Retrieval-Augmented Generation
Introduction to RAG, LlamaIndex, examples.
RAG

Retrieval-Augmented Generation
Paper: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
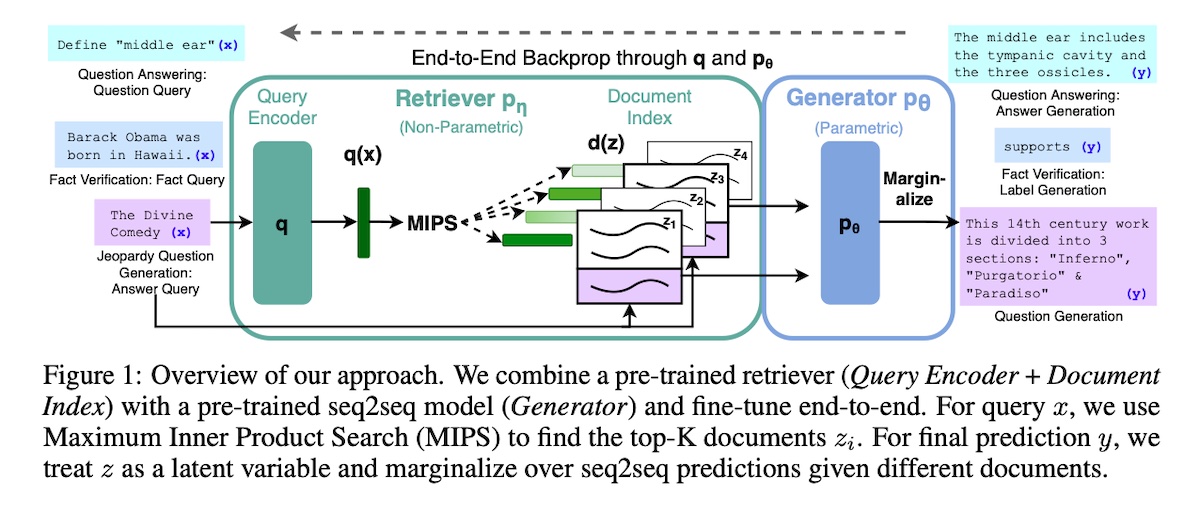
A Guide on 12 Tuning Strategies for Production-Ready RAG Applications
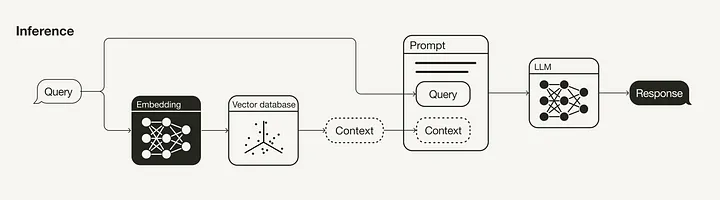
NLP • Retrieval Augmented Generation
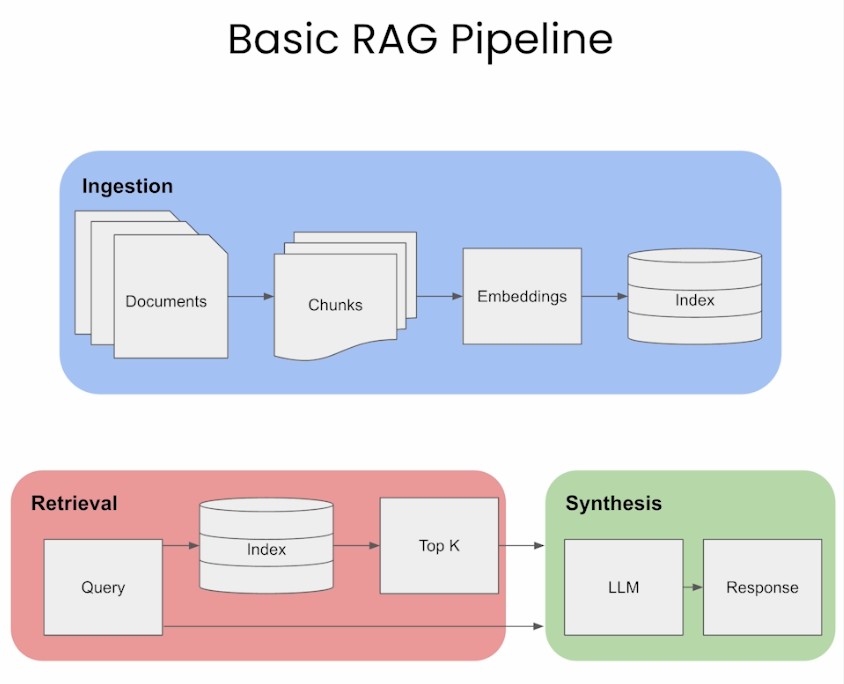
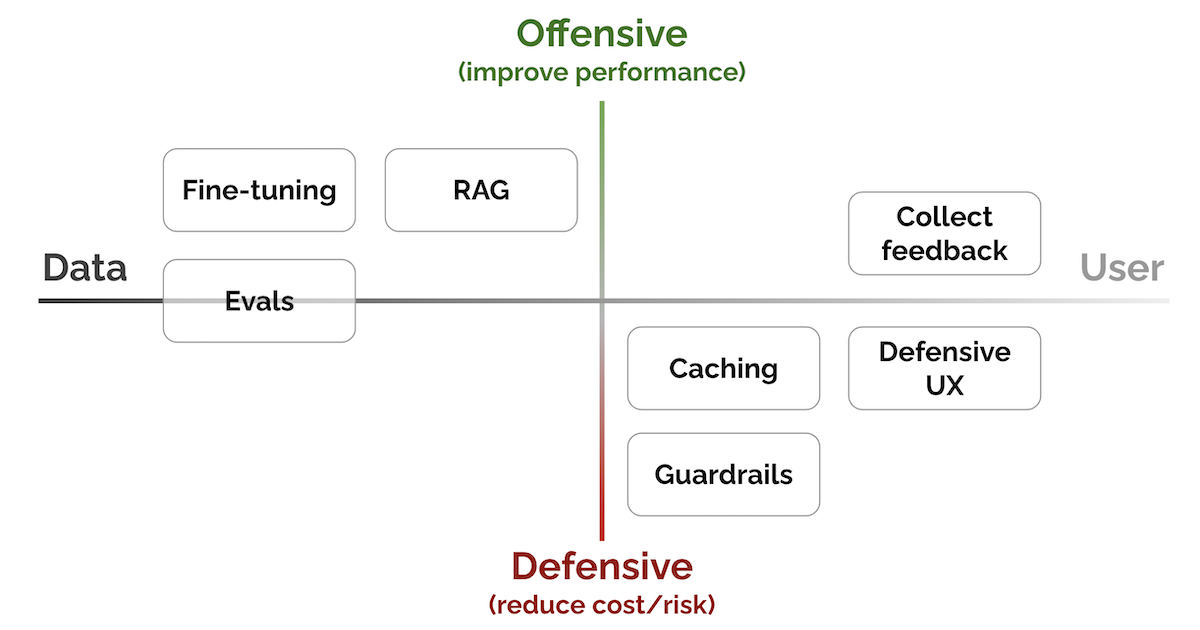
Patterns for Building LLM-based Systems & Products
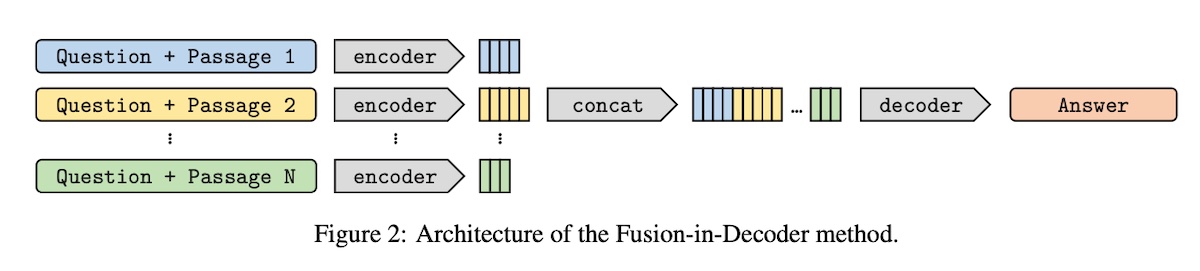
Fusion-in-Decoder (FiD)
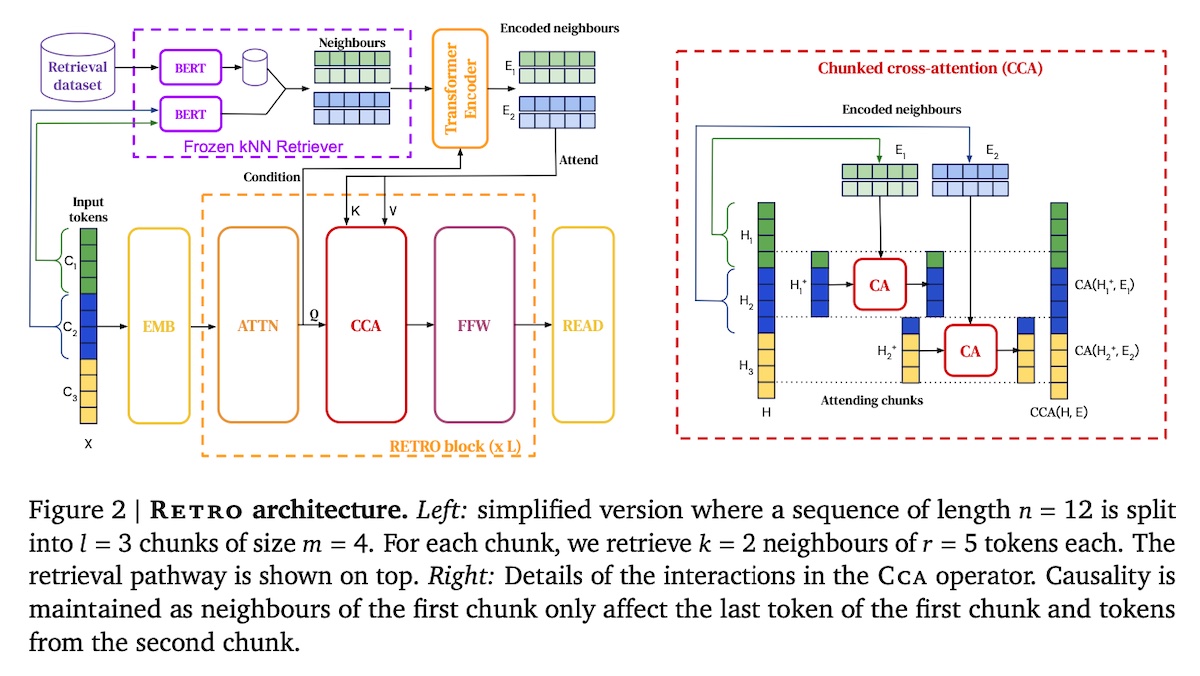
