Large Language Models
Introduction to LLMs, Deep LLM, Time-series LLMs, Applications, etc.
History of LLMs
A Survey of Large Language Models
Since the introduction of Transformer model in 2017, large language models (LLMs) have evolved significantly.
ChatGPT saw 1.6B visits in May 2023.
Meta also released three versions of LLaMA-2 (7B, 13B, 70B) free for commercial use in July.
大型語言模型(>10B)的時間軸

計算記憶體的成長與Transformer大小的關係
Large Language Models
Open LLM Leaderboard
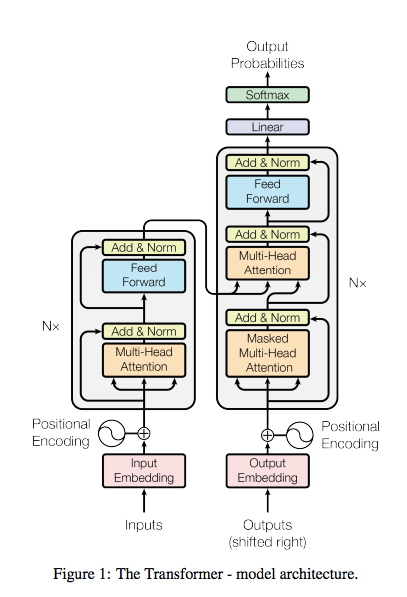
Transformer
Paper: Attention Is All You Need
ChatGPT
ChatGPT: Optimizing Language Models for Dialogue
ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.

GPT4
Paper: GPT-4 Technical Report
 Paper: From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
Paper: From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
Blog: GPT-4 Code Interpreter: The Next Big Thing in AI
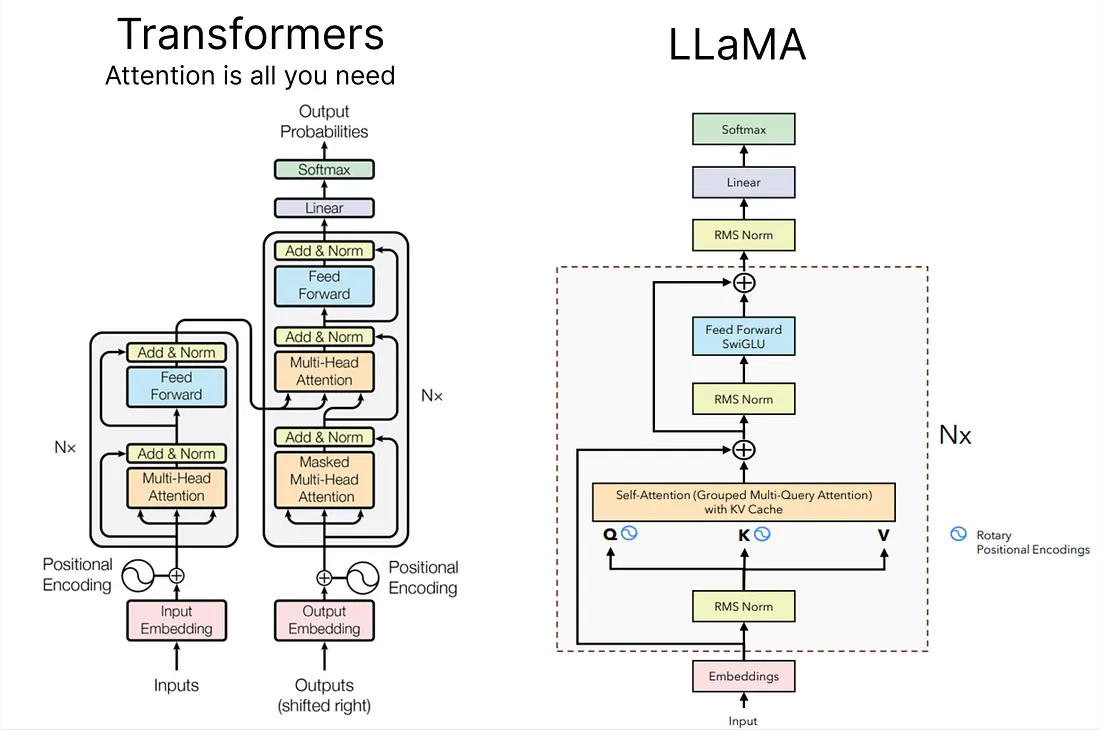
LLaMA
Paper: LLaMA: Open and Efficient Foundation Language Models
 Blog: Building a Million-Parameter LLM from Scratch Using Python
Blog: Building a Million-Parameter LLM from Scratch Using Python
Kaggle: LLM LLaMA from scratch
BloombergGPT
Paper: BloombergGPT: A Large Language Model for Finance
Blog: Introducing BloombergGPT, Bloomberg’s 50-billion parameter large language model, purpose-built from scratch for finance
Pythia
Paper: Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Dataset:
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Datasheet for the Pile
Code: Pythia: Interpreting Transformers Across Time and Scale
MPT-7B
model: mosaicml/mpt-7b-chat
Code: https://github.com/mosaicml/llm-foundry
Blog: Announcing MPT-7B-8K: 8K Context Length for Document Understanding
Blog: Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs
Falcon-40B
model: tiiuae/falcon-40b
Paper: The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
Orca
Paper: Orca: Progressive Learning from Complex Explanation Traces of GPT-4
OpenLLaMA
model: openlm-research/open_llama_3b_v2
model: openlm-research/open_llama_7b_v2
Code: https://github.com/openlm-research/open_llama
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-openllama
Vicuna
model: lmsys/vicuna-7b-v1.5
Paper: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Code: https://github.com/lm-sys/FastChat
LLaMA-2
model: meta-llama/Llama-2-7b-chat-hf
Paper: Llama 2: Open Foundation and Fine-Tuned Chat Models
Code: https://github.com/facebookresearch/llama
Sheared LLaMA
model_name = “princeton-nlp/Sheared-LLaMA-1.3B”, princeton-nlp/Sheared-LLaMA-2.7B | princeton-nlp/Sheared-Pythia-160m
Paper: Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Code: https://github.com/princeton-nlp/LLM-Shearing
Neural-Chat-7B (Intel)
model_name = “Intel/neural-chat-7b-v3-1”
Blog: Intel neural-chat-7b Model Achieves Top Ranking on LLM Leaderboard!
Mistral
model_name = “mistralai/Mistral-7B-Instruct-v0.2”
Paper: Mistral 7B
Code: https://github.com/mistralai/mistral-src
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-mistral-7b-instruct

