Speech Processing
This introduction includes Speech Datasets, Text-To-Speech, Speech Seperation, Voice Clonging, NVIDIA NeMo etc.
Text-To-Speech (using TTS)
WaveNet
Paper: WaveNet: A Generative Model for Raw Audio
Code: r9y9/wavenet_vocoder
With a pre-trained model provided here, you can synthesize waveform given a mel spectrogram, not raw text.
You will need mel-spectrogram prediction model (such as Tacotron2) to use the pre-trained models for TTS.
Demo: An open source implementation of WaveNet vocoder
Blog: WaveNet: A generative model for raw audio

Tacotron-2
Paper: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Code: Rayhane-mamah/Tacotron-2
Code: Tacotron 2 (without wavenet)

Forward Tacotron
Blog: 利用 ForwardTacotron 創造穩健的神經語言合成
Code: https://github.com/as-ideas/ForwardTacotron

Few-shot Transformer TTS
Paper: Multilingual Byte2Speech Models for Scalable Low-resource Speech Synthesis
Code: https://github.com/mutiann/few-shot-transformer-tts
MetaAudio
Paper: MetaAudio: A Few-Shot Audio Classification Benchmark
Code: MetaAudio-A-Few-Shot-Audio-Classification-Benchmark
Dataset: ESC-50, NSynth, FSDKaggle18, BirdClef2020, VoxCeleb1
SeamlessM4T
Paper: SeamlessM4T: Massively Multilingual & Multimodal Machine Translation
Code: https://github.com/facebookresearch/seamless_communication
Colab: seamless_m4t_colab
app.py
Audiobox
Paper: Audiobox: Generating audio from voice and natural language prompts
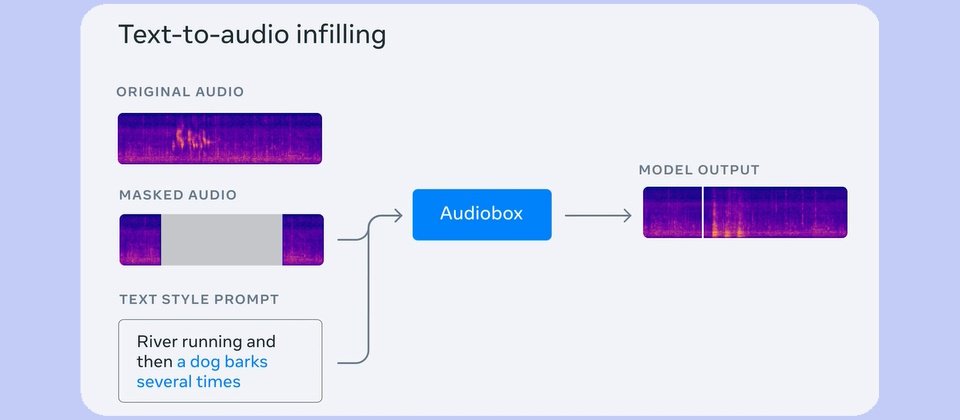
coqui TTS
Code: https://www.kaggle.com/code/rkuo2000/coqui-tts
Kaggle: https://www.kaggle.com/code/rkuo2000/coqui-tts
Speech Seperation
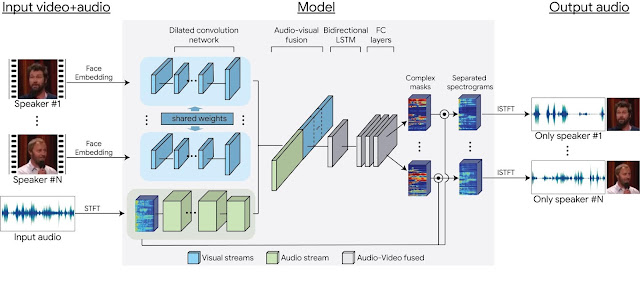
Looking to Listen
Paper: Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
Blog: Looking to Listen: Audio-Visual Speech Separation
VoiceFilter
Paper: VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Code: mindslab-ai/voicefilter
Training took about 20 hours on AWS p3.2xlarge(NVIDIA V100)
Code: jain-abhinav02/VoiceFilter
The model was trained on Google Colab for 30 epochs. Training took about 37 hours on NVIDIA Tesla P100 GPU.