Retrieval-Enhanced Transformer (RETRO)
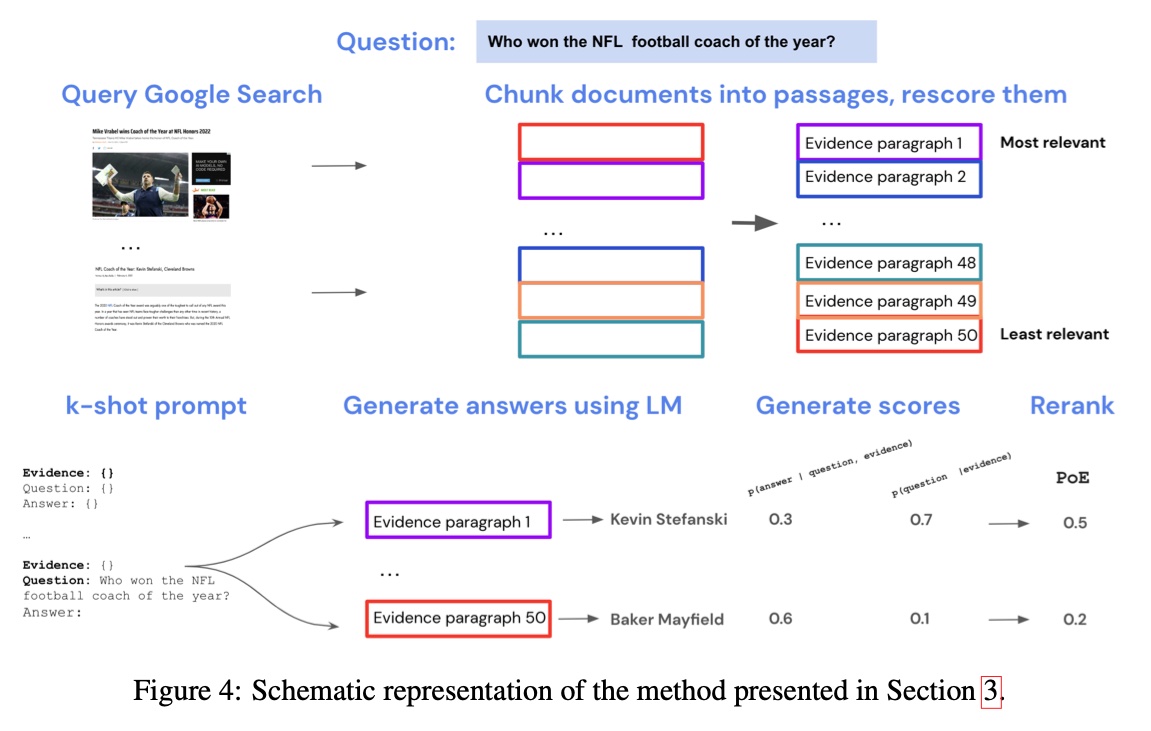
Internet-augmented LMs
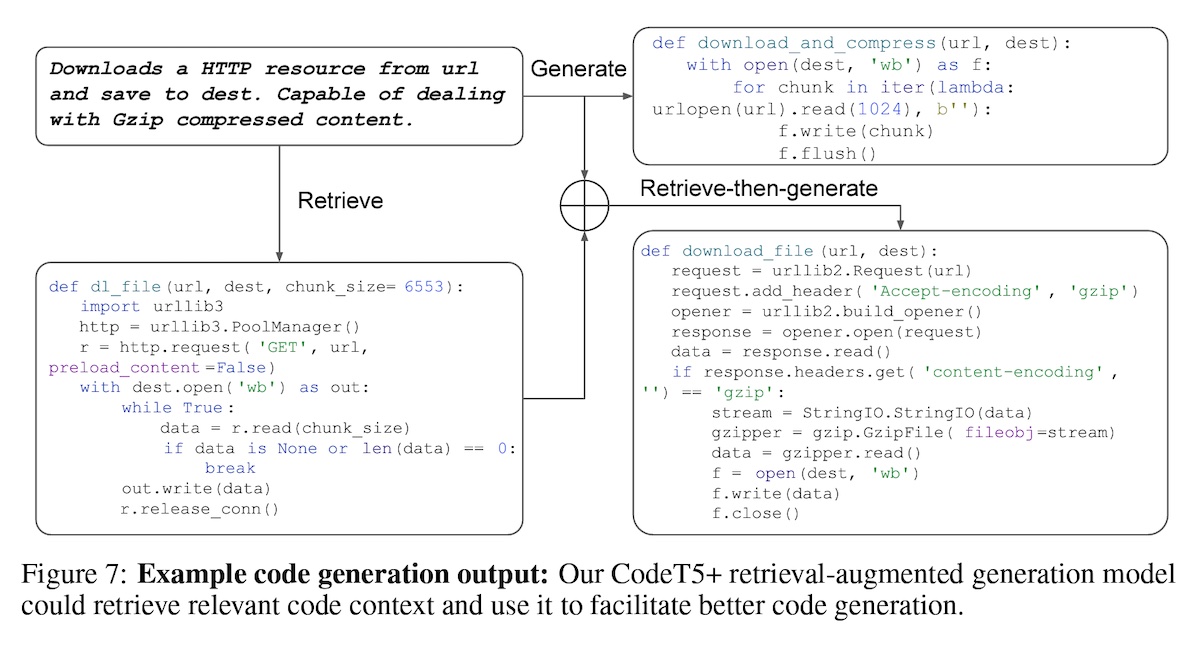
Overview of RAG for CodeT5+
Hypothetical document embeddings (HyDE)
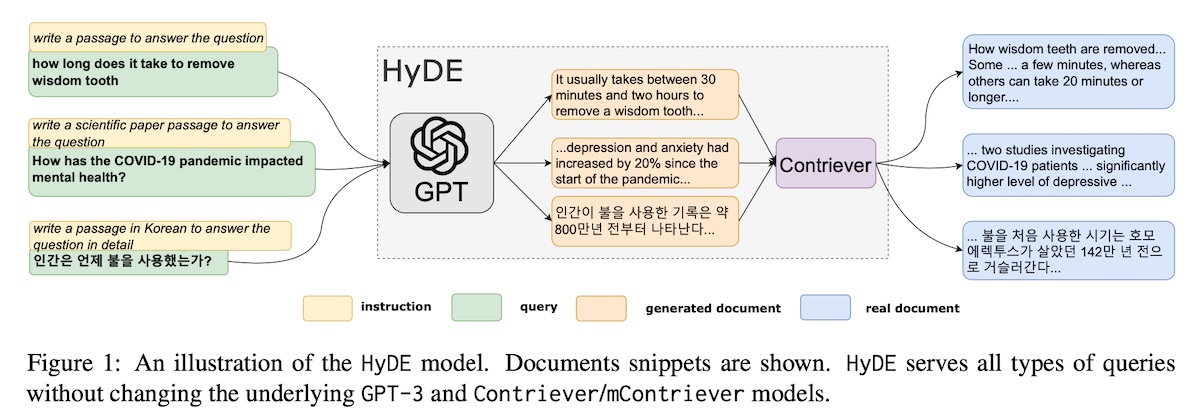
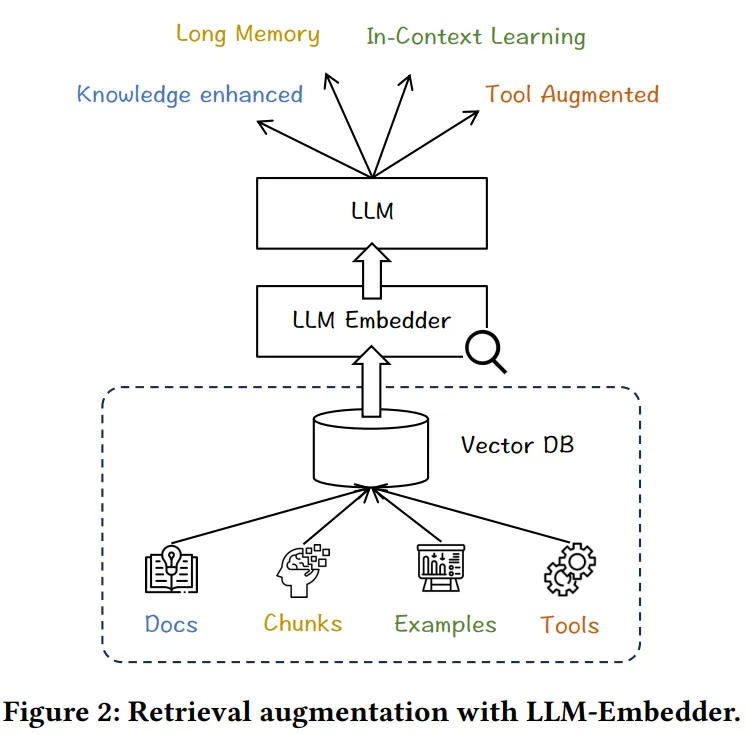
LLM Embedder
Paper: Retrieve Anything To Augment Large Language Models
Code: https://github.com/FlagOpen/FlagEmbedding
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-flagembedding

LM-Cocktail
Paper: LM-Cocktail: Resilient Tuning of Language Models via Model Merging