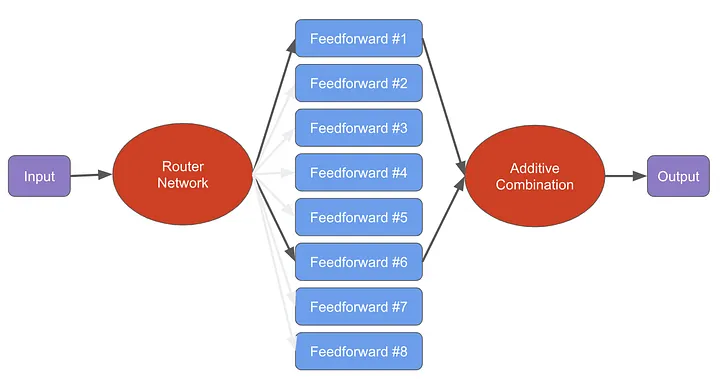
Mistral 8X7B
model: mistralai/Mixtral-8x7B-v0.1
Paper: Mixtral of Experts
Starling-LM
model: Nexusflow/Starling-LM-7B-beta
Paper: RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Blog: Starling-7B: Increasing LLM Helpfulness & Harmlessness with RLAIF

Zephyr
model: HuggingFaceH4/zephyr-7b-beta
Paper: Zephyr: Direct Distillation of LM Alignment
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-zephyr-7b
 Blog: Zephyr-7B : HuggingFace’s Hyper-Optimized LLM Built on Top of Mistral 7B
Blog: Zephyr-7B : HuggingFace’s Hyper-Optimized LLM Built on Top of Mistral 7B