VoiceFilter-Lite
Paper: VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Blog:
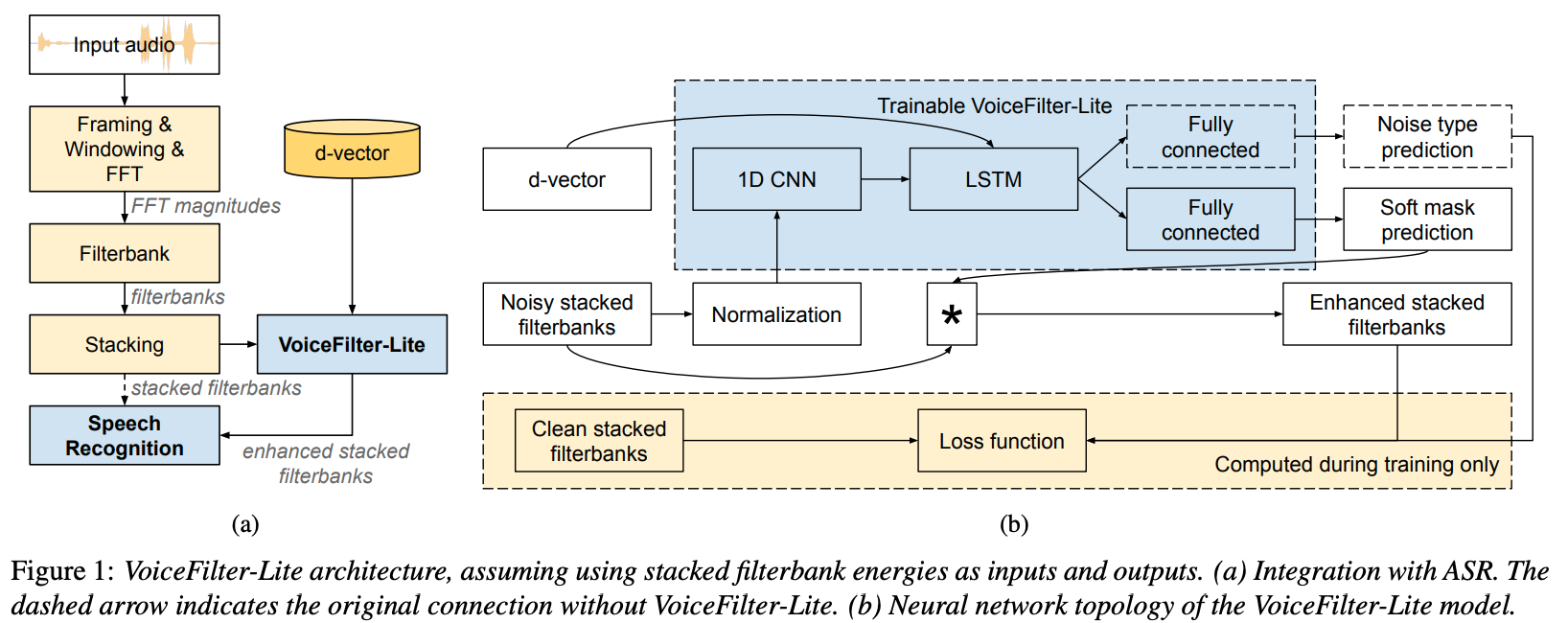
Voice Filter
Voice Conversion
Review of Deep Learning Voice Conversion
Paper: Overview of Voice Conversion Methods Based on Deep Learning
Paper: Reimagining Speech: A Scoping Review of Deep Learning-Powered Voice Conversion
Voice Cloning
Paper: Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Kaggle: https://github.com/CorentinJ/Real-Time-Voice-Cloning
Personalized Lightweight TTS
