN
Kaggle: rkuo2000/mask-rcnn

Mask R-CNN transfer learning
Kaggle: Mask RCNN transfer learning
![]()
Objectron
Kaggle: rkuo2000/mediapipe-objectron

OpenCV-Python play GTA5
Ref. Reading game frames in Python with OpenCV - Python Plays GTA V
Code: Sentdex/pygta5
Steel Defect Detection
Dataset: Severstal: Steel Defect Detection
 Kaggle: https://www.kaggle.com/code/jaysmit/u-net (Keras UNet)
Kaggle: https://www.kaggle.com/code/jaysmit/u-net (Keras UNet)
PCB Defect Detection
Dataset: HRIPCB dataset (dropbox)

Pothole Detection
Blog: Pothole Detection using YOLOv4
Code: yolov4_pothole_detection.ipynb
Kaggle: YOLOv7 Pothole Detection

Car Breaking Detection
Code: YOLOv7 Braking Detection

Steel Defect Detection
Dataset: Severstal: Steel Defect Detection
Steel Defect Detection using UNet
Kaggle: https://www.kaggle.com/code/jaysmit/u-net (Keras UNet)
Kaggle: https://www.kaggle.com/code/myominhtet/steel-defection (pytorch UNet
Steel-Defect Detection Using CNN
Code: https://github.com/himasha0421/Steel-Defect-Detection


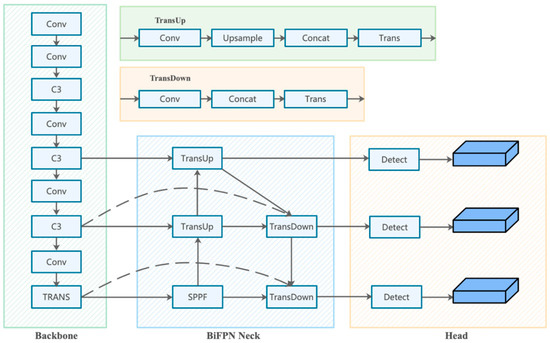
MSFT-YOLO
Paper: MSFT-YOLO: Improved YOLOv5 Based on Transformer for Detecting Defects of Steel Surface

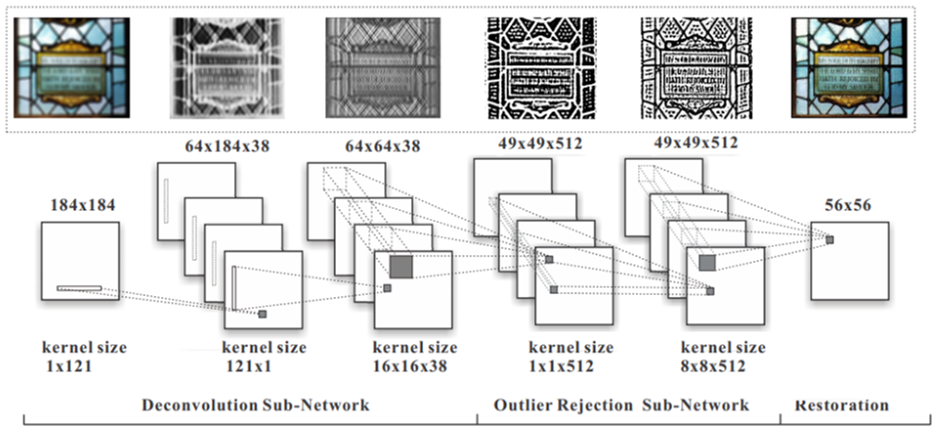
PCB Datasets


PCB Defect Detection
Paper: PCB Defect Detection Using Denoising Convolutional Autoencoders
PCB Defect Classification
Dataset: HRIPCB dataset (dropbox)
印刷电路板(PCB)瑕疵数据集。它是一个公共合成PCB数据集,包含1386张图像,具有6种缺陷(漏孔、鼠咬、开路、短路、杂散、杂铜),用于图像检测、分类和配准任务。
Paper: End-to-end deep learning framework for printed circuit board manufacturing defect classification
Object Tracking Datasets
Paper: Deep Learning in Video Multi-Object Tracking: A Survey
Multiple Object Tracking (MOT)

Under-water Ojbect Tracking (UOT)
Paper: Underwater Object Tracking Benchmark and Dataset
UOT32
UOT100

Re3 : Real-Time Recurrent Regression Networks for Visual Tracking of Generic Objects
Paper: arxiv.org/abs/1705.06368
Code: moorejee/Re3

Deep SORT
Paper: Simple Online and Realtime Tracking with a Deep Association Metric
Code: https://github.com/nwojke/deep_sort
SiamCAR
Paper: arxiv.org/abs/1911.07241
Code: ohhhyeahhh/SiamCAR


YOLOv5 + DeepSort
Code: HowieMa/DeepSORT_YOLOv5_Pytorch

Yolov5 + StrongSORT with OSNet
Code: https://github.com/mikel-brostrom/Yolov5_StrongSORT_OSNet
 |
 |
BoxMOT

SiamBAN
Paper: arxiv.org/abs/2003.06761
Code: hqucv/siamban
Blog: [CVPR2020][SiamBAN] Siamese Box Adaptive Network for Visual Tracking