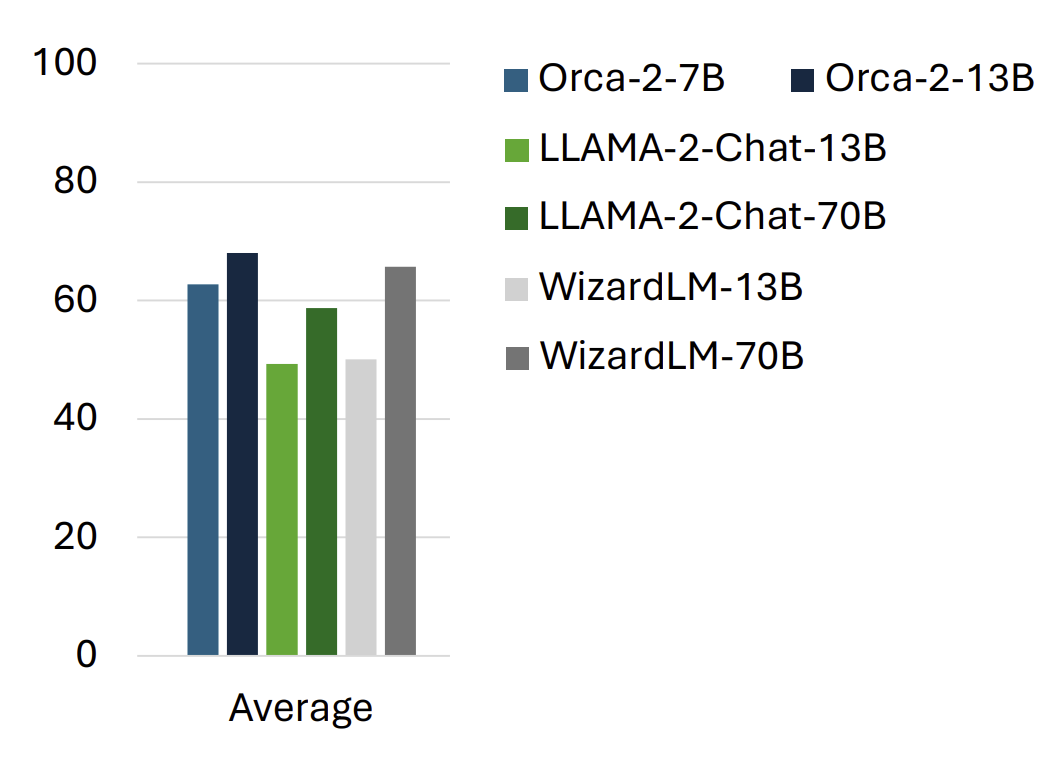
Orca 2
model: microsoft/Orca-2-7b
Paper: https://arxiv.org/abs/2311.11045
Blog: Microsoft’s Orca 2 LLM Outperforms Models That Are 10x Larger
BlueLM (VIVO)
model: vivo-ai/BlueLM-7B-Chat-4bits
Code: https://github.com/vivo-ai-lab/BlueLM/
Taiwan-LLM (優必達+台大)
model: yentinglin/Taiwan-LLM-7B-v2.1-chat
Paper: TAIWAN-LLM: Bridging the Linguistic Divide with a Culturally Aligned Language Model
Blog: 專屬台灣!優必達攜手台大打造「Taiwan LLM」,為何我們需要本土化的AI?
Code: https://github.com/MiuLab/Taiwan-LLM
Phi-2 (Transformer with 2.7B parameters)
model: microsoft/phi-2
Blog: Phi-2: The surprising power of small language models
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-phi-2
Mamba
model: Q-bert/Mamba-130M
Paper: Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-mamba-130m
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-mamba-3b

SOLAR-10.7B ~ Depth Upscaling
Paper: SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Code: https://huggingface.co/upstage/SOLAR-10.7B-v1.0
Depth-Upscaled SOLAR-10.7B has remarkable performance. It outperforms models with up to 30B parameters, even surpassing the recent Mixtral 8X7B model.
Leveraging state-of-the-art instruction fine-tuning methods, including supervised fine-tuning (SFT) and direct preference optimization (DPO),
researchers utilized a diverse set of datasets for training. This fine-tuned model, SOLAR-10.7B-Instruct-v1.0, achieves a remarkable Model H6 score of 74.20,
boasting its effectiveness in single-turn dialogue scenarios.
Qwen (通义千问)
model: Qwen/Qwen1.5-7B-Chat
Blog: Introducing Qwen1.5
Code: https://github.com/QwenLM/Qwen1.5
Kaggle: https://www.kaggle.com/code/rkuo2000/llm-qwen1-5