Paper: Personalized Lightweight Text-to-Speech: Voice Cloning with Adaptive Structured Pruning
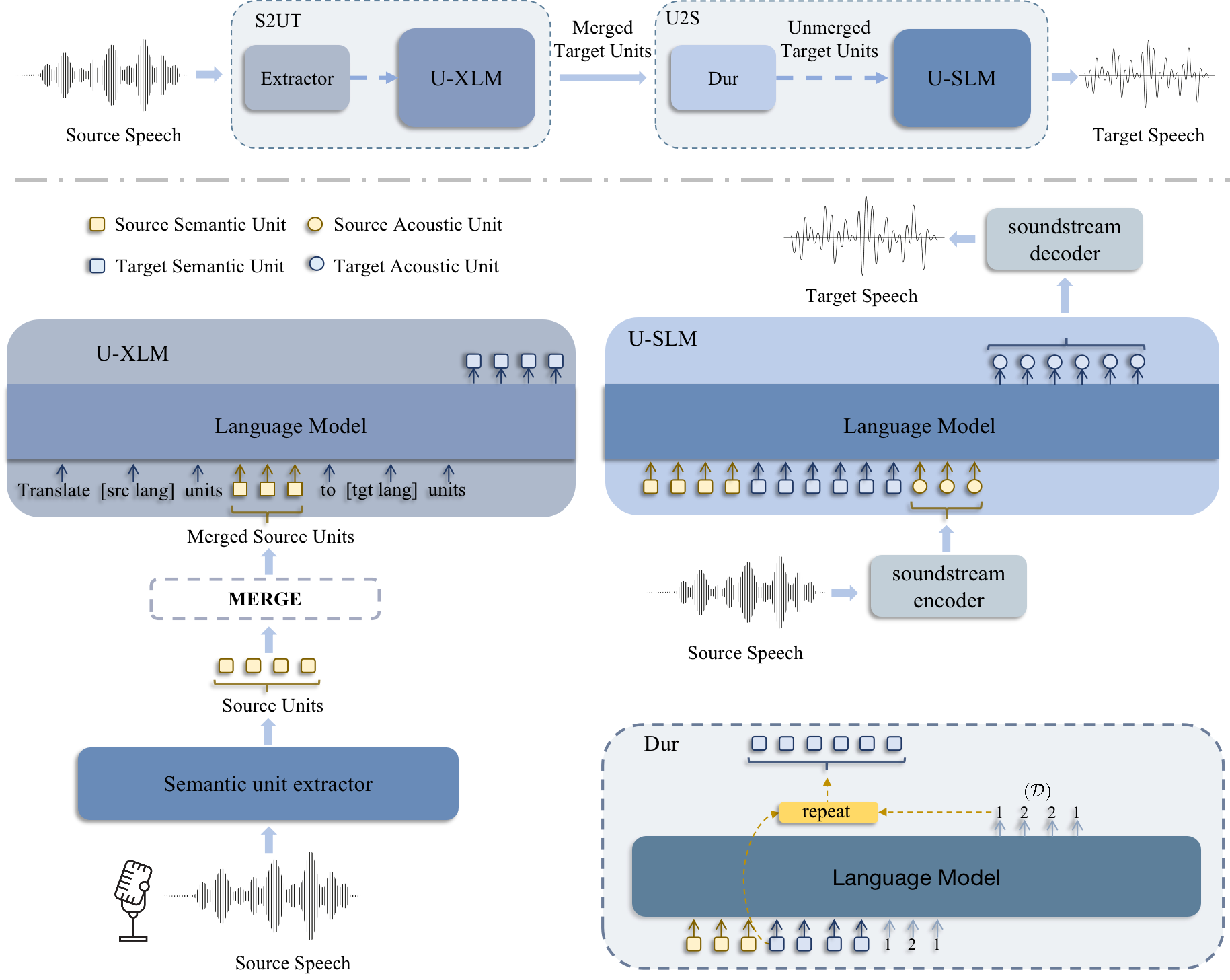
PolyVoice
Paper:PolyVoice: Language Models for Speech to Speech Translation
PolyVoice 是一种基于语言模型的 S2ST 框架,能够处理书写和非书写语言。
PolyVoice 使用通过自监督训练方法获得的离散单元作为源语音和目标语音之间的中间表示。PolyVoice 由两部分组成:
Speech-to-Unit(S2UT)翻译模块,将源语言语音的离散单元转换为目标语言语音的离散单元;
Unit-to-Speech(U2S)合成模块, 在保留源语言语音说话人风格的同时合成目标语言语音。
NeMO
Nemo ASR
Automatic Speech Recognition (ASR)
Speech Synthesis
This site was last updated June 29, 2024.