Code: https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail
EAGLE-LLM
3X faster for LLM
Blog: EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation
Code: https://github.com/SafeAILab/EAGLE
Kaggle: https://www.kaggle.com/code/rkuo2000/eagle-llm
Purple Llama CyberSecEval
Paper: Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models
Code: CybersecurityBenchmarks
meta-llama/LlamaGuard-7b
| Our Test Set (Prompt) | OpenAI Mod | ToxicChat | Our Test Set (Response) | |
|---|---|---|---|---|
| Llama-Guard | 0.945 | 0.847 | 0.626 | 0.953 |
| OpenAI API | 0.764 | 0.856 | 0.588 | 0.769 |
| Perspective API | 0.728 | 0.787 | 0.532 | 0.699 |
GraphRAG
Paper: From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Blog: 從 RAG 到 GraphRAG:透過圖譜節點關係增強回應精確度
Blog: GraphRAG: Unlocking LLM discovery on narrative private data
HippoRAG
Paper: HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
Code: https://github.com/OSU-NLP-Group/HippoRAG

Frameworks
LlamaIndex
Code: https://github.com/run-llama/llama_index
Docs:
import os
os.environ["REPLICATE_API_TOKEN"] = "YOUR_REPLICATE_API_TOKEN"
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.replicate import Replicate