Yi (零一万物)
model: 01-ai/Yi-6B-Chat
Paper: CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Paper: Yi: Open Foundation Models by 01.AI
Orca-Math
Paper: Orca-Math: Unlocking the potential of SLMs in Grade School Math
Dataset: https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k
Breeze (達哥)
model: MediaTek-Research/Breeze-7B-Instruct-v0_1
Paper: Breeze-7B Technical Report
Blog: Breeze-7B: 透過 Mistral-7B Fine-Tune 出來的繁中開源模型
Bialong (白龍)
Bilingual transfer learning based on QLoRA and zip-tie embedding
model: INX-TEXT/Bailong-instruct-7B
TAIDE
model: taide/TAIDE-LX-7B-Chat
- TAIDE-LX-7B: 以 LLaMA2-7b 為基礎,僅使用繁體中文資料預訓練 (continuous pretraining)的模型,適合使用者會對模型進一步微調(fine tune)的使用情境。因預訓練模型沒有經過微調和偏好對齊,可能會產生惡意或不安全的輸出,使用時請小心。
- TAIDE-LX-7B-Chat: 以 TAIDE-LX-7B 為基礎,透過指令微調(instruction tuning)強化辦公室常用任務和多輪問答對話能力,適合聊天對話或任務協助的使用情境。TAIDE-LX-7B-Chat另外有提供4 bit 量化模型,量化模型主要是提供使用者的便利性,可能會影響效能與更多不可預期的問題,還請使用者理解與注意。
Gemma
model: google/gemma-1.1-7b-it
Blog: Gemma: Introducing new state-of-the-art open models
Kaggle: https://www.kaggle.com/code/nilaychauhan/fine-tune-gemma-models-in-keras-using-lora
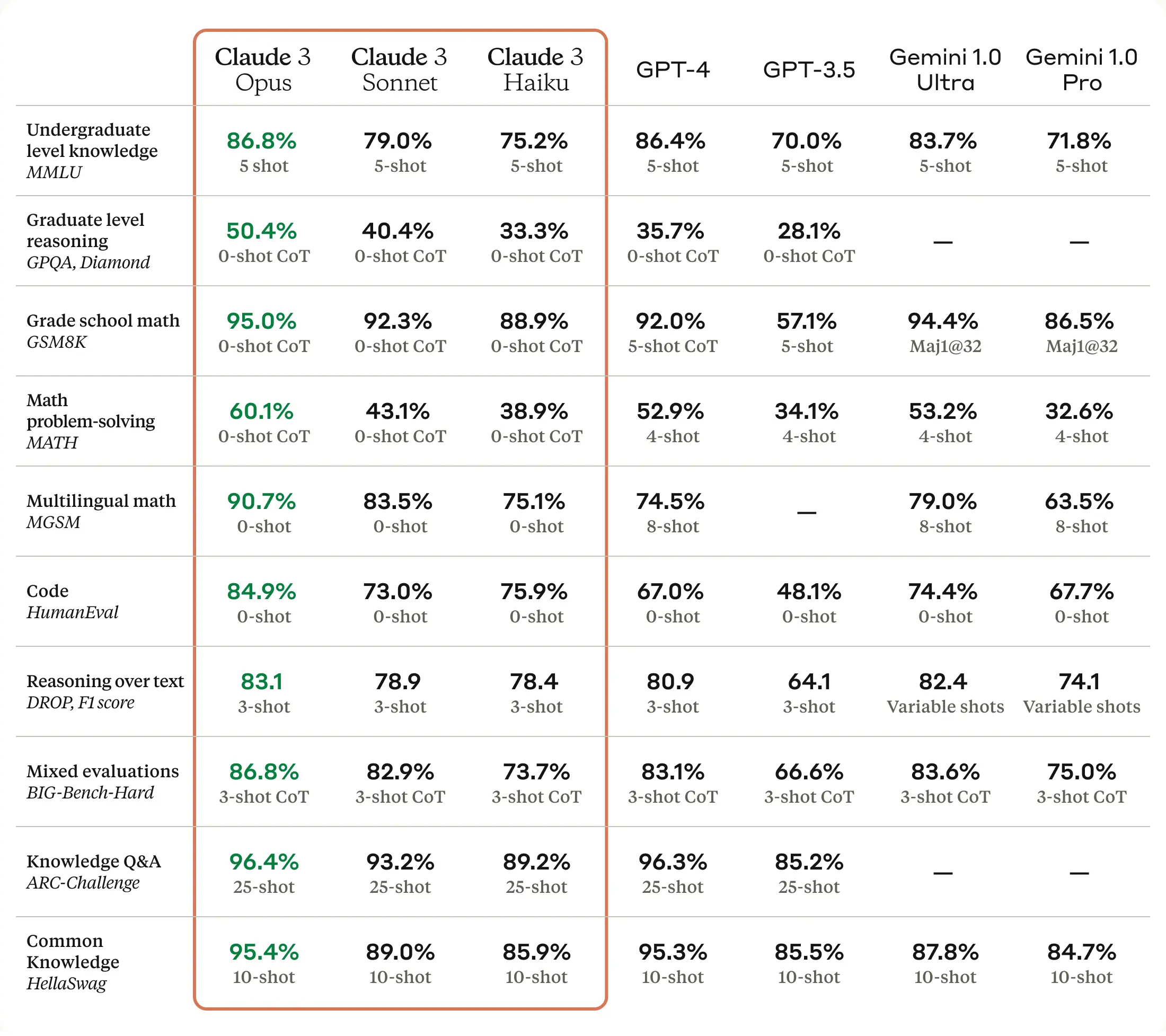
Claude 3
Introducing the next generation of Claude
InflectionAI
Blog: Inflection AI 發表新基礎模型「Inflection-2.5 」,能力逼近 GPT-4!
Phind-70B
Blog: Introducing Phind-70B – closing the code quality gap with GPT-4 Turbo while running 4x faster
Blog: Phind - 給工程師的智慧搜尋引擎
Phind-70B is significantly faster than GPT-4 Turbo, running at 80+ tokens per second to GPT-4 Turbo’s ~20 tokens per second. We’re able to achieve this by running NVIDIA’s TensorRT-LLM library on H100 GPUs, and we’re working on optimizations to further increase Phind-70B’s inference speed.
LlaMA-3
model: meta-llama/Meta-Llama-3-8B-Instruct
Code: https://github.com/meta-llama/llama3/