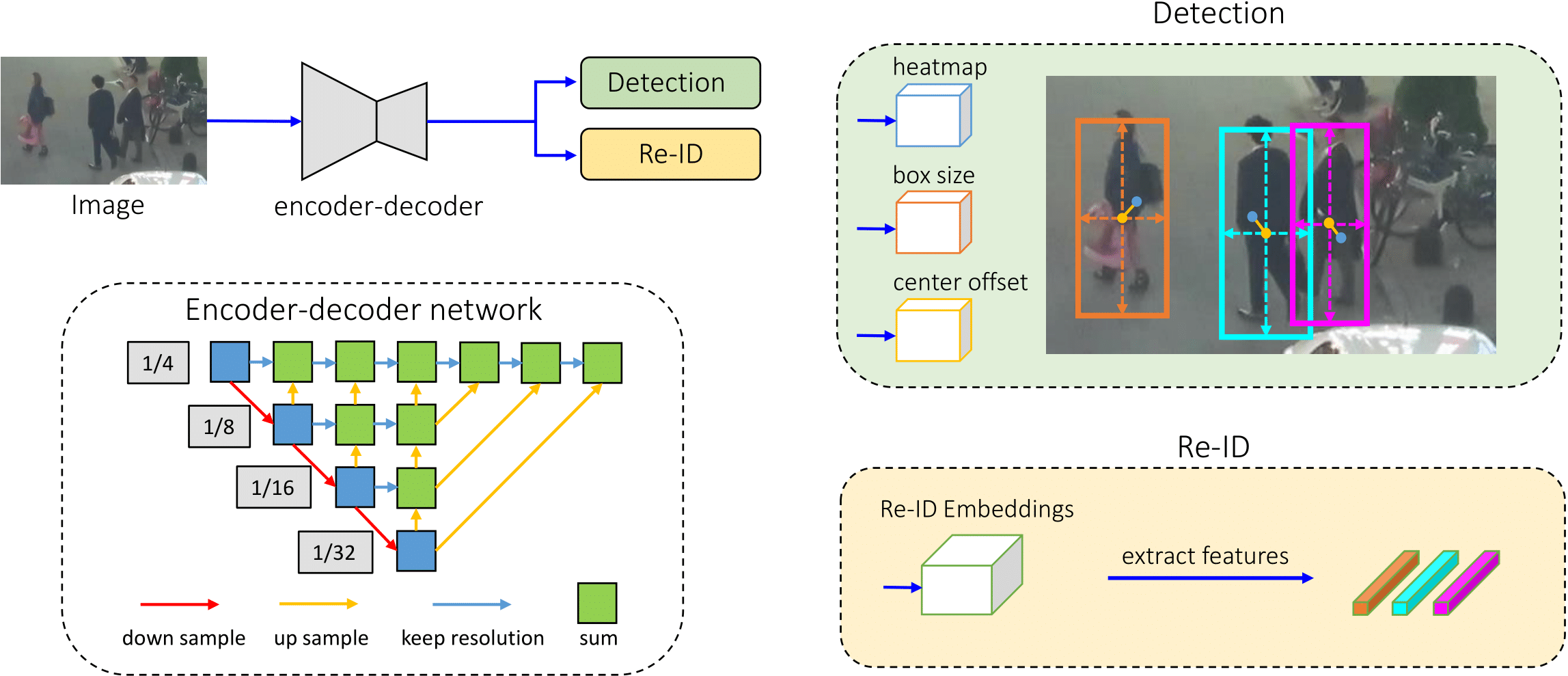
FairMOT
Paper: FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
Code: ifzhang/FairMOT
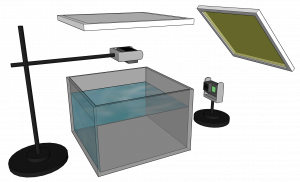
3D-ZeF
Paper: arxiv.org/abs/2006.08466
Code: mapeAAU/3D-ZeF

ByteTrack
Paper: ByteTrack: Multi-Object Tracking by Associating Every Detection Box
Code: https://github.com/ifzhang/ByteTrack


OC-SORT
Paper: Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking
Code: https://github.com/noahcao/OC_SORT

Deep OC-SORT
Paper: Deep OC-SORT: Multi-Pedestrian Tracking by Adaptive Re-Identification
Code: https://github.com/GerardMaggiolino/Deep-OC-SORT
Track Anything
Paper: Track Anything: Segment Anything Meets Videos
Cpde: https://github.com/gaomingqi/Track-Anything

YOLOv8 + DeepSORT
Code: https://github.com/MuhammadMoinFaisal/YOLOv8-DeepSORT-Object-Tracking
MeMOTR
Paper: MeMOTR: Long-Term Memory-Augmented Transformer for Multi-Object Tracking
Code: https://github.com/MCG-NJU/MeMOTR


Hybrid-SORT
Paper: Hybrid-SORT: Weak Cues Matter for Online Multi-Object Tracking
Code: https://github.com/ymzis69/HybridSORT

MOTIP
Paper: Multiple Object Tracking as ID Prediction
Code: https://github.com/MCG-NJU/MOTIP

LITE
Paper: LITE: A Paradigm Shift in Multi-Object Tracking with Efficient ReID Feature Integration
Code: https://github.com/Jumabek/LITE
The Lightweight Integrated Tracking-Feature Extraction (LITE) paradigm is introduced as a novel multi-object tracking (MOT) approach.

This site was last updated September 17, 2025.