from transformers import AutoTokenizer
# set the LLM
llama2_7b_chat = "meta/llama-2-7b-chat:8e6975e5ed6174911a6ff3d60540dfd4844201974602551e10e9e87ab143d81e"
Settings.llm = Replicate(
model=llama2_7b_chat,
temperature=0.01,
additional_kwargs={"top_p": 1, "max_new_tokens": 300},
)
# set tokenizer to match LLM
Settings.tokenizer = AutoTokenizer.from_pretrained(
"NousResearch/Llama-2-7b-chat-hf"
)
# set the embed model
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(
documents,
)
query_engine = index.as_query_engine()
query_engine.query("YOUR_QUESTION")
By default, data is stored in-memory. To persist to disk (under ./storage):
index.storage_context.persist()
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-llamaindex
Applications
RAG using LlamaIndex framework to build a simple chatbot, to Q&A a bunch of documents

RAG with MATLAB

Building RAG-based LLM Applications for Production
https://github.com/ray-project/llm-applications/blob/main/notebooks/rag.ipynb
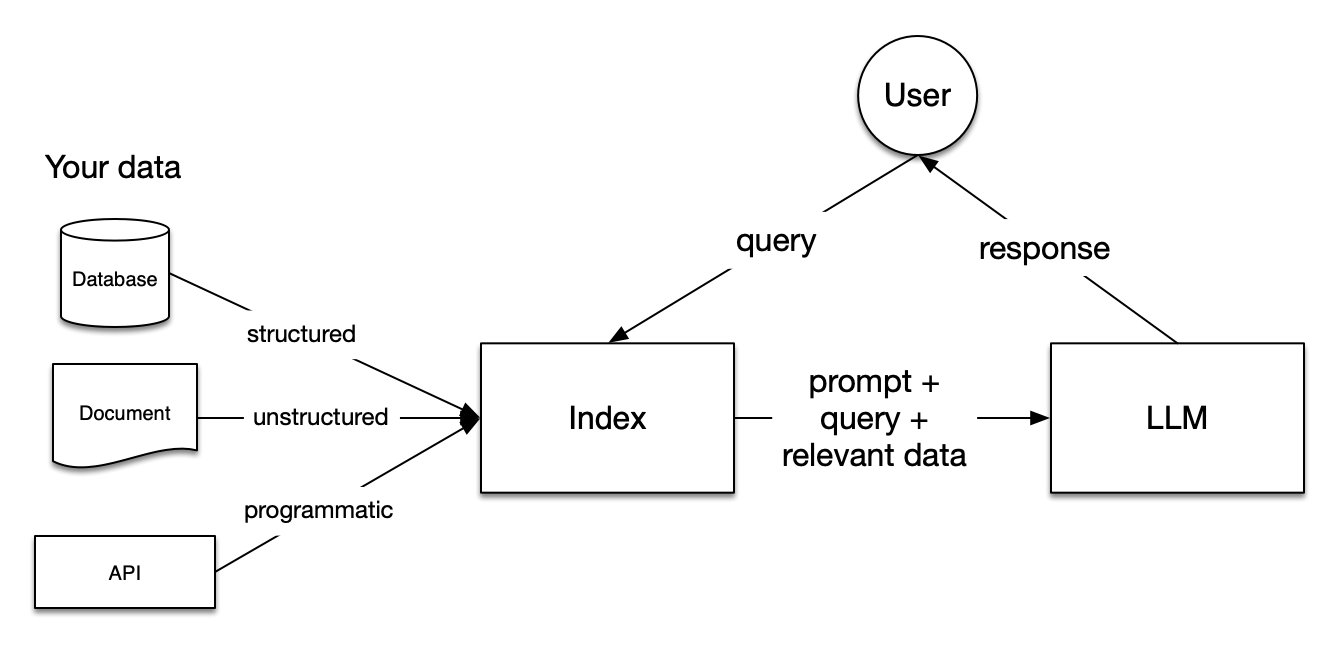
(1)將外部文件做分塊(chunking)再分詞(tokenize)轉成token
(2)利用嵌入模型,將token做嵌入(embeds)運算,轉成向量,儲存至向量資料庫(Vector Database)並索引(Indexes)