Phi-3
model: microsoft/Phi-3-mini-4k-instruct”
Blog: Introducing Phi-3: Redefining what’s possible with SLMs
Octopus v4
model: NexaAIDev/Octopus-v4
Paper: Octopus v4: Graph of language models
Code: https://github.com/NexaAI/octopus-v4
design demo
LLM running locally
ollama
ollama -v
ollama
ollama pull llava
ollama run llava
PrivateGPT
Code: https://github.com/zylon-ai/private-gpt

LM Studio

GPT4All
chmod +x gpt4all-installer-linux.run
./gpt4all-installer-linux.run
cd ~/gpt4all
./bin/chat
GPT4FREE
pip install g4f
Deep LLM
Deep Language Networks
Paper: Joint Prompt Optimization of Stacked LLMs using Variational Inference
Code: https://github.com/microsoft/deep-language-networks

Constitutional AI
Paper: Constitutional AI: Harmlessness from AI Feedback
Two key phases:
- Supervised Learning Phase (SL Phase)
- Step1: The learning starts using the samples from the initial model
- Step2: From these samples, the model generates self-critiques and revisions
- Step3: Fine-tine the original model with these revisions
- Reinforcement Learning Phase (RL Phease)
- Step1. The model uses samples from the fine-tuned model.
- Step2. Use a model to compare the outputs from samples from the initial model and the fine-tuned model
- Step3. Decide which sample is better. (RLHF)
- Step4. Train a new “preference model” from the new dataset of AI preferences. This new “prefernece model” will then be used to re-train the RL (as a reward signal). It is now the RLHAF (Reinforcement Learning from AI feedback)
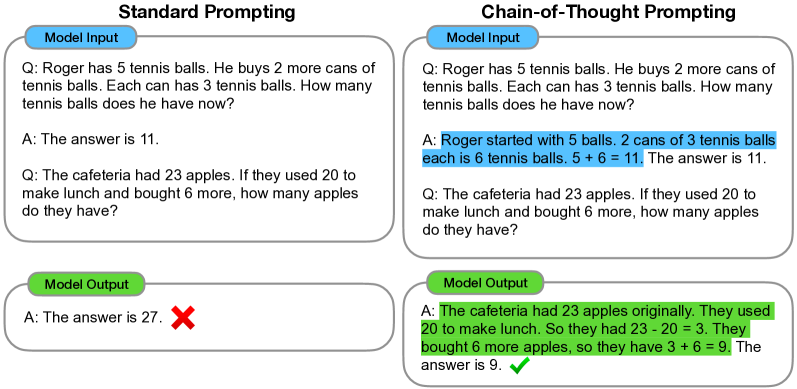
Chain-of-Thought Prompting
Paper: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
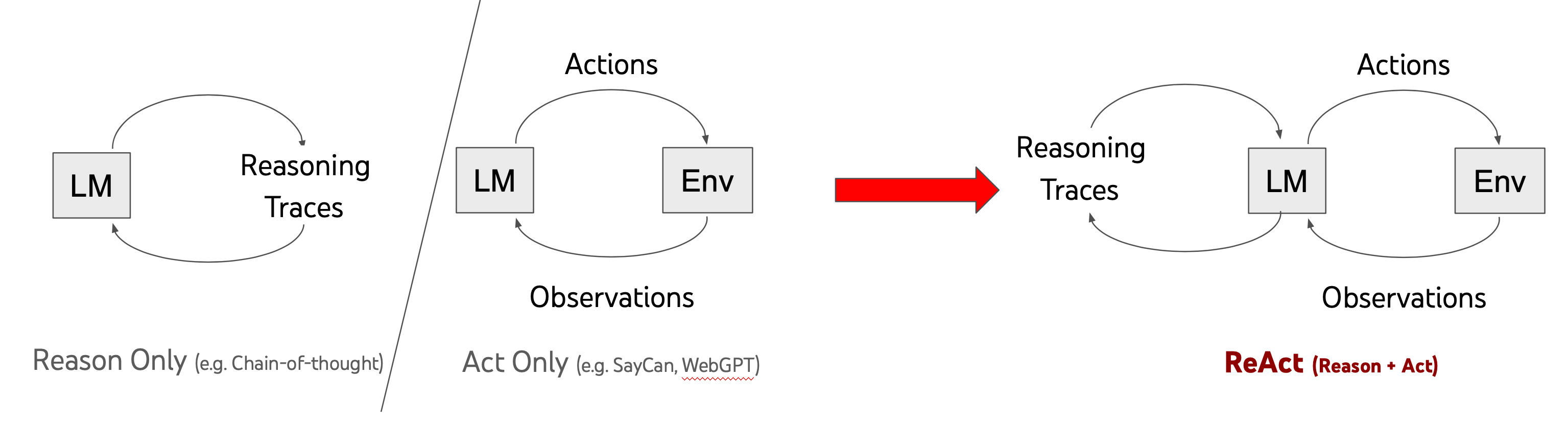
ReAct Prompting
Paper: ReAct: Synergizing Reasoning and Acting in Language Models
Code: https://github.com/ysymyth/ReAct
Tree-of-Thoughts
Paper: Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Code: https://github.com/princeton-nlp/tree-of-thought-llm
Code: https://github.com/kyegomez/tree-of-thoughts

Tabular CoT
Paper: Tab-CoT: Zero-shot Tabular Chain of Thought
Code: https://github.com/Xalp/Tab-CoT

Survey of Chain-of-Thought
Paper: A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future
Chain-of-Thought Hub
Paper: Chain-of-Thought Hub: A Continuous Effort to Measure Large Language Models’ Reasoning Performance
Code: https://github.com/FranxYao/chain-of-thought-hub
Everything-of-Thoughts
Paper: Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
Code: https://github.com/microsoft/Everything-of-Thoughts-XoT

R3
Paper: Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
Code: https://github.com/WooooDyy/LLM-Reverse-Curriculum-RL

Time-series LLM
Paper: Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook
**Papers: https://github.com/DaoSword/Time-Series-Forecasting-and-Deep-Learning
Time-LLM
Paper: Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Code: https://github.com/KimMeen/Time-LLM


Time-LLM
Paper: Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Code: https://github.com/KimMeen/Time-LLM
TimeGPT-1
Paper: TimeGPT-1
TEMPO
Paper: TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
Code: https://github.com/liaoyuhua/tempo-pytorch

Lag-LLaMA
Paper: Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting
Blog: From RNN/LSTM to Temporal Fusion Transformers and Lag-Llama
Code: https://github.com/time-series-foundation-models/lag-llama
Colab:
Timer
Paper: Timer: Transformers for Time Series Analysis at Scale
Applications
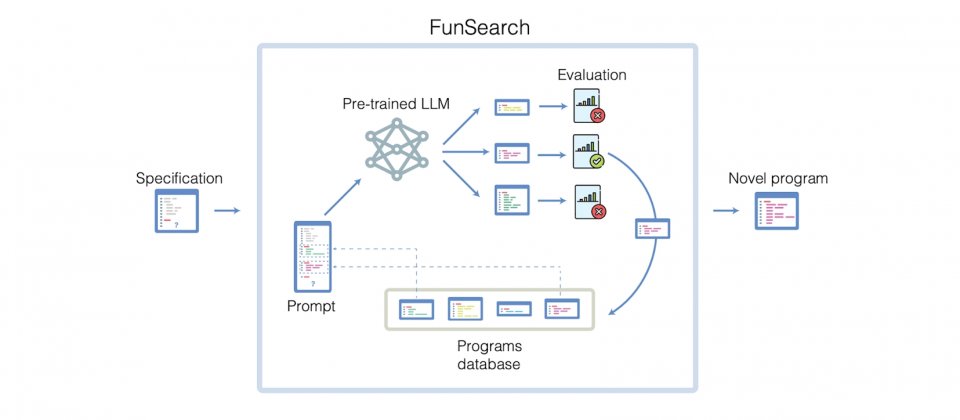
FunSearch
Automatic Evaluation
Paper: Can Large Language Models Be an Alternative to Human Evaluation?