(3)用戶提出問題,向量資料庫將問題字串轉成向量(利用前一個步驟的嵌入模型),再透過餘弦(Cosine)相似度或歐氏距離演算法來搜尋資料庫裡的近似資料
(4)將用戶的問題、資料庫查詢結果一起放進Prompt(提示),交由LLM推理出最終答案
以上是基本的RAG流程,利用Langchain或LlamaIndex或Haystack之類的應用程式開發框架,大概用不到一百行的程式碼就能做掉(含LLM的裝載)。
Anyscale剛剛發布的一篇精彩好文,裡頭介紹了很多提升RAG成效的高段技巧,內容包括:
🚀從頭開始建構基於RAG的LLM應用程式。
🚀 在具有不同運算資源的多個工作人員之間擴展主要工作負載(載入、分塊、嵌入、索引、服務等)。
🚀評估應用程式的不同配置,以最佳化每個元件(例如retrieval_score)和整體效能(quality_score)。
🚀 透過開源和閉源LLM實作混合代理路由方法,以建立效能最佳且最具成本效益的應用程式。
🚀以高擴展性與高可用性的方式為應用程式提供服務。
🚀了解微調、提示工程、詞彙搜尋(lexical search)、重新排名、資料飛輪(data flywheel)等方法如何影響應用程式的效能。
This site was last updated June 29, 2024.