Paper: A Closer Look into Automatic Evaluation Using Large Language Models
Code: https://github.com/d223302/A-Closer-Look-To-LLM-Evaluation
BrainGPT
Paper: DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation
Blog: New Mind-Reading “BrainGPT” Turns Thoughts Into Text On Screen


Designing Silicon Brains using LLM

MyGirlGPT
Code: https://github.com/Synthintel0/MyGirlGPT
Robotic Manipulation
Paper: Language-conditioned Learning for Robotic Manipulation: A Survey
Paper: Human Demonstrations are Generalizable Knowledge for Robots
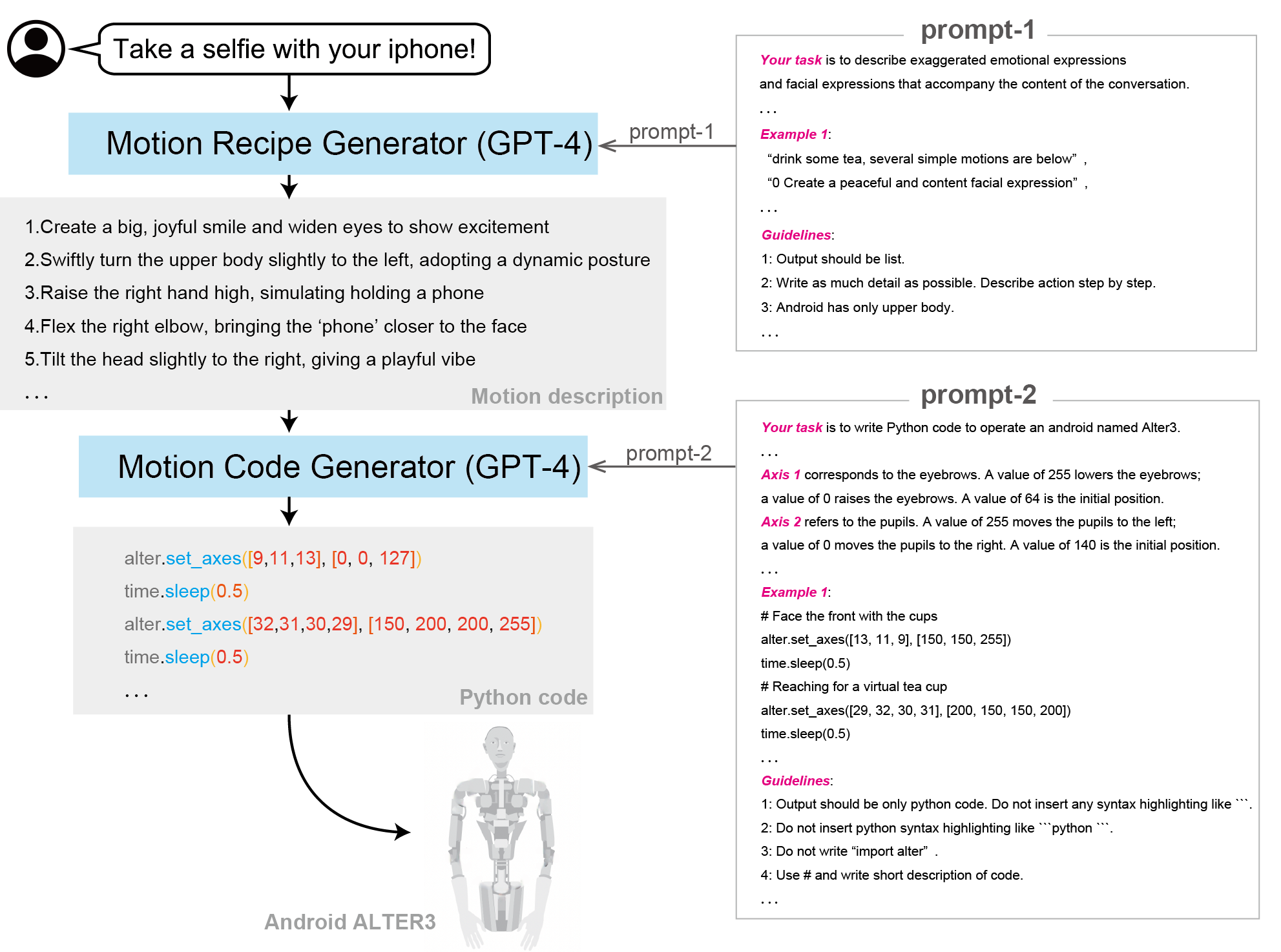
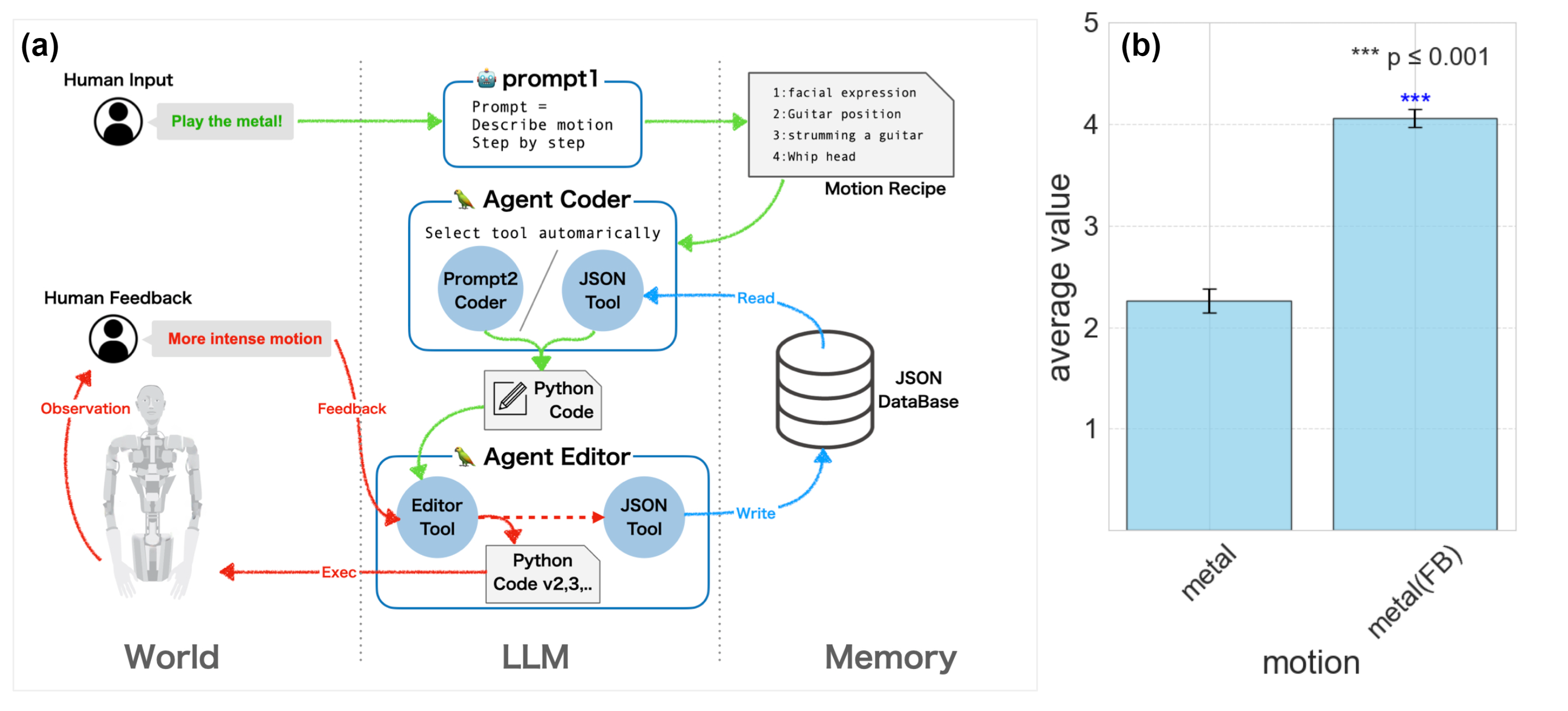
ALTER-LLM
Paper: From Text to Motion: Grounding GPT-4 in a Humanoid Robot “Alter3”
This site was last updated June 29, 2024.